 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-informed Multiple-Input Operators for efficient dynamic response prediction of structures
May 11, 2025Finite element (FE) modeling is essential for structural analysis but remains computationally intensive, especially under dynamic loading. While operator learning models have shown promise in replicating static structural responses at FEM level accuracy, modeling dynamic behavior remains more challenging. This work presents a Multiple Input Operator Network (MIONet) that incorporates a second trunk network to explicitly encode temporal dynamics, enabling accurate prediction of structural responses under moving loads. Traditional DeepONet architectures using recurrent neural networks (RNNs) are limited by fixed time discretization and struggle to capture continuous dynamics. In contrast, MIONet predicts responses continuously over both space and time, removing the need for step wise modeling. It maps scalar inputs including load type, velocity, spatial mesh, and time steps to full field structural responses. To improve efficiency and enforce physical consistency, we introduce a physics informed loss based on dynamic equilibrium using precomputed mass, damping, and stiffness matrices, without solving the governing PDEs directly. Further, a Schur complement formulation reduces the training domain, significantly cutting computational costs while preserving global accuracy. The model is validated on both a simple beam and the KW-51 bridge, achieving FEM level accuracy within seconds. Compared to GRU based DeepONet, our model offers comparable accuracy with improved temporal continuity and over 100 times faster inference, making it well suited for real-time structural monitoring and digital twin applications.
Physics-informed DeepONet with stiffness-based loss functions for structural response prediction
Sep 02, 2024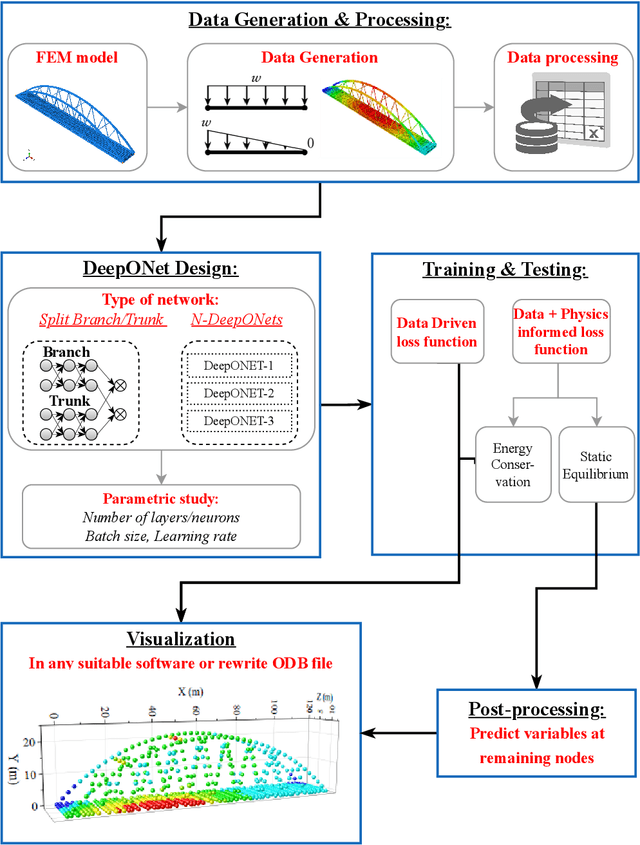
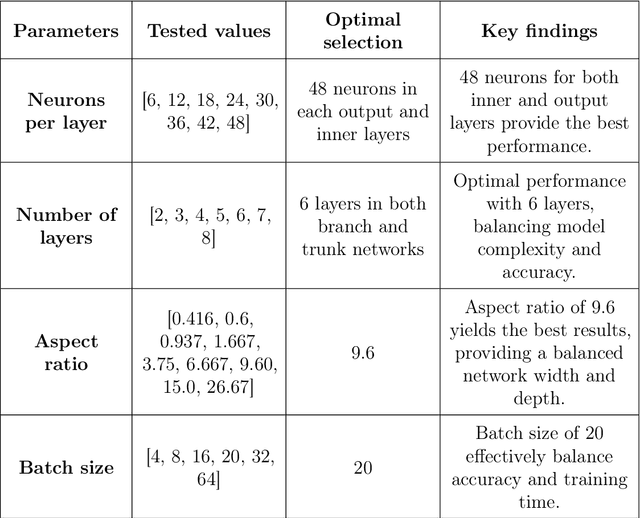
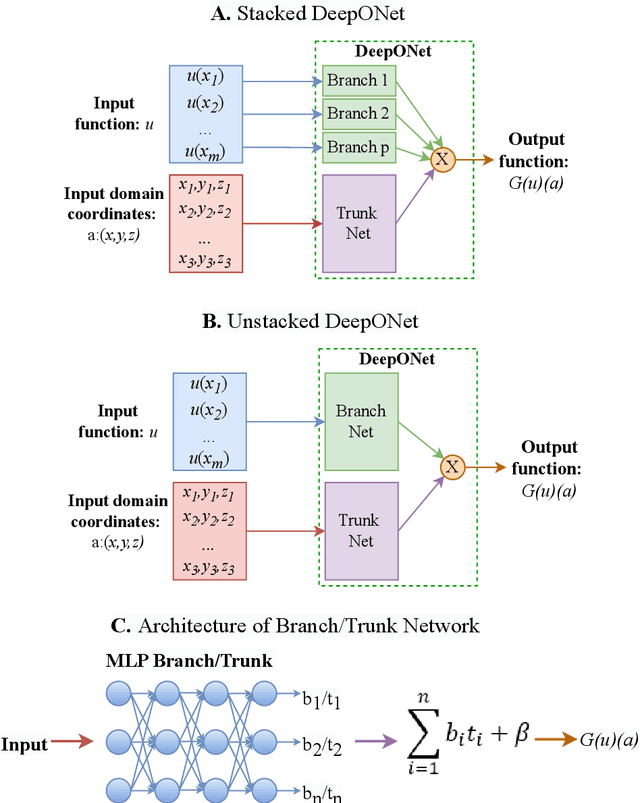
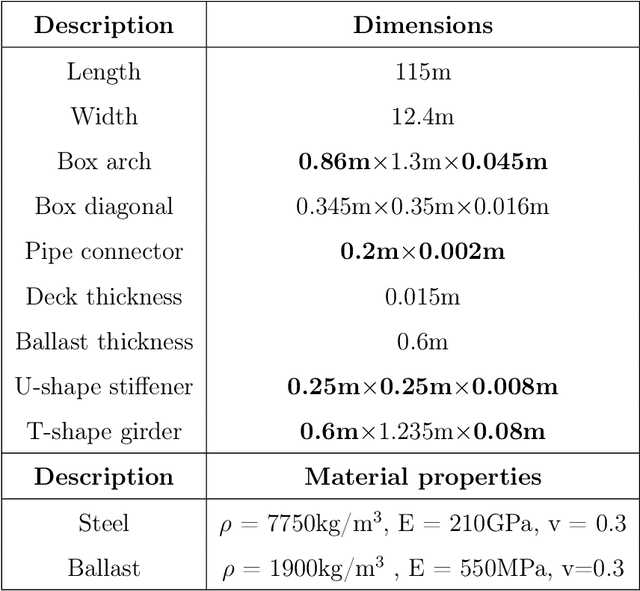
Finite element modeling is a well-established tool for structural analysis, yet modeling complex structures often requires extensive pre-processing, significant analysis effort, and considerable time. This study addresses this challenge by introducing an innovative method for real-time prediction of structural static responses using DeepOnet which relies on a novel approach to physics-informed networks driven by structural balance laws. This approach offers the flexibility to accurately predict responses under various load classes and magnitudes. The trained DeepONet can generate solutions for the entire domain, within a fraction of a second. This capability effectively eliminates the need for extensive remodeling and analysis typically required for each new case in FE modeling. We apply the proposed method to two structures: a simple 2D beam structure and a comprehensive 3D model of a real bridge. To predict multiple variables with DeepONet, we utilize two strategies: a split branch/trunk and multiple DeepONets combined into a single DeepONet. In addition to data-driven training, we introduce a novel physics-informed training approaches. This method leverages structural stiffness matrices to enforce fundamental equilibrium and energy conservation principles, resulting in two novel physics-informed loss functions: energy conservation and static equilibrium using the Schur complement. We use various combinations of loss functions to achieve an error rate of less than 5% with significantly reduced training time. This study shows that DeepONet, enhanced with hybrid loss functions, can accurately and efficiently predict displacements and rotations at each mesh point, with reduced training time.
Damage identification for bridges using machine learning: Development and application to KW51 bridge
Aug 06, 2024



Over the past few decades, structural health monitoring (SHM) has drawn significant attention to identifying damage in structures. However, there are open challenges related to the efficiency and applicability of the existing damage identification approaches. This paper proposes an effective approach that integrates both modal analysis and dynamic analysis strategies for damage identification and applies it to the KW51 railway bridge in Leuven, Belgium. The ML-based damage identification utilizes four types of features: modal analysis input, frequency characteristics, time-frequency characteristics, and stacked time series feature extraction from forced acceleration response. Signal processing methods such as stacking, Fourier transform, and wavelet transform are employed to extract damage-sensitive features from the acceleration series. The ML methods, including the k-nearest neighbors (kNN) algorithm, stacked gated recurrent unit (stacked GRU) network, and convolutional neural network (CNN), are then combined to assess the existence, extent, and location of damage. The proposed method is applied to the KW51 railway bridge. A finite element model (FEM) of the KW51 bridge is developed, which is validated by modal analysis. Various extents and locations of damage are simulated to generate the "Damaged" data, while the "Intact" data from FEM or measured data serve as a baseline for comparison. The identification results for the KW51 bridge demonstrate the high accuracy and robustness of the proposed approach, confirming its effectiveness in damage identification problems.
BIOPAK Flasher: Epidemic disease monitoring and detection in Pakistan using text mining
Jun 12, 2021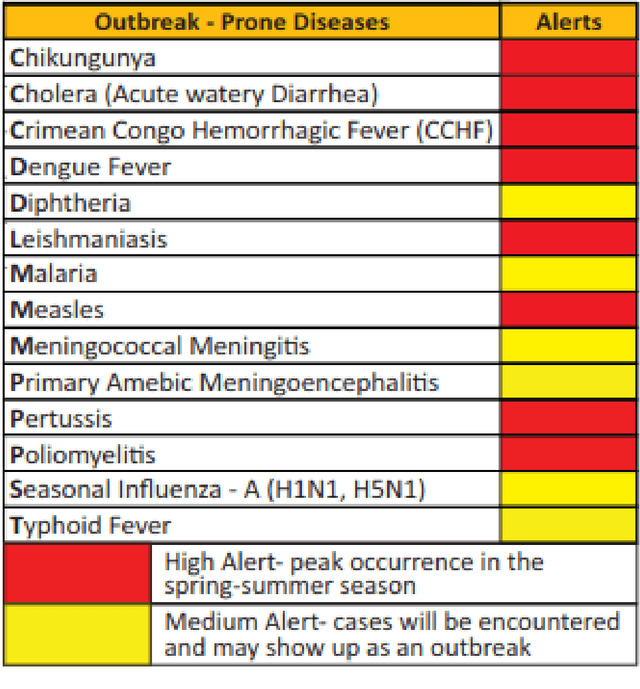
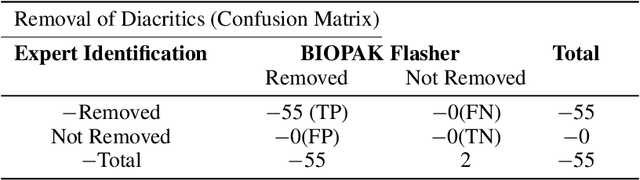
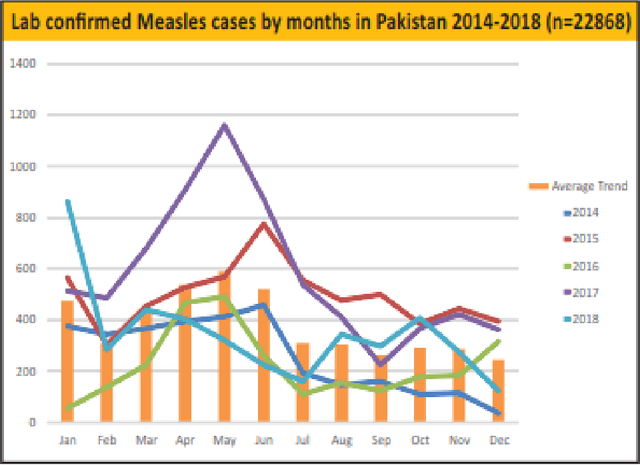
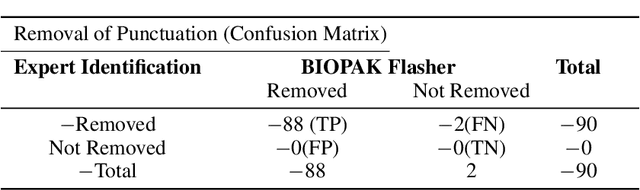
Infectious disease outbreak has a significant impact on morbidity, mortality and can cause economic instability of many countries. As global trade is growing, goods and individuals are expected to travel across the border, an infected epidemic area carrier can pose a great danger to his hostile. If a disease outbreak is recognized promptly, then commercial products and travelers (traders/visitors) will be effectively vaccinated, and therefore the disease stopped. Early detection of outbreaks plays an important role here, and beware of the rapid implementation of control measures by citizens, public health organizations, and government. Many indicators have valuable information, such as online news sources (RSS) and social media sources (Twitter, Facebook) that can be used, but are unstructured and bulky, to extract information about disease outbreaks. Few early warning outbreak systems exist with some limitation of linguistic (Urdu) and covering areas (Pakistan). In Pakistan, few channels are published the outbreak news in Urdu or English. The aim is to procure information from Pakistan's English and Urdu news channels and then investigate process, integrate, and visualize the disease epidemic. Urdu ontology is not existed before to match extracted diseases, so we also build that ontology of disease.
Multi-task Learning with Weak Class Labels: Leveraging iEEG to Detect Cortical Lesions in Cryptogenic Epilepsy
Jul 30, 2016
Multi-task learning (MTL) is useful for domains in which data originates from multiple sources that are individually under-sampled. MTL methods are able to learn classification models that have higher performance as compared to learning a single model by aggregating all the data together or learning a separate model for each data source. The performance of these methods relies on label accuracy. We address the problem of simultaneously learning multiple classifiers in the MTL framework when the training data has imprecise labels. We assume that there is an additional source of information that provides a score for each instance which reflects the certainty about its label. Modeling this score as being generated by an underlying ranking function, we augment the MTL framework with an added layer of supervision. This results in new MTL methods that are able to learn accurate classifiers while preserving the domain structure provided through the rank information. We apply these methods to the task of detecting abnormal cortical regions in the MRIs of patients suffering from focal epilepsy whose MRI were read as normal by expert neuroradiologists. In addition to the noisy labels provided by the results of surgical resection, we employ the results of an invasive intracranial-EEG exam as an additional source of label information. Our proposed methods are able to successfully detect abnormal regions for all patients in our dataset and achieve a higher performance as compared to baseline methods.
Lexical Normalisation of Twitter Data
Sep 20, 2015


Twitter with over 500 million users globally, generates over 100,000 tweets per minute . The 140 character limit per tweet, perhaps unintentionally, encourages users to use shorthand notations and to strip spellings to their bare minimum "syllables" or elisions e.g. "srsly". The analysis of twitter messages which typically contain misspellings, elisions, and grammatical errors, poses a challenge to established Natural Language Processing (NLP) tools which are generally designed with the assumption that the data conforms to the basic grammatical structure commonly used in English language. In order to make sense of Twitter messages it is necessary to first transform them into a canonical form, consistent with the dictionary or grammar. This process, performed at the level of individual tokens ("words"), is called lexical normalisation. This paper investigates various techniques for lexical normalisation of Twitter data and presents the findings as the techniques are applied to process raw data from Twitter.
Predictive Capacity of Meteorological Data - Will it rain tomorrow
Sep 16, 2014
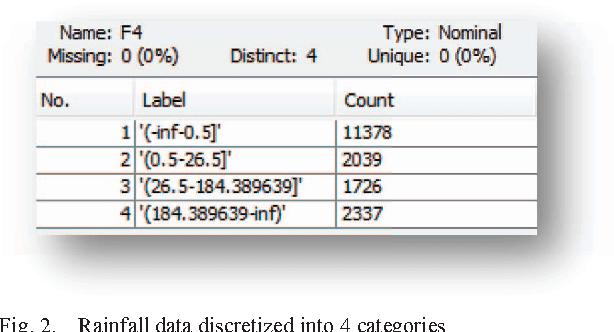


With the availability of high precision digital sensors and cheap storage medium, it is not uncommon to find large amounts of data collected on almost all measurable attributes, both in nature and man-made habitats. Weather in particular has been an area of keen interest for researchers to develop more accurate and reliable prediction models. This paper presents a set of experiments which involve the use of prevalent machine learning techniques to build models to predict the day of the week given the weather data for that particular day i.e. temperature, wind, rain etc., and test their reliability across four cities in Australia {Brisbane, Adelaide, Perth, Hobart}. The results provide a comparison of accuracy of these machine learning techniques and their reliability to predict the day of the week by analysing the weather data. We then apply the models to predict weather conditions based on the available data.