 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Learning with Weak Class Labels: Leveraging iEEG to Detect Cortical Lesions in Cryptogenic Epilepsy
Jul 30, 2016
Multi-task learning (MTL) is useful for domains in which data originates from multiple sources that are individually under-sampled. MTL methods are able to learn classification models that have higher performance as compared to learning a single model by aggregating all the data together or learning a separate model for each data source. The performance of these methods relies on label accuracy. We address the problem of simultaneously learning multiple classifiers in the MTL framework when the training data has imprecise labels. We assume that there is an additional source of information that provides a score for each instance which reflects the certainty about its label. Modeling this score as being generated by an underlying ranking function, we augment the MTL framework with an added layer of supervision. This results in new MTL methods that are able to learn accurate classifiers while preserving the domain structure provided through the rank information. We apply these methods to the task of detecting abnormal cortical regions in the MRIs of patients suffering from focal epilepsy whose MRI were read as normal by expert neuroradiologists. In addition to the noisy labels provided by the results of surgical resection, we employ the results of an invasive intracranial-EEG exam as an additional source of label information. Our proposed methods are able to successfully detect abnormal regions for all patients in our dataset and achieve a higher performance as compared to baseline methods.
Finding Anomalous Periodic Time Series: An Application to Catalogs of Periodic Variable Stars
May 21, 2009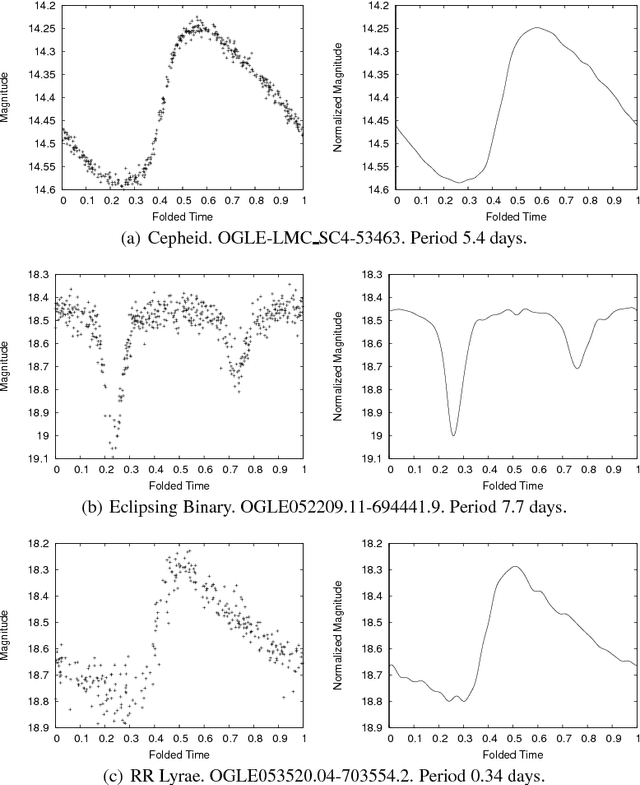
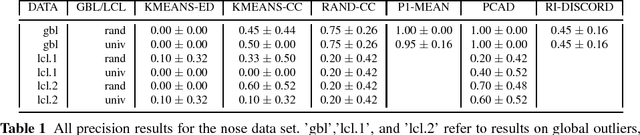
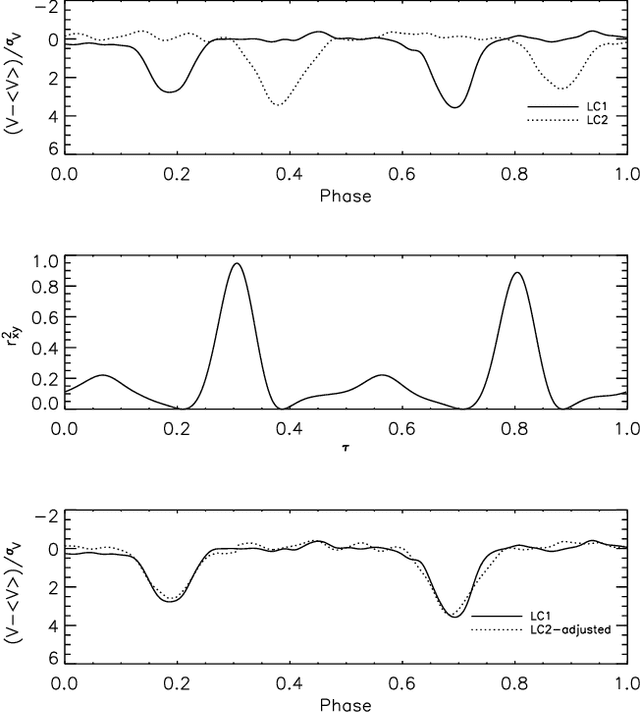

Catalogs of periodic variable stars contain large numbers of periodic light-curves (photometric time series data from the astrophysics domain). Separating anomalous objects from well-known classes is an important step towards the discovery of new classes of astronomical objects. Most anomaly detection methods for time series data assume either a single continuous time series or a set of time series whose periods are aligned. Light-curve data precludes the use of these methods as the periods of any given pair of light-curves may be out of sync. One may use an existing anomaly detection method if, prior to similarity calculation, one performs the costly act of aligning two light-curves, an operation that scales poorly to massive data sets. This paper presents PCAD, an unsupervised anomaly detection method for large sets of unsynchronized periodic time-series data, that outputs a ranked list of both global and local anomalies. It calculates its anomaly score for each light-curve in relation to a set of centroids produced by a modified k-means clustering algorithm. Our method is able to scale to large data sets through the use of sampling. We validate our method on both light-curve data and other time series data sets. We demonstrate its effectiveness at finding known anomalies, and discuss the effect of sample size and number of centroids on our results. We compare our method to naive solutions and existing time series anomaly detection methods for unphased data, and show that PCAD's reported anomalies are comparable to or better than all other methods. Finally, astrophysicists on our team have verified that PCAD finds true anomalies that might be indicative of novel astrophysical phenomena.