 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance-Aware Noisy Training: Hardening DNNs against Unstable Analog Computations
Paper and Code
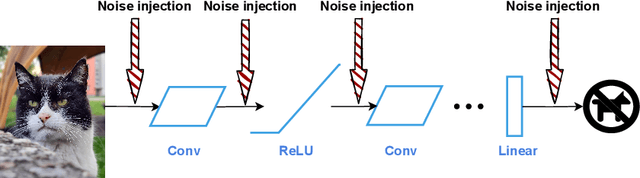
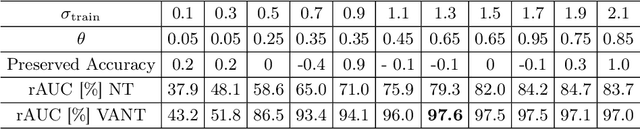
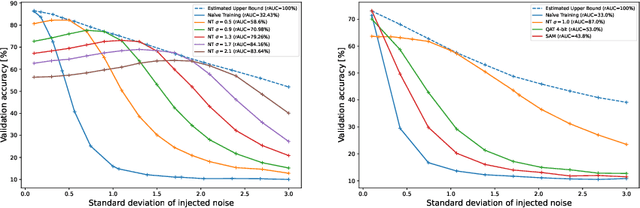
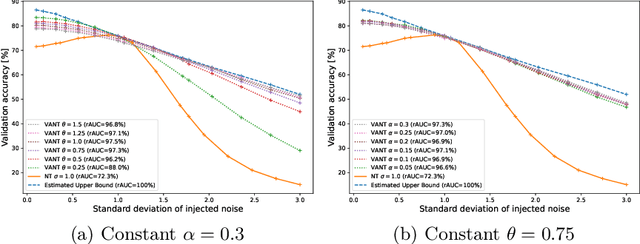
The disparity between the computational demands of deep learning and the capabilities of compute hardware is expanding drastically. Although deep learning achieves remarkable performance in countless tasks, its escalating requirements for computational power and energy consumption surpass the sustainable limits of even specialized neural processing units, including the Apple Neural Engine and NVIDIA TensorCores. This challenge is intensified by the slowdown in CMOS scaling. Analog computing presents a promising alternative, offering substantial improvements in energy efficiency by directly manipulating physical quantities such as current, voltage, charge, or photons. However, it is inherently vulnerable to manufacturing variations, nonlinearities, and noise, leading to degraded prediction accuracy. One of the most effective techniques for enhancing robustness, Noisy Training, introduces noise during the training phase to reinforce the model against disturbances encountered during inference. Although highly effective, its performance degrades in real-world environments where noise characteristics fluctuate due to external factors such as temperature variations and temporal drift. This study underscores the necessity of Noisy Training while revealing its fundamental limitations in the presence of dynamic noise. To address these challenges, we propose Variance-Aware Noisy Training, a novel approach that mitigates performance degradation by incorporating noise schedules which emulate the evolving noise conditions encountered during inference. Our method substantially improves model robustness, without training overhead. We demonstrate a significant increase in robustness, from 72.3\% with conventional Noisy Training to 97.3\% with Variance-Aware Noisy Training on CIFAR-10 and from 38.5\% to 89.9\% on Tiny ImageNet.