 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing the State-of-the-Art to Customers: A Neural Agent Assistant Framework for Customer Service Support
Feb 07, 2023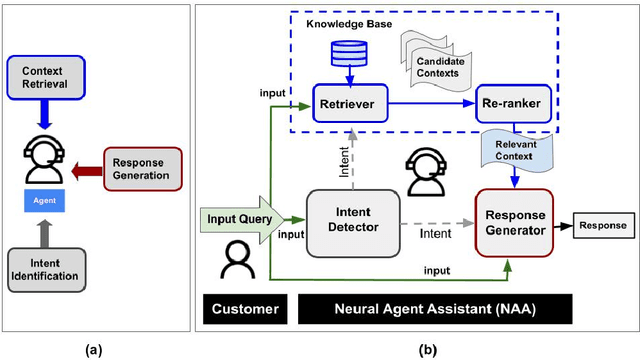
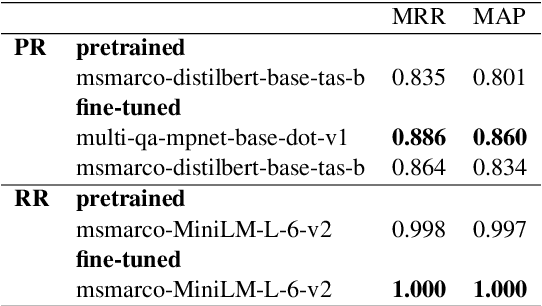
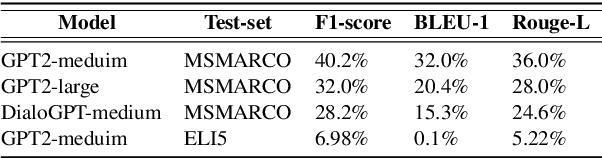
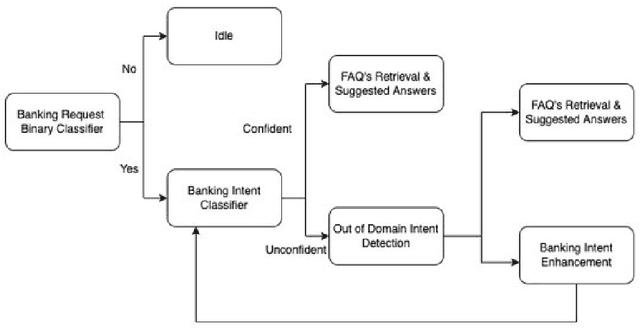
Building Agent Assistants that can help improve customer service support requires inputs from industry users and their customers, as well as knowledge about state-of-the-art Natural Language Processing (NLP) technology. We combine expertise from academia and industry to bridge the gap and build task/domain-specific Neural Agent Assistants (NAA) with three high-level components for: (1) Intent Identification, (2) Context Retrieval, and (3) Response Generation. In this paper, we outline the pipeline of the NAA's core system and also present three case studies in which three industry partners successfully adapt the framework to find solutions to their unique challenges. Our findings suggest that a collaborative process is instrumental in spurring the development of emerging NLP models for Conversational AI tasks in industry. The full reference implementation code and results are available at \url{https://github.com/VectorInstitute/NAA}
Effective user intent mining with unsupervised word representation models and topic modelling
Sep 04, 2021
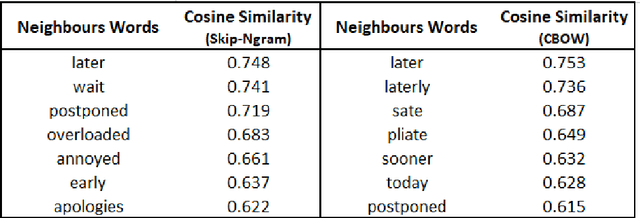


Understanding the intent behind chat between customers and customer service agents has become a crucial problem nowadays due to an exponential increase in the use of the Internet by people from different cultures and educational backgrounds. More importantly, the explosion of e-commerce has led to a significant increase in text conversation between customers and agents. In this paper, we propose an approach to data mining the conversation intents behind the textual data. Using the customer service data set, we train unsupervised text representation models, and then develop an intent mapping model which would rank the predefined intents base on cosine similarity between sentences and intents. Topic-modeling techniques are used to define intents and domain experts are also involved to interpret topic modelling results. With this approach, we can get a good understanding of the user intentions behind the unlabelled customer service textual data.
Offensive Language and Hate Speech Detection with Deep Learning and Transfer Learning
Aug 23, 2021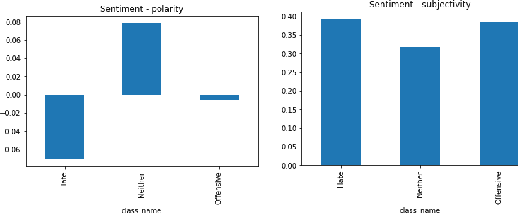


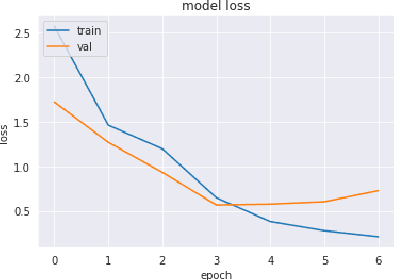
Toxic online speech has become a crucial problem nowadays due to an exponential increase in the use of internet by people from different cultures and educational backgrounds. Differentiating if a text message belongs to hate speech and offensive language is a key challenge in automatic detection of toxic text content. In this paper, we propose an approach to automatically classify tweets into three classes: Hate, offensive and Neither. Using public tweet data set, we first perform experiments to build BI-LSTM models from empty embedding and then we also try the same neural network architecture with pre-trained Glove embedding. Next, we introduce a transfer learning approach for hate speech detection using an existing pre-trained language model BERT (Bidirectional Encoder Representations from Transformers), DistilBert (Distilled version of BERT) and GPT-2 (Generative Pre-Training). We perform hyper parameters tuning analysis of our best model (BI-LSTM) considering different neural network architectures, learn-ratings and normalization methods etc. After tuning the model and with the best combination of parameters, we achieve over 92 percent accuracy upon evaluating it on test data. We also create a class module which contains main functionality including text classification, sentiment checking and text data augmentation. This model could serve as an intermediate module between user and Twitter.