 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Preserving QBNNs: Multi-Level Quantization of SVI-Based Bayesian Neural Networks for Image Classification
Dec 11, 2025Bayesian Neural Networks (BNNs) provide principled uncertainty quantification but suffer from substantial computational and memory overhead compared to deterministic networks. While quantization techniques have successfully reduced resource requirements in standard deep learning models, their application to probabilistic models remains largely unexplored. We introduce a systematic multi-level quantization framework for Stochastic Variational Inference based BNNs that distinguishes between three quantization strategies: Variational Parameter Quantization (VPQ), Sampled Parameter Quantization (SPQ), and Joint Quantization (JQ). Our logarithmic quantization for variance parameters, and specialized activation functions to preserve the distributional structure are essential for calibrated uncertainty estimation. Through comprehensive experiments on Dirty-MNIST, we demonstrate that BNNs can be quantized down to 4-bit precision while maintaining both classification accuracy and uncertainty disentanglement. At 4 bits, Joint Quantization achieves up to 8x memory reduction compared to floating-point implementations with minimal degradation in epistemic and aleatoric uncertainty estimation. These results enable deployment of BNNs on resource-constrained edge devices and provide design guidelines for future analog "Bayesian Machines" operating at inherently low precision.
Variance-Aware Noisy Training: Hardening DNNs against Unstable Analog Computations
Mar 20, 2025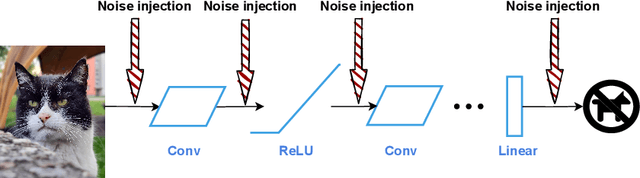
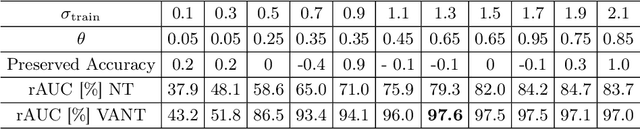
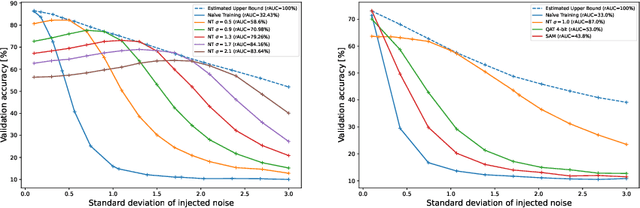
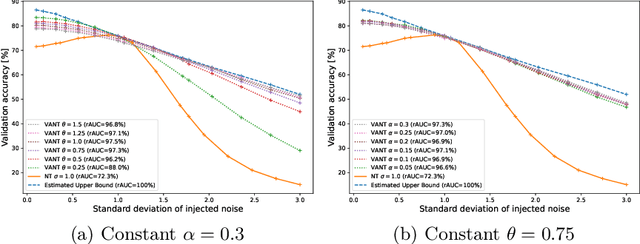
The disparity between the computational demands of deep learning and the capabilities of compute hardware is expanding drastically. Although deep learning achieves remarkable performance in countless tasks, its escalating requirements for computational power and energy consumption surpass the sustainable limits of even specialized neural processing units, including the Apple Neural Engine and NVIDIA TensorCores. This challenge is intensified by the slowdown in CMOS scaling. Analog computing presents a promising alternative, offering substantial improvements in energy efficiency by directly manipulating physical quantities such as current, voltage, charge, or photons. However, it is inherently vulnerable to manufacturing variations, nonlinearities, and noise, leading to degraded prediction accuracy. One of the most effective techniques for enhancing robustness, Noisy Training, introduces noise during the training phase to reinforce the model against disturbances encountered during inference. Although highly effective, its performance degrades in real-world environments where noise characteristics fluctuate due to external factors such as temperature variations and temporal drift. This study underscores the necessity of Noisy Training while revealing its fundamental limitations in the presence of dynamic noise. To address these challenges, we propose Variance-Aware Noisy Training, a novel approach that mitigates performance degradation by incorporating noise schedules which emulate the evolving noise conditions encountered during inference. Our method substantially improves model robustness, without training overhead. We demonstrate a significant increase in robustness, from 72.3\% with conventional Noisy Training to 97.3\% with Variance-Aware Noisy Training on CIFAR-10 and from 38.5\% to 89.9\% on Tiny ImageNet.
On Hardening DNNs against Noisy Computations
Jan 24, 2025



The success of deep learning has sparked significant interest in designing computer hardware optimized for the high computational demands of neural network inference. As further miniaturization of digital CMOS processors becomes increasingly challenging, alternative computing paradigms, such as analog computing, are gaining consideration. Particularly for compute-intensive tasks such as matrix multiplication, analog computing presents a promising alternative due to its potential for significantly higher energy efficiency compared to conventional digital technology. However, analog computations are inherently noisy, which makes it challenging to maintain high accuracy on deep neural networks. This work investigates the effectiveness of training neural networks with quantization to increase the robustness against noise. Experimental results across various network architectures show that quantization-aware training with constant scaling factors enhances robustness. We compare these methods with noisy training, which incorporates a noise injection during training that mimics the noise encountered during inference. While both two methods increase tolerance against noise, noisy training emerges as the superior approach for achieving robust neural network performance, especially in complex neural architectures.
Function Space Diversity for Uncertainty Prediction via Repulsive Last-Layer Ensembles
Dec 20, 2024Bayesian inference in function space has gained attention due to its robustness against overparameterization in neural networks. However, approximating the infinite-dimensional function space introduces several challenges. In this work, we discuss function space inference via particle optimization and present practical modifications that improve uncertainty estimation and, most importantly, make it applicable for large and pretrained networks. First, we demonstrate that the input samples, where particle predictions are enforced to be diverse, are detrimental to the model performance. While diversity on training data itself can lead to underfitting, the use of label-destroying data augmentation, or unlabeled out-of-distribution data can improve prediction diversity and uncertainty estimates. Furthermore, we take advantage of the function space formulation, which imposes no restrictions on network parameterization other than sufficient flexibility. Instead of using full deep ensembles to represent particles, we propose a single multi-headed network that introduces a minimal increase in parameters and computation. This allows seamless integration to pretrained networks, where this repulsive last-layer ensemble can be used for uncertainty aware fine-tuning at minimal additional cost. We achieve competitive results in disentangling aleatoric and epistemic uncertainty for active learning, detecting out-of-domain data, and providing calibrated uncertainty estimates under distribution shifts with minimal compute and memory.
On the Non-Associativity of Analog Computations
Sep 25, 2023The energy efficiency of analog forms of computing makes it one of the most promising candidates to deploy resource-hungry machine learning tasks on resource-constrained system such as mobile or embedded devices. However, it is well known that for analog computations the safety net of discretization is missing, thus all analog computations are exposed to a variety of imperfections of corresponding implementations. Examples include non-linearities, saturation effect and various forms of noise. In this work, we observe that the ordering of input operands of an analog operation also has an impact on the output result, which essentially makes analog computations non-associative, even though the underlying operation might be mathematically associative. We conduct a simple test by creating a model of a real analog processor which captures such ordering effects. With this model we assess the importance of ordering by comparing the test accuracy of a neural network for keyword spotting, which is trained based either on an ordered model, on a non-ordered variant, and on real hardware. The results prove the existence of ordering effects as well as their high impact, as neglecting ordering results in substantial accuracy drops.
Walking Noise: Understanding Implications of Noisy Computations on Classification Tasks
Dec 20, 2022Machine learning methods like neural networks are extremely successful and popular in a variety of applications, however, they come at substantial computational costs, accompanied by high energy demands. In contrast, hardware capabilities are limited and there is evidence that technology scaling is stuttering, therefore, new approaches to meet the performance demands of increasingly complex model architectures are required. As an unsafe optimization, noisy computations are more energy efficient, and given a fixed power budget also more time efficient. However, any kind of unsafe optimization requires counter measures to ensure functionally correct results. This work considers noisy computations in an abstract form, and gears to understand the implications of such noise on the accuracy of neural-network-based classifiers as an exemplary workload. We propose a methodology called "Walking Noise" that allows to assess the robustness of different layers of deep architectures by means of a so-called "midpoint noise level" metric. We then investigate the implications of additive and multiplicative noise for different classification tasks and model architectures, with and without batch normalization. While noisy training significantly increases robustness for both noise types, we observe a clear trend to increase weights and thus increase the signal-to-noise ratio for additive noise injection. For the multiplicative case, we find that some networks, with suitably simple tasks, automatically learn an internal binary representation, hence becoming extremely robust. Overall this work proposes a method to measure the layer-specific robustness and shares first insights on how networks learn to compensate injected noise, and thus, contributes to understand robustness against noisy computations.
Towards Hardware-Specific Automatic Compression of Neural Networks
Dec 15, 2022Compressing neural network architectures is important to allow the deployment of models to embedded or mobile devices, and pruning and quantization are the major approaches to compress neural networks nowadays. Both methods benefit when compression parameters are selected specifically for each layer. Finding good combinations of compression parameters, so-called compression policies, is hard as the problem spans an exponentially large search space. Effective compression policies consider the influence of the specific hardware architecture on the used compression methods. We propose an algorithmic framework called Galen to search such policies using reinforcement learning utilizing pruning and quantization, thus providing automatic compression for neural networks. Contrary to other approaches we use inference latency measured on the target hardware device as an optimization goal. With that, the framework supports the compression of models specific to a given hardware target. We validate our approach using three different reinforcement learning agents for pruning, quantization and joint pruning and quantization. Besides proving the functionality of our approach we were able to compress a ResNet18 for CIFAR-10, on an embedded ARM processor, to 20% of the original inference latency without significant loss of accuracy. Moreover, we can demonstrate that a joint search and compression using pruning and quantization is superior to an individual search for policies using a single compression method.
Understanding Cache Boundness of ML Operators on ARM Processors
Feb 01, 2021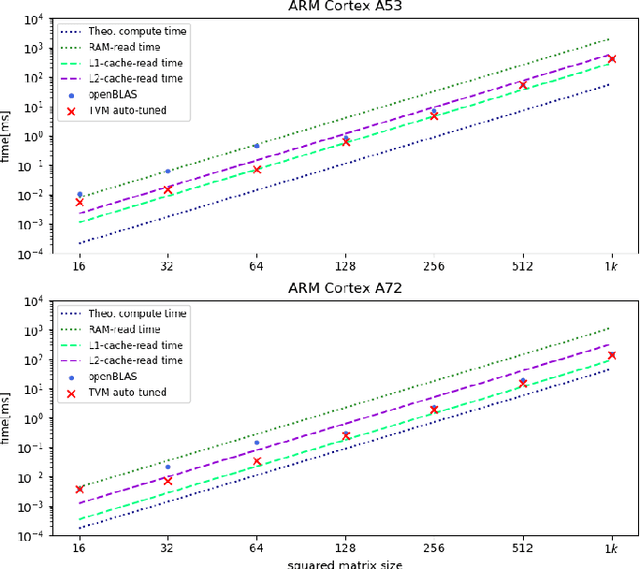
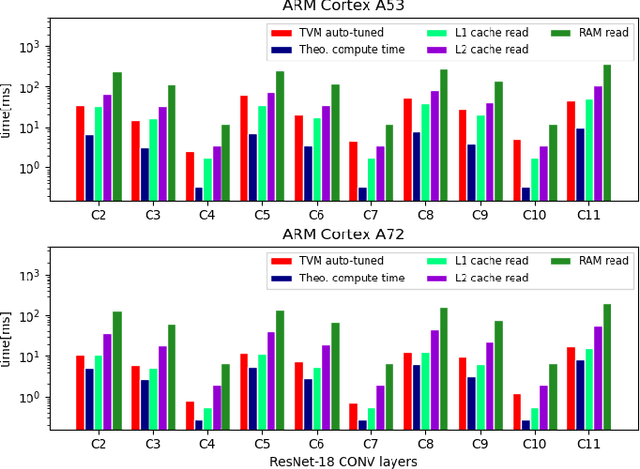
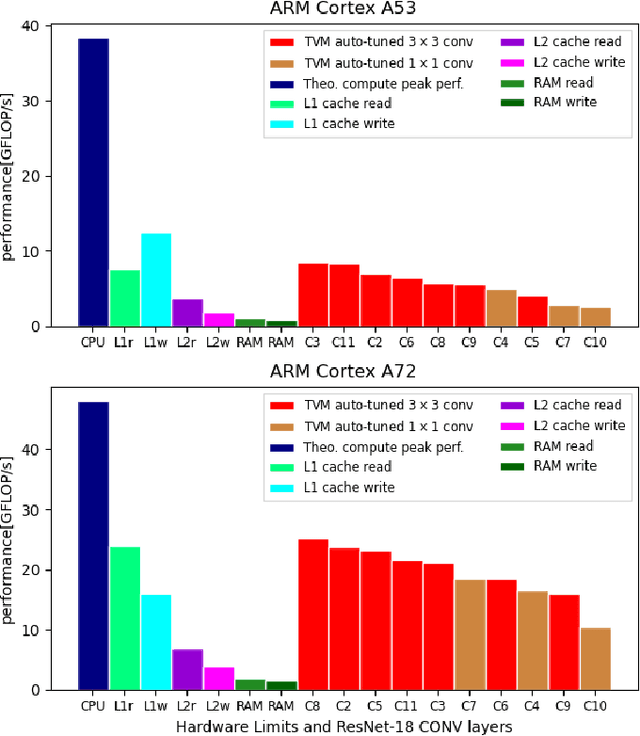
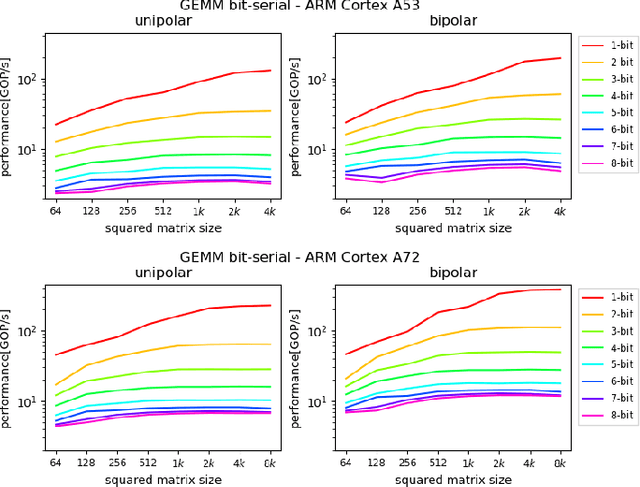
Machine Learning compilers like TVM allow a fast and flexible deployment on embedded CPUs. This enables the use of non-standard operators, which are common in ML compression techniques. However, it is necessary to understand the limitations of typical compute-intense operators in ML workloads to design a proper solution. This is the first in-detail analysis of dense and convolution operators, generated with TVM, that compares to the fundamental hardware limits of embedded ARM processors. Thereby it explains the gap between computational peak performance, theoretical and measured, and real-world state-of-the-art results, created with TVM and openBLAS. Instead, one can see that single-precision general matrix multiply (GEMM) and convolutions are bound by L1-cache-read bandwidth. Explorations of 8-bit and bit-serial quantized operators show that quantization can be used to achieve relevant speedups compared to cache-bound floating-point operators. However, the performance of quantized operators highly depends on the interaction between data layout and bit packing.