 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Visual Feedback to Guide Benchmark Creation: A Human-and-Metric-in-the-Loop Workflow
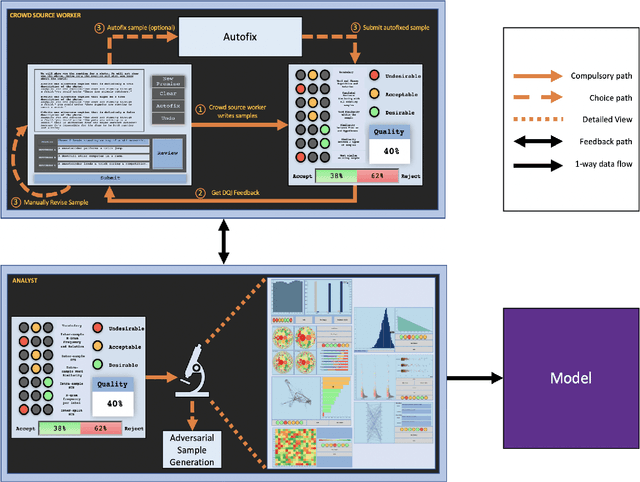
Feb 09, 2023Recent research has shown that language models exploit `artifacts' in benchmarks to solve tasks, rather than truly learning them, leading to inflated model performance. In pursuit of creating better benchmarks, we propose VAIDA, a novel benchmark creation paradigm for NLP, that focuses on guiding crowdworkers, an under-explored facet of addressing benchmark idiosyncrasies. VAIDA facilitates sample correction by providing realtime visual feedback and recommendations to improve sample quality. Our approach is domain, model, task, and metric agnostic, and constitutes a paradigm shift for robust, validated, and dynamic benchmark creation via human-and-metric-in-the-loop workflows. We evaluate via expert review and a user study with NASA TLX. We find that VAIDA decreases effort, frustration, mental, and temporal demands of crowdworkers and analysts, simultaneously increasing the performance of both user groups with a 45.8% decrease in the level of artifacts in created samples. As a by product of our user study, we observe that created samples are adversarial across models, leading to decreases of 31.3% (BERT), 22.5% (RoBERTa), 14.98% (GPT-3 fewshot) in performance.
NumGLUE: A Suite of Fundamental yet Challenging Mathematical Reasoning Tasks
Apr 12, 2022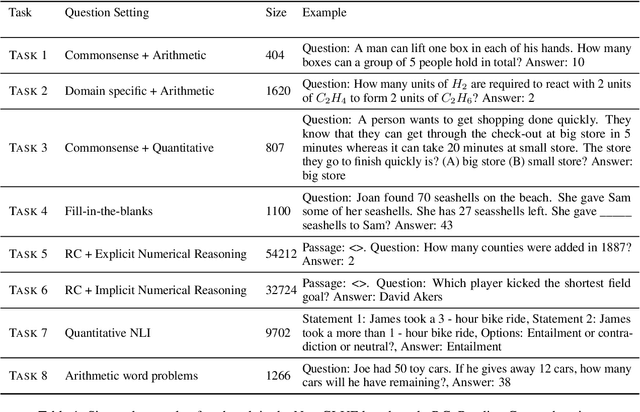
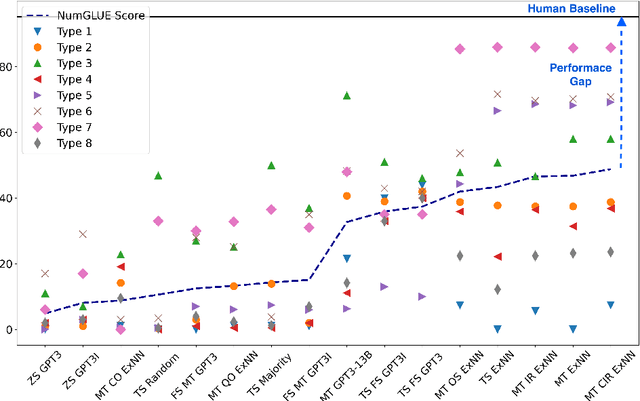
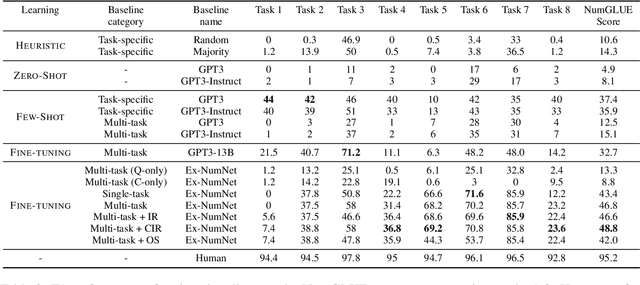

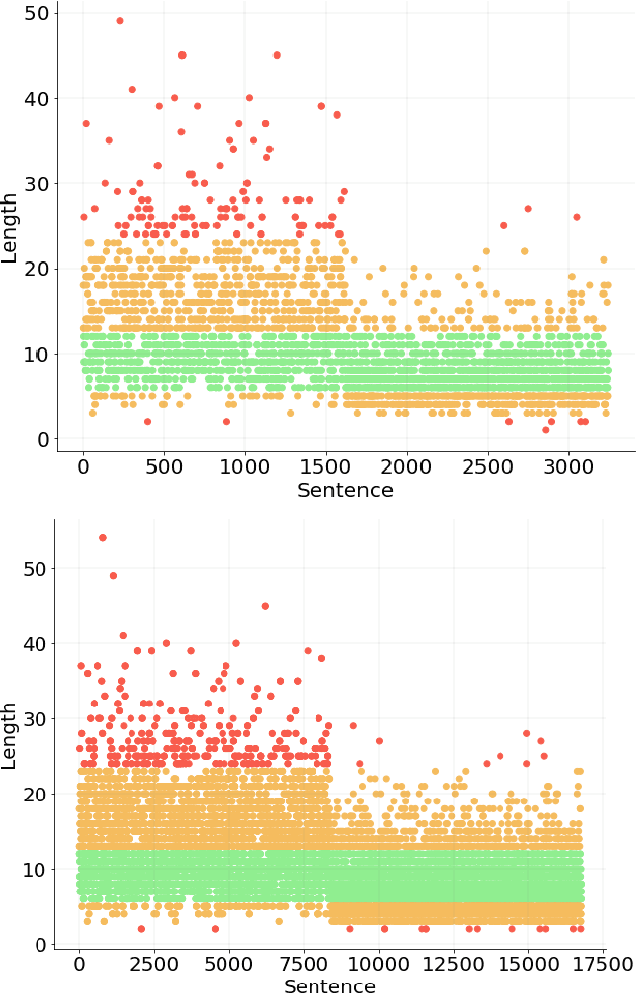
Given the ubiquitous nature of numbers in text, reasoning with numbers to perform simple calculations is an important skill of AI systems. While many datasets and models have been developed to this end, state-of-the-art AI systems are brittle; failing to perform the underlying mathematical reasoning when they appear in a slightly different scenario. Drawing inspiration from GLUE that was proposed in the context of natural language understanding, we propose NumGLUE, a multi-task benchmark that evaluates the performance of AI systems on eight different tasks, that at their core require simple arithmetic understanding. We show that this benchmark is far from being solved with neural models including state-of-the-art large-scale language models performing significantly worse than humans (lower by 46.4%). Further, NumGLUE promotes sharing knowledge across tasks, especially those with limited training data as evidenced by the superior performance (average gain of 3.4% on each task) when a model is jointly trained on all the tasks as opposed to task-specific modeling. Finally, we hope that NumGLUE will encourage systems that perform robust and general arithmetic reasoning within language, a first step towards being able to perform more complex mathematical reasoning.
DQI: A Guide to Benchmark Evaluation
Aug 10, 2020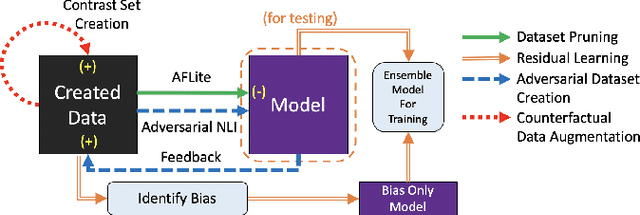


A `state of the art' model A surpasses humans in a benchmark B, but fails on similar benchmarks C, D, and E. What does B have that the other benchmarks do not? Recent research provides the answer: spurious bias. However, developing A to solve benchmarks B through E does not guarantee that it will solve future benchmarks. To progress towards a model that `truly learns' an underlying task, we need to quantify the differences between successive benchmarks, as opposed to existing binary and black-box approaches. We propose a novel approach to solve this underexplored task of quantifying benchmark quality by debuting a data quality metric: DQI.
Towards Question Format Independent Numerical Reasoning: A Set of Prerequisite Tasks
May 18, 2020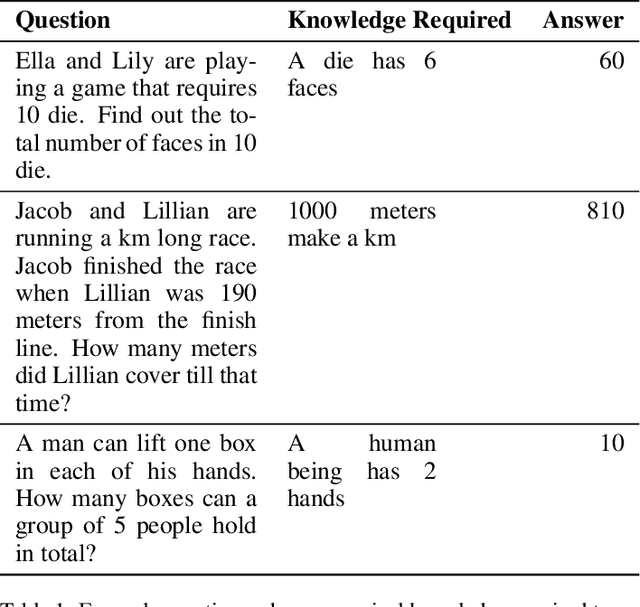
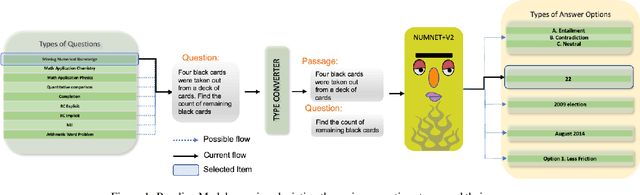
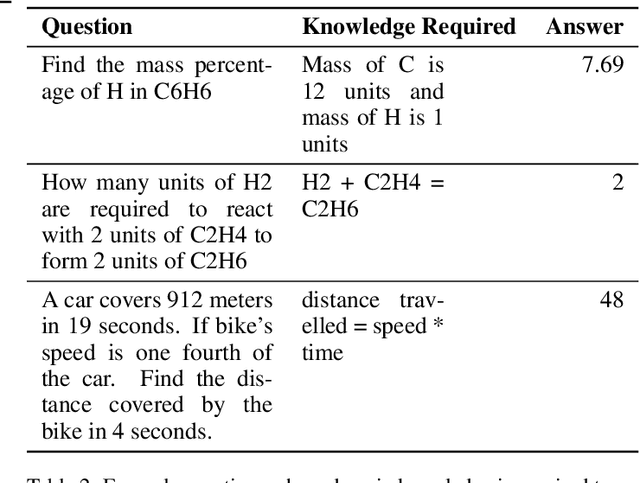
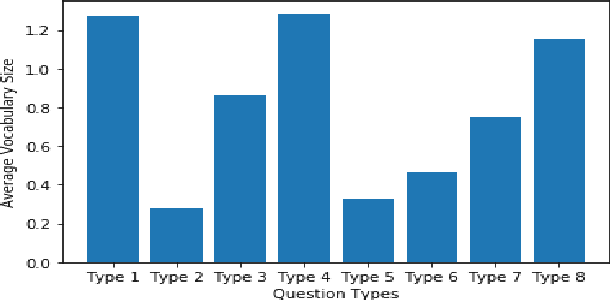
Numerical reasoning is often important to accurately understand the world. Recently, several format-specific datasets have been proposed, such as numerical reasoning in the settings of Natural Language Inference (NLI), Reading Comprehension (RC), and Question Answering (QA). Several format-specific models and architectures in response to those datasets have also been proposed. However, there exists a strong need for a benchmark which can evaluate the abilities of models, in performing question format independent numerical reasoning, as (i) the numerical reasoning capabilities we want to teach are not controlled by question formats, (ii) for numerical reasoning technology to have the best possible application, it must be able to process language and reason in a way that is not exclusive to a single format, task, dataset or domain. In pursuit of this goal, we introduce NUMBERGAME, a multifaceted benchmark to evaluate model performance across numerical reasoning tasks of eight diverse formats. We add four existing question types in our compilation. Two of the new types we add are about questions that require external numerical knowledge, commonsense knowledge and domain knowledge. For building a more practical numerical reasoning system, NUMBERGAME demands four capabilities beyond numerical reasoning: (i) detecting question format directly from data (ii) finding intermediate common format to which every format can be converted (iii) incorporating commonsense knowledge (iv) handling data imbalance across formats. We build several baselines, including a new model based on knowledge hunting using a cheatsheet. However, all baselines perform poorly in contrast to the human baselines, indicating the hardness of our benchmark. Our work takes forward the recent progress in generic system development, demonstrating the scope of these under-explored tasks.
DQI: Measuring Data Quality in NLP
May 02, 2020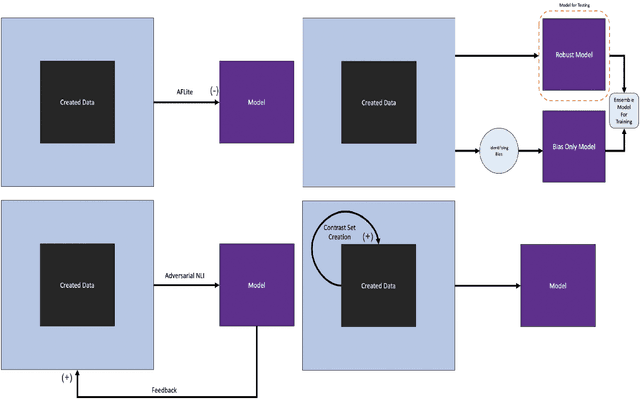

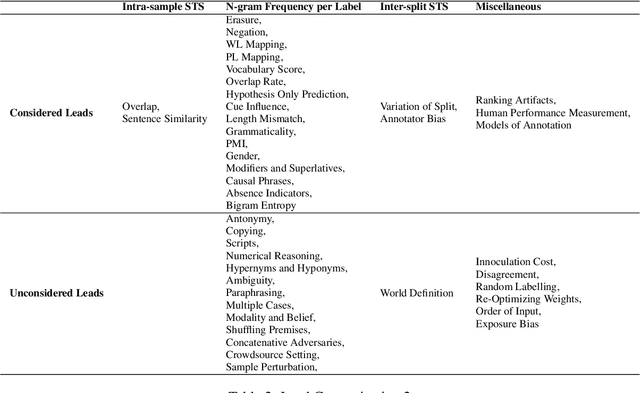
Neural language models have achieved human level performance across several NLP datasets. However, recent studies have shown that these models are not truly learning the desired task; rather, their high performance is attributed to overfitting using spurious biases, which suggests that the capabilities of AI systems have been over-estimated. We introduce a generic formula for Data Quality Index (DQI) to help dataset creators create datasets free of such unwanted biases. We evaluate this formula using a recently proposed approach for adversarial filtering, AFLite. We propose a new data creation paradigm using DQI to create higher quality data. The data creation paradigm consists of several data visualizations to help data creators (i) understand the quality of data and (ii) visualize the impact of the created data instance on the overall quality. It also has a couple of automation methods to (i) assist data creators and (ii) make the model more robust to adversarial attacks. We use DQI along with these automation methods to renovate biased examples in SNLI. We show that models trained on the renovated SNLI dataset generalize better to out of distribution tasks. Renovation results in reduced model performance, exposing a large gap with respect to human performance. DQI systematically helps in creating harder benchmarks using active learning. Our work takes the process of dynamic dataset creation forward, wherein datasets evolve together with the evolving state of the art, therefore serving as a means of benchmarking the true progress of AI.