 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressed Hierarchical Representations for Multi-Task Learning and Task Clustering
May 31, 2022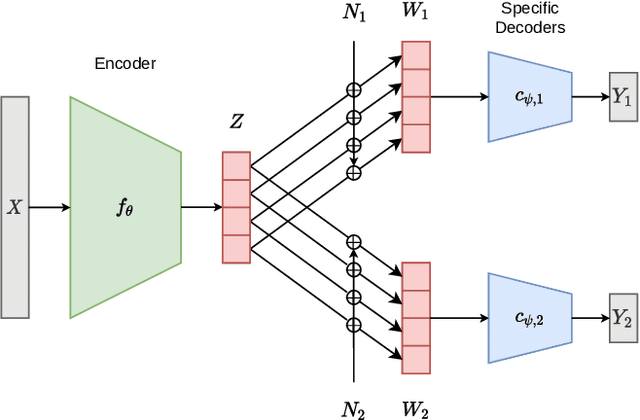

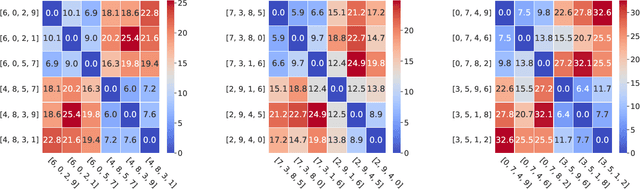

In this paper, we frame homogeneous-feature multi-task learning (MTL) as a hierarchical representation learning problem, with one task-agnostic and multiple task-specific latent representations. Drawing inspiration from the information bottleneck principle and assuming an additive independent noise model between the task-agnostic and task-specific latent representations, we limit the information contained in each task-specific representation. It is shown that our resulting representations yield competitive performance for several MTL benchmarks. Furthermore, for certain setups, we show that the trained parameters of the additive noise model are closely related to the similarity of different tasks. This indicates that our approach yields a task-agnostic representation that is disentangled in the sense that its individual dimensions may be interpretable from a task-specific perspective.
Understanding Cache Boundness of ML Operators on ARM Processors
Feb 01, 2021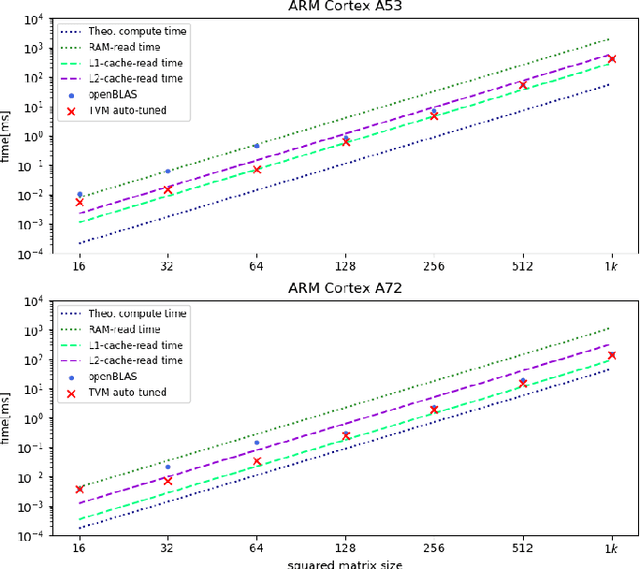
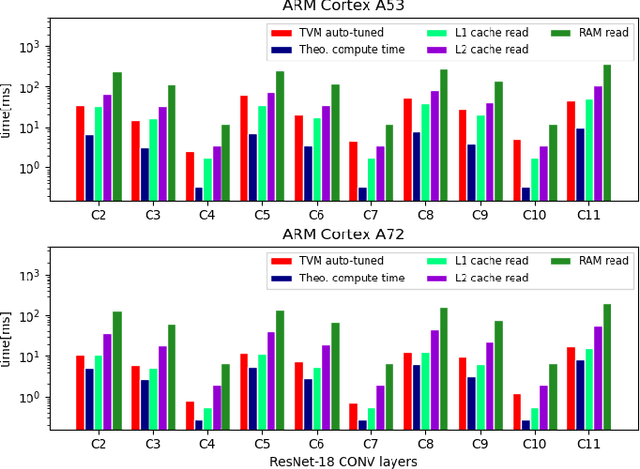
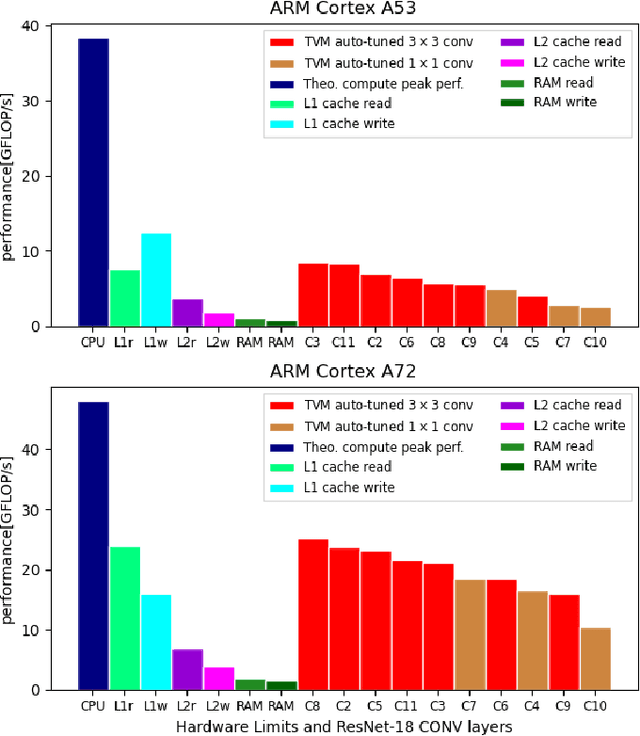
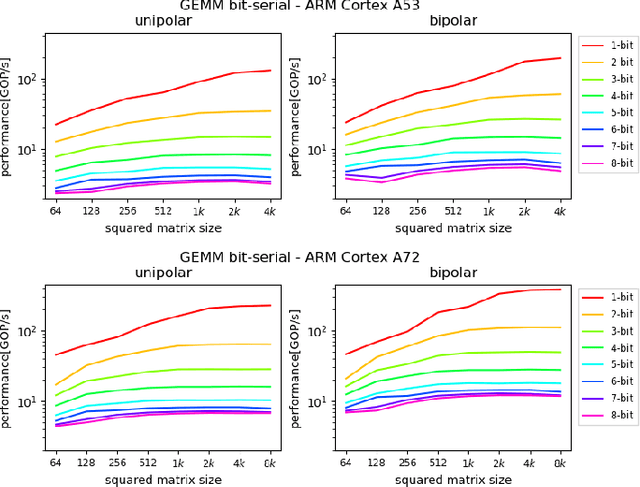
Machine Learning compilers like TVM allow a fast and flexible deployment on embedded CPUs. This enables the use of non-standard operators, which are common in ML compression techniques. However, it is necessary to understand the limitations of typical compute-intense operators in ML workloads to design a proper solution. This is the first in-detail analysis of dense and convolution operators, generated with TVM, that compares to the fundamental hardware limits of embedded ARM processors. Thereby it explains the gap between computational peak performance, theoretical and measured, and real-world state-of-the-art results, created with TVM and openBLAS. Instead, one can see that single-precision general matrix multiply (GEMM) and convolutions are bound by L1-cache-read bandwidth. Explorations of 8-bit and bit-serial quantized operators show that quantization can be used to achieve relevant speedups compared to cache-bound floating-point operators. However, the performance of quantized operators highly depends on the interaction between data layout and bit packing.