 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQI: Measuring Data Quality in NLP
Paper and Code
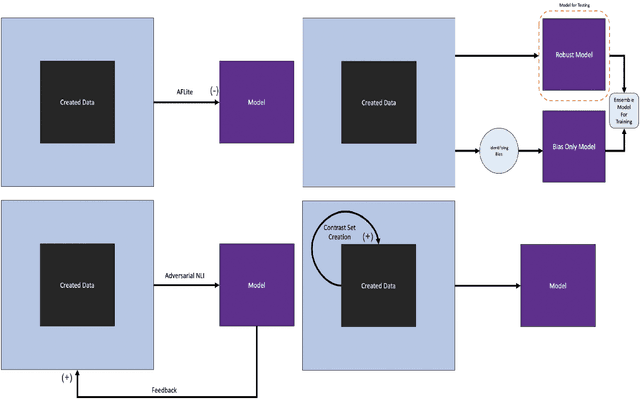

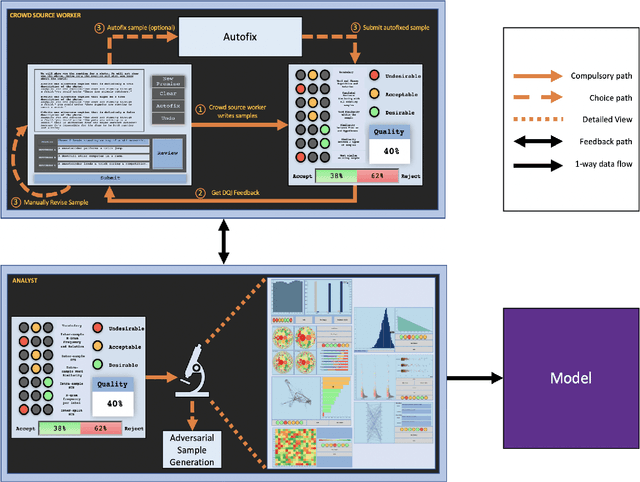
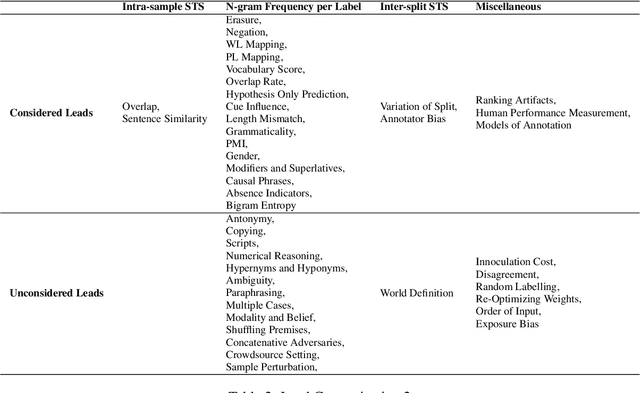
Neural language models have achieved human level performance across several NLP datasets. However, recent studies have shown that these models are not truly learning the desired task; rather, their high performance is attributed to overfitting using spurious biases, which suggests that the capabilities of AI systems have been over-estimated. We introduce a generic formula for Data Quality Index (DQI) to help dataset creators create datasets free of such unwanted biases. We evaluate this formula using a recently proposed approach for adversarial filtering, AFLite. We propose a new data creation paradigm using DQI to create higher quality data. The data creation paradigm consists of several data visualizations to help data creators (i) understand the quality of data and (ii) visualize the impact of the created data instance on the overall quality. It also has a couple of automation methods to (i) assist data creators and (ii) make the model more robust to adversarial attacks. We use DQI along with these automation methods to renovate biased examples in SNLI. We show that models trained on the renovated SNLI dataset generalize better to out of distribution tasks. Renovation results in reduced model performance, exposing a large gap with respect to human performance. DQI systematically helps in creating harder benchmarks using active learning. Our work takes the process of dynamic dataset creation forward, wherein datasets evolve together with the evolving state of the art, therefore serving as a means of benchmarking the true progress of AI.