 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound Signal Processing: From Models to Deep Learning
Apr 09, 2022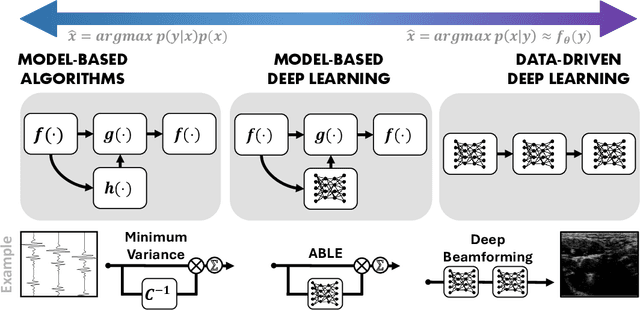
Medical ultrasound imaging relies heavily on high-quality signal processing algorithms to provide reliable and interpretable image reconstructions. Hand-crafted reconstruction methods, often based on approximations of the underlying measurement model, are useful in practice, but notoriously fall behind in terms of image quality. More sophisticated solutions, based on statistical modelling, careful parameter tuning, or through increased model complexity, can be sensitive to different environments. Recently, deep learning based methods have gained popularity, which are optimized in a data-driven fashion. These model-agnostic methods often rely on generic model structures, and require vast training data to converge to a robust solution. A relatively new paradigm combines the power of the two: leveraging data-driven deep learning, as well as exploiting domain knowledge. These model-based solutions yield high robustness, and require less trainable parameters and training data than conventional neural networks. In this work we provide an overview of these methods from the recent literature, and discuss a wide variety of ultrasound applications. We aim to inspire the reader to further research in this area, and to address the opportunities within the field of ultrasound signal processing. We conclude with a future perspective on these model-based deep learning techniques for medical ultrasound applications.
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Deep Proximal Learning for High-Resolution Plane Wave Compounding
Dec 23, 2021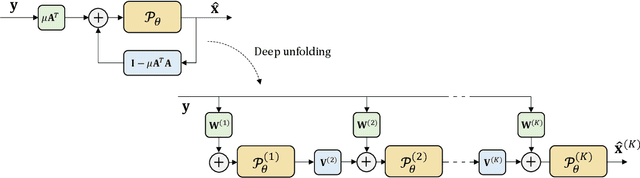
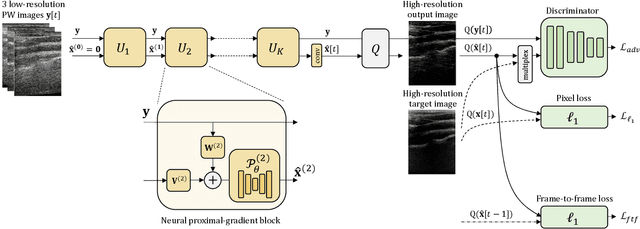
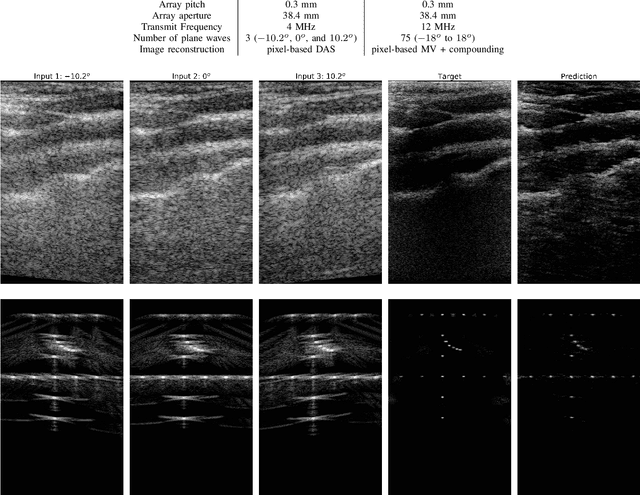
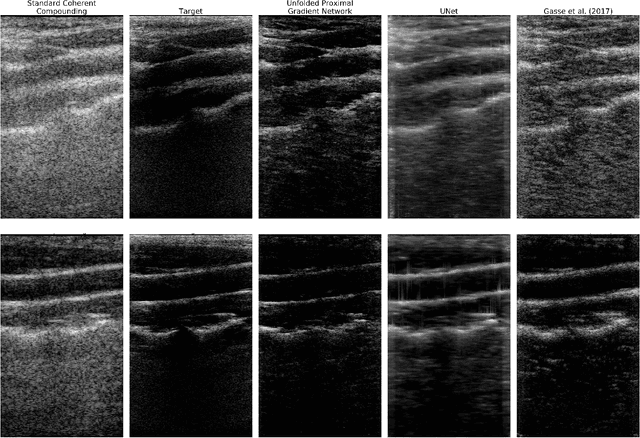
Plane Wave imaging enables many applications that require high frame rates, including localisation microscopy, shear wave elastography, and ultra-sensitive Doppler. To alleviate the degradation of image quality with respect to conventional focused acquisition, typically, multiple acquisitions from distinctly steered plane waves are coherently (i.e. after time-of-flight correction) compounded into a single image. This poses a trade-off between image quality and achievable frame-rate. To that end, we propose a new deep learning approach, derived by formulating plane wave compounding as a linear inverse problem, that attains high resolution, high-contrast images from just 3 plane wave transmissions. Our solution unfolds the iterations of a proximal gradient descent algorithm as a deep network, thereby directly exploiting the physics-based generative acquisition model into the neural network design. We train our network in a greedy manner, i.e. layer-by-layer, using a combination of pixel, temporal, and distribution (adversarial) losses to achieve both perceptual fidelity and data consistency. Through the strong model-based inductive bias, the proposed architecture outperforms several standard benchmark architectures in terms of image quality, with a low computational and memory footprint.