Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQI: A Guide to Benchmark Evaluation
Paper and Code
Aug 10, 2020


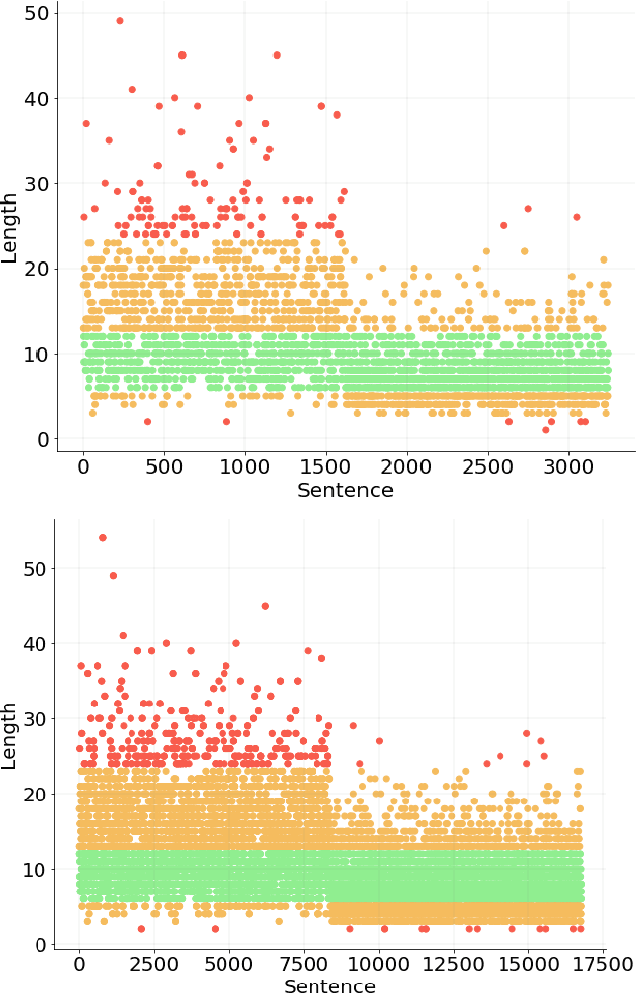
A `state of the art' model A surpasses humans in a benchmark B, but fails on similar benchmarks C, D, and E. What does B have that the other benchmarks do not? Recent research provides the answer: spurious bias. However, developing A to solve benchmarks B through E does not guarantee that it will solve future benchmarks. To progress towards a model that `truly learns' an underlying task, we need to quantify the differences between successive benchmarks, as opposed to existing binary and black-box approaches. We propose a novel approach to solve this underexplored task of quantifying benchmark quality by debuting a data quality metric: DQI.
* ICML UDL 2020
View paper on