 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Automated Inspection of Opaque Liquid Vaccines
Feb 21, 2020



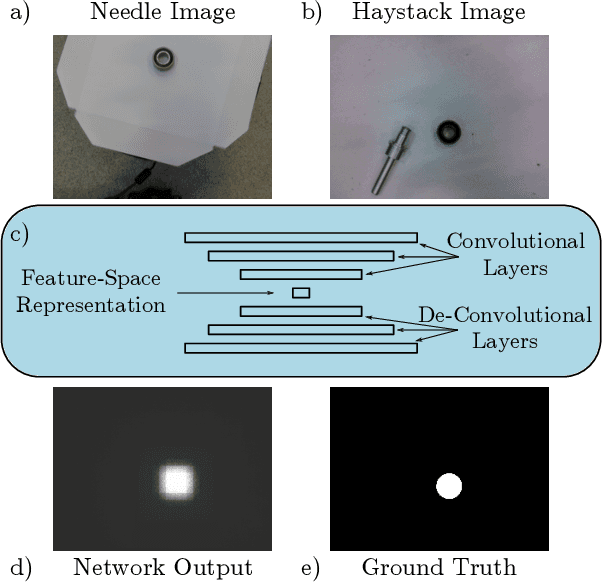
In the pharmaceutical industry the screening of opaque vaccines containing suspensions is currently a manual task carried out by trained human visual inspectors. We show that deep learning can be used to effectively automate this process. A moving contrast is required to distinguish anomalies from other particles, reflections and dust resting on a vial's surface. We train 3D-ConvNets to predict the likelihood of 20-frame video samples containing anomalies. Our unaugmented dataset consists of hand-labelled samples, recorded using vials provided by the HAL Allergy Group, a pharmaceutical company. We trained ten randomly initialized 3D-ConvNets to provide a benchmark, observing mean AUROC scores of 0.94 and 0.93 for positive samples (containing anomalies) and negative (anomaly-free) samples, respectively. Using Frame-Completion Generative Adversarial Networks we: (i) introduce an algorithm for computing saliency maps, which we use to verify that the 3D-ConvNets are indeed identifying anomalies; (ii) propose a novel self-training approach using the saliency maps to determine if multiple networks agree on the location of anomalies. Our self-training approach allows us to augment our data set by labelling 217,888 additional samples. 3D-ConvNets trained with our augmented dataset improve on the results we get when we train only on the unaugmented dataset.
Fully Convolutional One-Shot Object Segmentation for Industrial Robotics
Mar 02, 2019
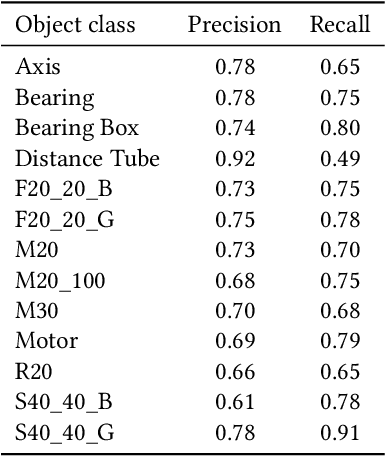
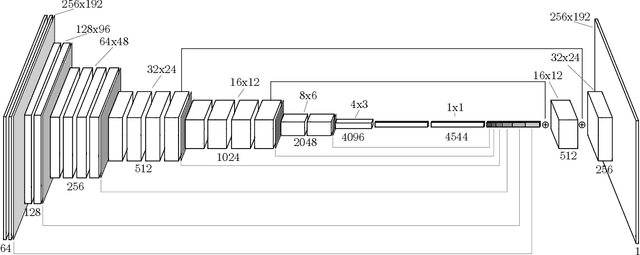
The ability to identify and localize new objects robustly and effectively is vital for robotic grasping and manipulation in warehouses or smart factories. Deep convolutional neural networks (DCNNs) have achieved the state-of-the-art performance on established image datasets for object detection and segmentation. However, applying DCNNs in dynamic industrial scenarios, e.g., warehouses and autonomous production, remains a challenging problem. DCNNs quickly become ineffective when tasked with detecting objects that they have not been trained on. Given that re-training using the latest data is time consuming, DCNNs cannot meet the requirement of the Factory of the Future (FoF) regarding rapid development and production cycles. To address this problem, we propose a novel one-shot object segmentation framework, using a fully convolutional Siamese network architecture, to detect previously unknown objects based on a single prototype image. We turn to multi-task learning to reduce training time and improve classification accuracy. Furthermore, we introduce a novel approach to automatically cluster the learnt feature space representation in a weakly supervised manner. We test the proposed framework on the RoboCup@Work dataset, simulating requirements for the FoF. Results show that the trained network on average identifies 73% of previously unseen objects correctly from a single example image. Correctly identified objects are estimated to have a 87.53% successful pick-up rate. Finally, multi-task learning lowers the convergence time by up to 33%, and increases accuracy by 2.99%.
Fast Convergence for Object Detection by Learning how to Combine Error Functions
Aug 13, 2018
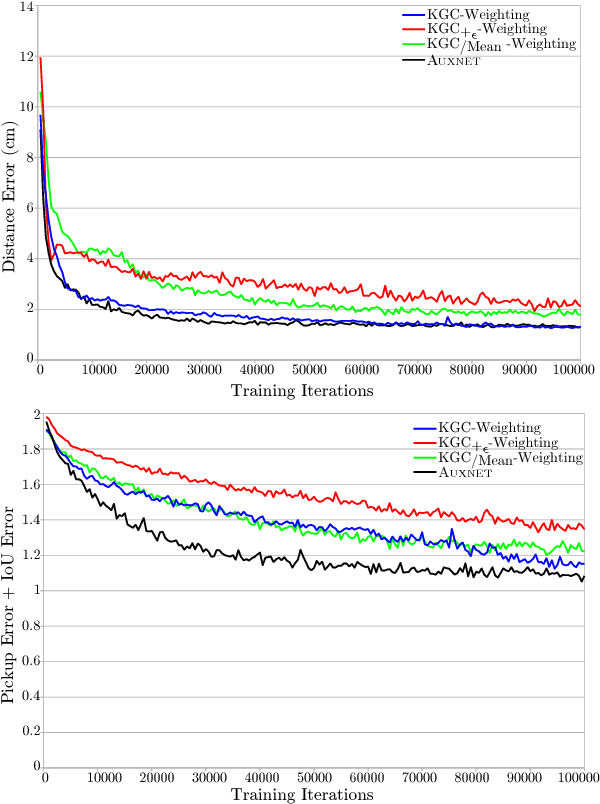
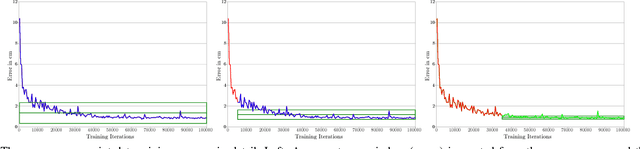
In this paper, we introduce an innovative method to improve the convergence speed and accuracy of object detection neural networks. Our approach, CONVERGE-FAST-AUXNET, is based on employing multiple, dependent loss metrics and weighting them optimally using an on-line trained auxiliary network. Experiments are performed in the well-known RoboCup@Work challenge environment. A fully convolutional segmentation network is trained on detecting objects' pickup points. We empirically obtain an approximate measure for the rate of success of a robotic pickup operation based on the accuracy of the object detection network. Our experiments show that adding an optimally weighted Euclidean distance loss to a network trained on the commonly used Intersection over Union (IoU) metric reduces the convergence time by 42.48%. The estimated pickup rate is improved by 39.90%. Compared to state-of-the-art task weighting methods, the improvement is 24.5% in convergence, and 15.8% on the estimated pickup rate.