 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeView-Consistent 3D Scene Editing via Dual-Path Structural Correspondense and Semantic Continuity
Apr 20, 2026Text-driven 3D scene editing has recently attracted increasing attention. Most existing methods follow a render-edit-optimize pipeline, where multi-view images are rendered from a 3D scene, edited with 2D image editors, and then used to optimize the underlying 3D representation. However, cross-view inconsistency remains a major bottleneck. Although recent methods introduce geometric cues, cross-view interactions, or video priors to mitigate this issue, they still largely rely on inference-time synchronization and thus remain limited in robustness and generalization.In this work, we recast multi-view consistent 3D editing from a distributional perspective: 3D scene editing essentially requires a joint distribution modeling across viewpoints.Based on this insight, we propose a view-consistent 3D editing framework that explicitly introduces cross-view dependencies into the editing process. Furthermore, motivated by the observation that structural correspondence and semantic continuity rely on different cross-view cues, we introduce a dual-path consistency mechanism consisting of projection-guided structural guidance and patch-level semantic propagation for effective cross-view editing. Further, we construct a paired multi-view editing dataset that provides reliable supervision for learning cross-view consistency in edited scenes. Extensive experiments demonstrate that our method achieves superior editing performance with precise and consistent views for complex scenes.
From Part to Whole: 3D Generative World Model with an Adaptive Structural Hierarchy
Mar 23, 2026Single-image 3D generation lies at the core of vision-to-graphics models in the real world. However, it remains a fundamental challenge to achieve reliable generalization across diverse semantic categories and highly variable structural complexity under sparse supervision. Existing approaches typically model objects in a monolithic manner or rely on a fixed number of parts, including recent part-aware models such as PartCrafter, which still require a labor-intensive user-specified part count. Such designs easily lead to overfitting, fragmented or missing structural components, and limited compositional generalization when encountering novel object layouts. To this end, this paper rethinks single-image 3D generation as learning an adaptive part-whole hierarchy in the flexible 3D latent space. We present a novel part-to-whole 3D generative world model that autonomously discovers latent structural slots by inferring soft and compositional masks directly from image tokens. Specifically, an adaptive slot-gating mechanism dynamically determines the slot-wise activation probabilities and smoothly consolidates redundant slots within different objects, ensuring that the emergent structure remains compact yet expressive across categories. Each distilled slot is then aligned to a learnable, class-agnostic prototype bank, enabling powerful cross-category shape sharing and denoising through universal geometric prototypes in the real world. Furthermore, a lightweight 3D denoiser is introduced to reconstruct geometry and appearance via unified diffusion objectives. Experiments show consistent gains in cross-category transfer and part-count extrapolation, and ablations confirm complementary benefits of the prototype bank for shape-prior sharing as well as slot-gating for structural adaptation.
Behave Your Motion: Habit-preserved Cross-category Animal Motion Transfer
Jul 10, 2025Animal motion embodies species-specific behavioral habits, making the transfer of motion across categories a critical yet complex task for applications in animation and virtual reality. Existing motion transfer methods, primarily focused on human motion, emphasize skeletal alignment (motion retargeting) or stylistic consistency (motion style transfer), often neglecting the preservation of distinct habitual behaviors in animals. To bridge this gap, we propose a novel habit-preserved motion transfer framework for cross-category animal motion. Built upon a generative framework, our model introduces a habit-preservation module with category-specific habit encoder, allowing it to learn motion priors that capture distinctive habitual characteristics. Furthermore, we integrate a large language model (LLM) to facilitate the motion transfer to previously unobserved species. To evaluate the effectiveness of our approach, we introduce the DeformingThings4D-skl dataset, a quadruped dataset with skeletal bindings, and conduct extensive experiments and quantitative analyses, which validate the superiority of our proposed model.
Multi-scale Latent Point Consistency Models for 3D Shape Generation
Dec 27, 2024Consistency Models (CMs) have significantly accelerated the sampling process in diffusion models, yielding impressive results in synthesizing high-resolution images. To explore and extend these advancements to point-cloud-based 3D shape generation, we propose a novel Multi-scale Latent Point Consistency Model (MLPCM). Our MLPCM follows a latent diffusion framework and introduces hierarchical levels of latent representations, ranging from point-level to super-point levels, each corresponding to a different spatial resolution. We design a multi-scale latent integration module along with 3D spatial attention to effectively denoise the point-level latent representations conditioned on those from multiple super-point levels. Additionally, we propose a latent consistency model, learned through consistency distillation, that compresses the prior into a one-step generator. This significantly improves sampling efficiency while preserving the performance of the original teacher model. Extensive experiments on standard benchmarks ShapeNet and ShapeNet-Vol demonstrate that MLPCM achieves a 100x speedup in the generation process, while surpassing state-of-the-art diffusion models in terms of both shape quality and diversity.
Self-augmented Gaussian Splatting with Structure-aware Masks for Sparse-view 3D Reconstruction
Aug 09, 2024
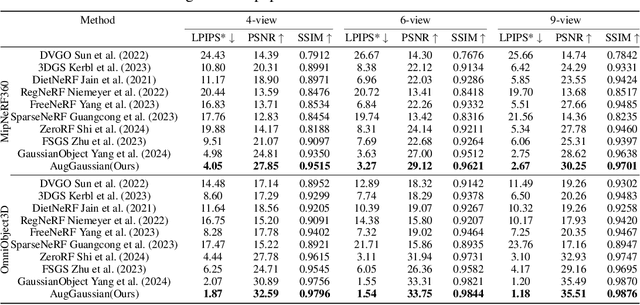
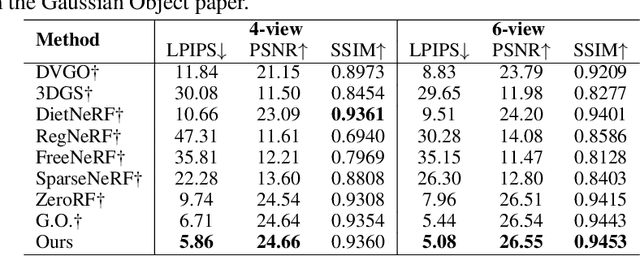

Sparse-view 3D reconstruction stands as a formidable challenge in computer vision, aiming to build complete three-dimensional models from a limited array of viewing perspectives. This task confronts several difficulties: 1) the limited number of input images that lack consistent information; 2) dependence on the quality of input images; and 3) the substantial size of model parameters. To address these challenges, we propose a self-augmented coarse-to-fine Gaussian splatting paradigm, enhanced with a structure-aware mask, for sparse-view 3D reconstruction. In particular, our method initially employs a coarse Gaussian model to obtain a basic 3D representation from sparse-view inputs. Subsequently, we develop a fine Gaussian network to enhance consistent and detailed representation of the output with both 3D geometry augmentation and perceptual view augmentation. During training, we design a structure-aware masking strategy to further improve the model's robustness against sparse inputs and noise.Experimental results on the MipNeRF360 and OmniObject3D datasets demonstrate that the proposed method achieves state-of-the-art performances for sparse input views in both perceptual quality and efficiency.
Generative 3D Part Assembly via Part-Whole-Hierarchy Message Passing
Feb 27, 2024



Generative 3D part assembly involves understanding part relationships and predicting their 6-DoF poses for assembling a realistic 3D shape. Prior work often focus on the geometry of individual parts, neglecting part-whole hierarchies of objects. Leveraging two key observations: 1) super-part poses provide strong hints about part poses, and 2) predicting super-part poses is easier due to fewer superparts, we propose a part-whole-hierarchy message passing network for efficient 3D part assembly. We first introduce super-parts by grouping geometrically similar parts without any semantic labels. Then we employ a part-whole hierarchical encoder, wherein a super-part encoder predicts latent super-part poses based on input parts. Subsequently, we transform the point cloud using the latent poses, feeding it to the part encoder for aggregating super-part information and reasoning about part relationships to predict all part poses. In training, only ground-truth part poses are required. During inference, the predicted latent poses of super-parts enhance interpretability. Experimental results on the PartNet dataset show that our method achieves state-of-the-art performance in part and connectivity accuracy and enables an interpretable hierarchical part assembly.
Deep Point Set Resampling via Gradient Fields
Nov 03, 2021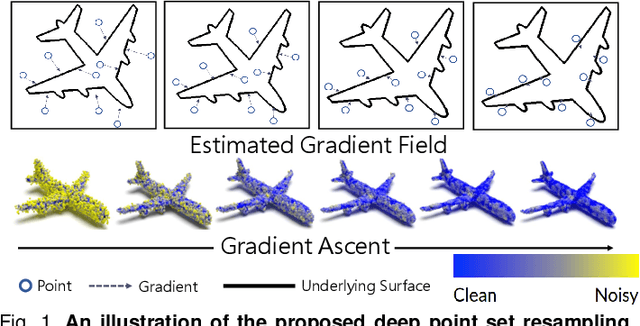
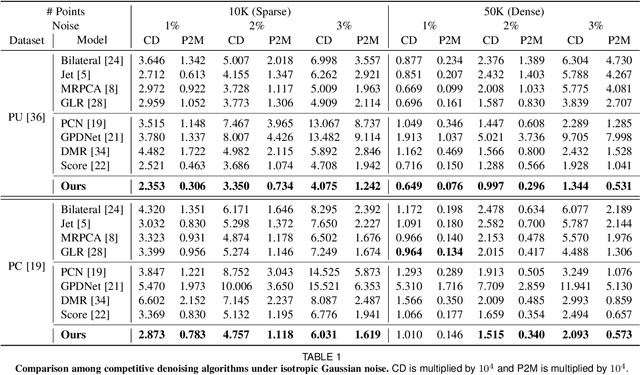
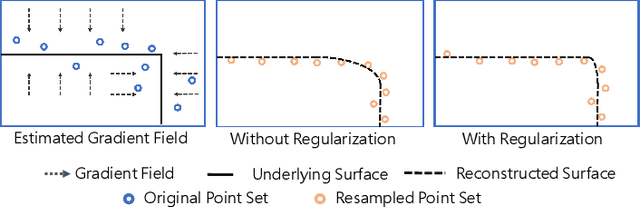
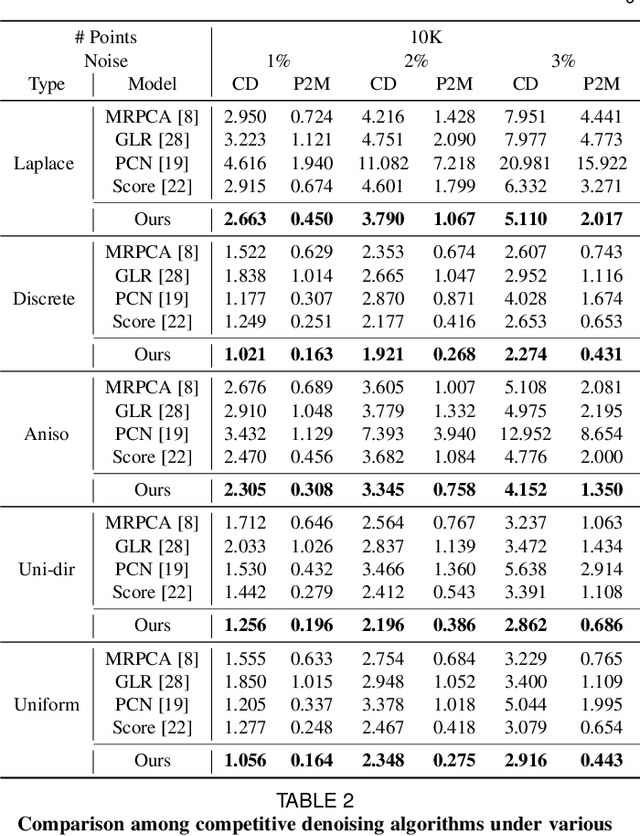
3D point clouds acquired by scanning real-world objects or scenes have found a wide range of applications including immersive telepresence, autonomous driving, surveillance, etc. They are often perturbed by noise or suffer from low density, which obstructs downstream tasks such as surface reconstruction and understanding. In this paper, we propose a novel paradigm of point set resampling for restoration, which learns continuous gradient fields of point clouds that converge points towards the underlying surface. In particular, we represent a point cloud via its gradient field -- the gradient of the log-probability density function, and enforce the gradient field to be continuous, thus guaranteeing the continuity of the model for solvable optimization. Based on the continuous gradient fields estimated via a proposed neural network, resampling a point cloud amounts to performing gradient-based Markov Chain Monte Carlo (MCMC) on the input noisy or sparse point cloud. Further, we propose to introduce regularization into the gradient-based MCMC during point cloud restoration, which essentially refines the intermediate resampled point cloud iteratively and accommodates various priors in the resampling process. Extensive experimental results demonstrate that the proposed point set resampling achieves the state-of-the-art performance in representative restoration tasks including point cloud denoising and upsampling.
Self-Contrastive Learning with Hard Negative Sampling for Self-supervised Point Cloud Learning
Jul 05, 2021Point clouds have attracted increasing attention as a natural representation of 3D shapes. Significant progress has been made in developing methods for point cloud analysis, which often requires costly human annotation as supervision in practice. To address this issue, we propose a novel self-contrastive learning for self-supervised point cloud representation learning, aiming to capture both local geometric patterns and nonlocal semantic primitives based on the nonlocal self-similarity of point clouds. The contributions are two-fold: on the one hand, instead of contrasting among different point clouds as commonly employed in contrastive learning, we exploit self-similar point cloud patches within a single point cloud as positive samples and otherwise negative ones to facilitate the task of contrastive learning. Such self-contrastive learning is well aligned with the emerging paradigm of self-supervised learning for point cloud analysis. On the other hand, we actively learn hard negative samples that are close to positive samples in the representation space for discriminative feature learning, which are sampled conditional on each anchor patch leveraging on the degree of self-similarity. Experimental results show that the proposed method achieves state-of-the-art performance on widely used benchmark datasets for self-supervised point cloud segmentation and transfer learning for classification.