 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBReG-NeXt: Facial Affect Computing Using Adaptive Residual Networks With Bounded Gradient
Apr 18, 2020
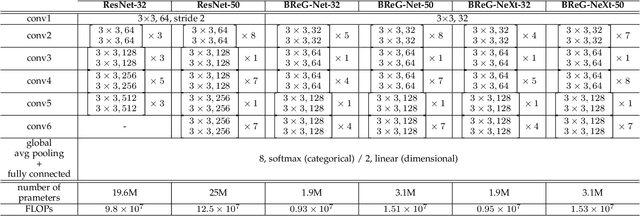
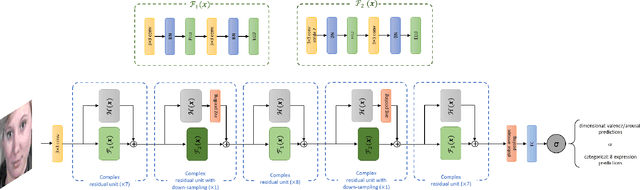

This paper introduces BReG-NeXt, a residual-based network architecture using a function wtih bounded derivative instead of a simple shortcut path (a.k.a. identity mapping) in the residual units for automatic recognition of facial expressions based on the categorical and dimensional models of affect. Compared to ResNet, our proposed adaptive complex mapping results in a shallower network with less numbers of training parameters and floating point operations per second (FLOPs). Adding trainable parameters to the bypass function further improves fitting and training the network and hence recognizing subtle facial expressions such as contempt with a higher accuracy. We conducted comprehensive experiments on the categorical and dimensional models of affect on the challenging in-the-wild databases of AffectNet, FER2013, and Affect-in-Wild. Our experimental results show that our adaptive complex mapping approach outperforms the original ResNet consisting of a simple identity mapping as well as other state-of-the-art methods for Facial Expression Recognition (FER). Various metrics are reported in both affect models to provide a comprehensive evaluation of our method. In the categorical model, BReG-NeXt-50 with only 3.1M training parameters and 15 MFLOPs, achieves 68.50% and 71.53% accuracy on AffectNet and FER2013 databases, respectively. In the dimensional model, BReG-NeXt achieves 0.2577 and 0.2882 RMSE value on AffectNet and Affect-in-Wild databases, respectively.
Bounded Residual Gradient Networks (BReG-Net) for Facial Affect Computing
Mar 05, 2019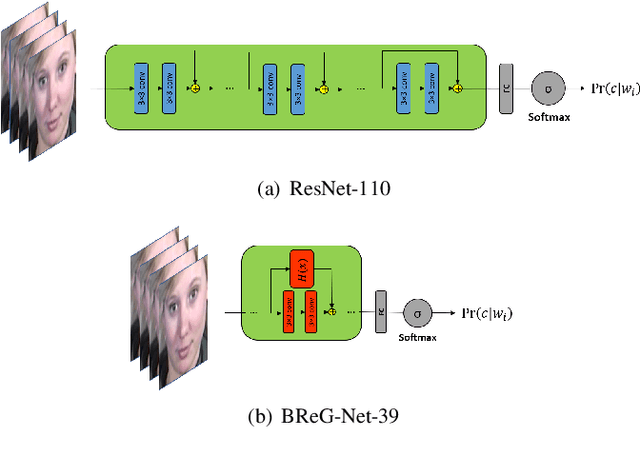
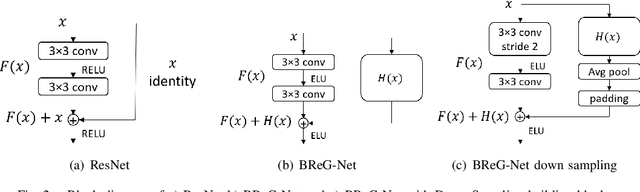
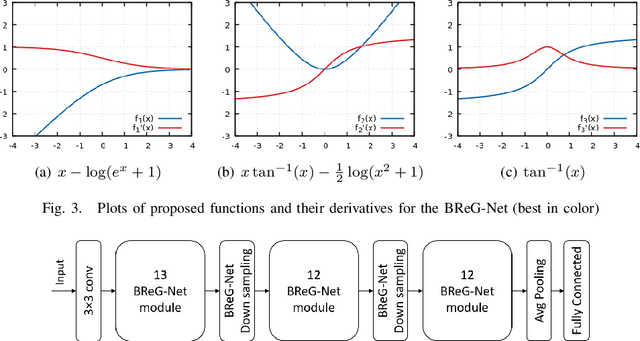
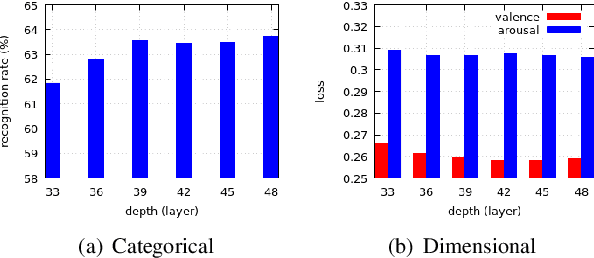
Residual-based neural networks have shown remarkable results in various visual recognition tasks including Facial Expression Recognition (FER). Despite the tremendous efforts have been made to improve the performance of FER systems using DNNs, existing methods are not generalizable enough for practical applications. This paper introduces Bounded Residual Gradient Networks (BReG-Net) for facial expression recognition, in which the shortcut connection between the input and the output of the ResNet module is replaced with a differentiable function with a bounded gradient. This configuration prevents the network from facing the vanishing or exploding gradient problem. We show that utilizing such non-linear units will result in shallower networks with better performance. Further, by using a weighted loss function which gives a higher priority to less represented categories, we can achieve an overall better recognition rate. The results of our experiments show that BReG-Nets outperform state-of-the-art methods on three publicly available facial databases in the wild, on both the categorical and dimensional models of affect.
AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild
Oct 09, 2017
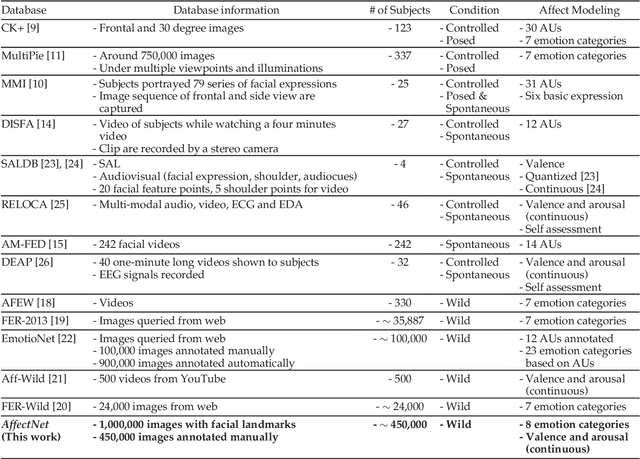
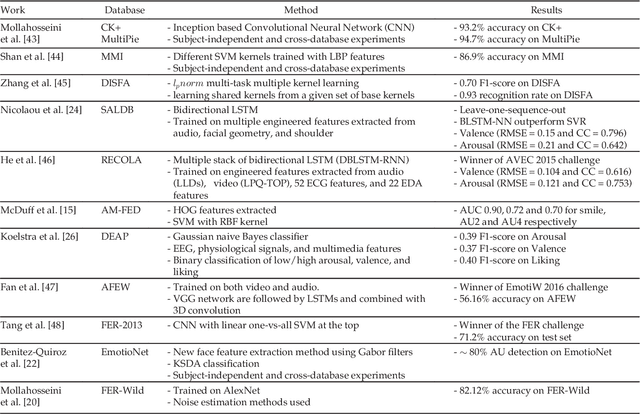
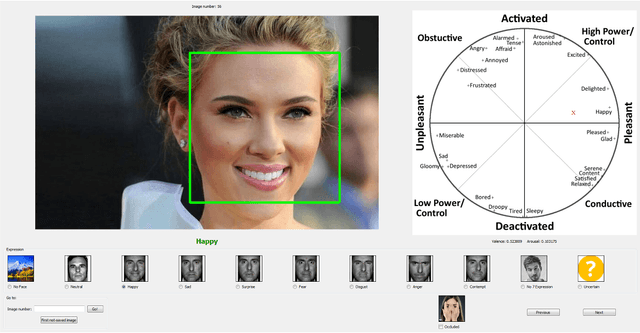
Automated affective computing in the wild setting is a challenging problem in computer vision. Existing annotated databases of facial expressions in the wild are small and mostly cover discrete emotions (aka the categorical model). There are very limited annotated facial databases for affective computing in the continuous dimensional model (e.g., valence and arousal). To meet this need, we collected, annotated, and prepared for public distribution a new database of facial emotions in the wild (called AffectNet). AffectNet contains more than 1,000,000 facial images from the Internet by querying three major search engines using 1250 emotion related keywords in six different languages. About half of the retrieved images were manually annotated for the presence of seven discrete facial expressions and the intensity of valence and arousal. AffectNet is by far the largest database of facial expression, valence, and arousal in the wild enabling research in automated facial expression recognition in two different emotion models. Two baseline deep neural networks are used to classify images in the categorical model and predict the intensity of valence and arousal. Various evaluation metrics show that our deep neural network baselines can perform better than conventional machine learning methods and off-the-shelf facial expression recognition systems.
Facial Affect Estimation in the Wild Using Deep Residual and Convolutional Networks
May 22, 2017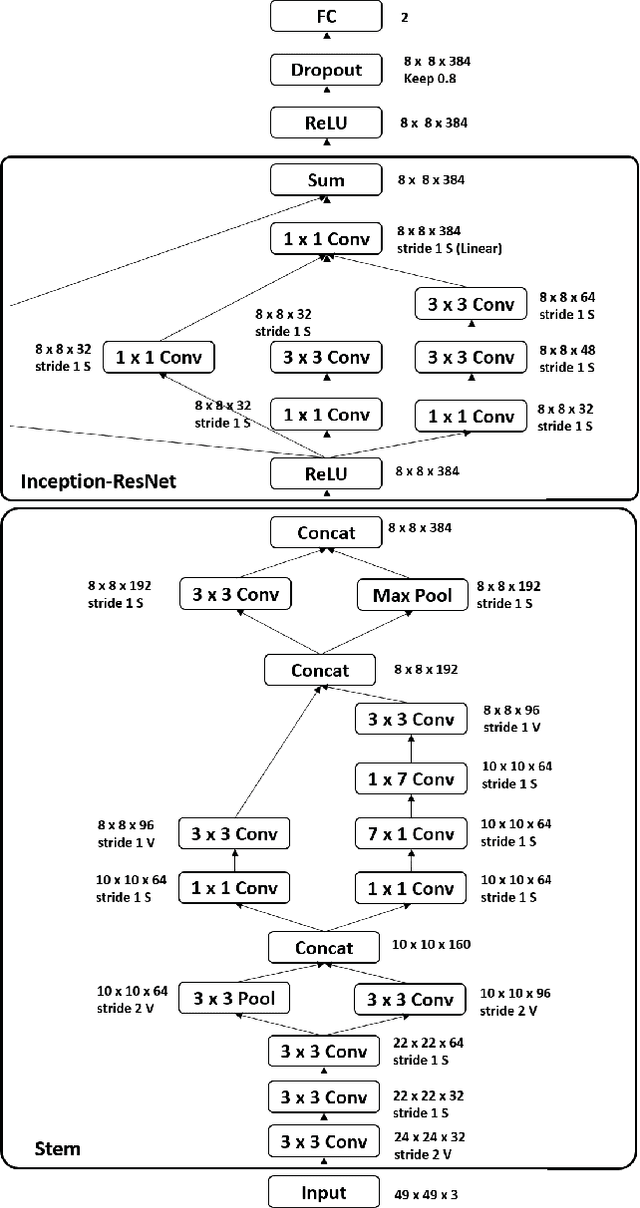

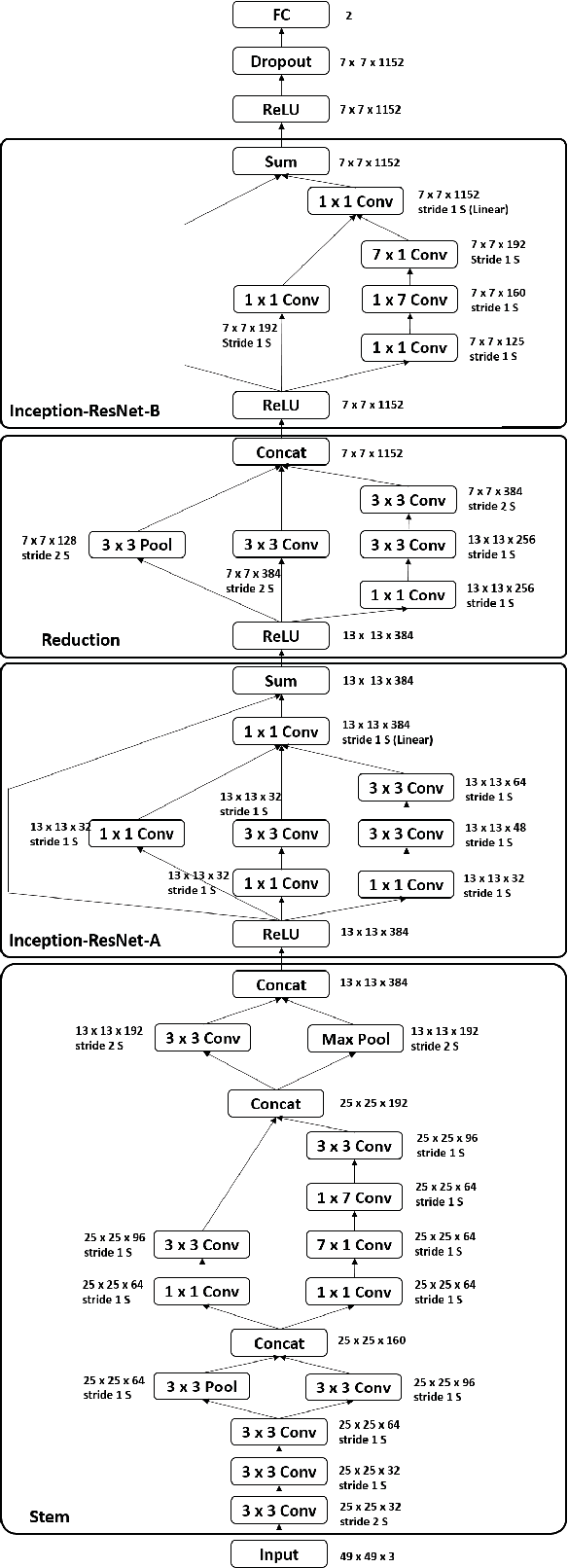
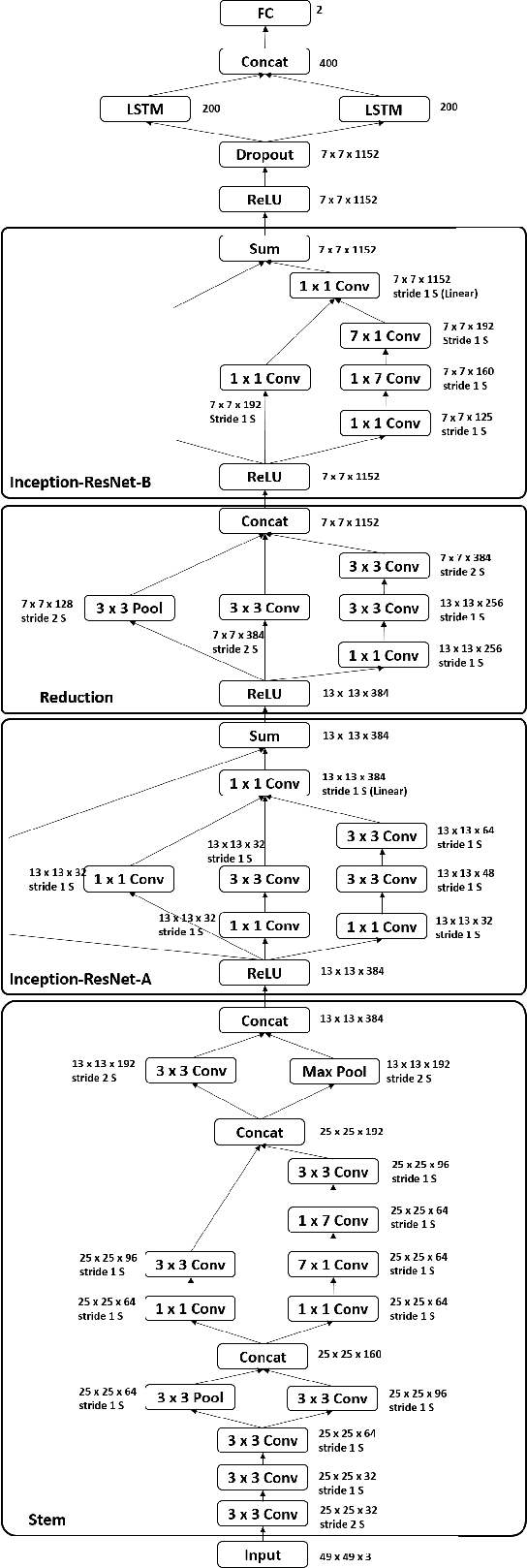
Automated affective computing in the wild is a challenging task in the field of computer vision. This paper presents three neural network-based methods proposed for the task of facial affect estimation submitted to the First Affect-in-the-Wild challenge. These methods are based on Inception-ResNet modules redesigned specifically for the task of facial affect estimation. These methods are: Shallow Inception-ResNet, Deep Inception-ResNet, and Inception-ResNet with LSTMs. These networks extract facial features in different scales and simultaneously estimate both the valence and arousal in each frame. Root Mean Square Error (RMSE) rates of 0.4 and 0.3 are achieved for the valence and arousal respectively with corresponding Concordance Correlation Coefficient (CCC) rates of 0.04 and 0.29 using Deep Inception-ResNet method.
Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks
May 22, 2017
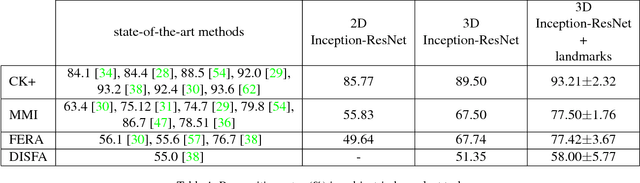


Deep Neural Networks (DNNs) have shown to outperform traditional methods in various visual recognition tasks including Facial Expression Recognition (FER). In spite of efforts made to improve the accuracy of FER systems using DNN, existing methods still are not generalizable enough in practical applications. This paper proposes a 3D Convolutional Neural Network method for FER in videos. This new network architecture consists of 3D Inception-ResNet layers followed by an LSTM unit that together extracts the spatial relations within facial images as well as the temporal relations between different frames in the video. Facial landmark points are also used as inputs to our network which emphasize on the importance of facial components rather than the facial regions that may not contribute significantly to generating facial expressions. Our proposed method is evaluated using four publicly available databases in subject-independent and cross-database tasks and outperforms state-of-the-art methods.
Spatio-Temporal Facial Expression Recognition Using Convolutional Neural Networks and Conditional Random Fields
Apr 24, 2017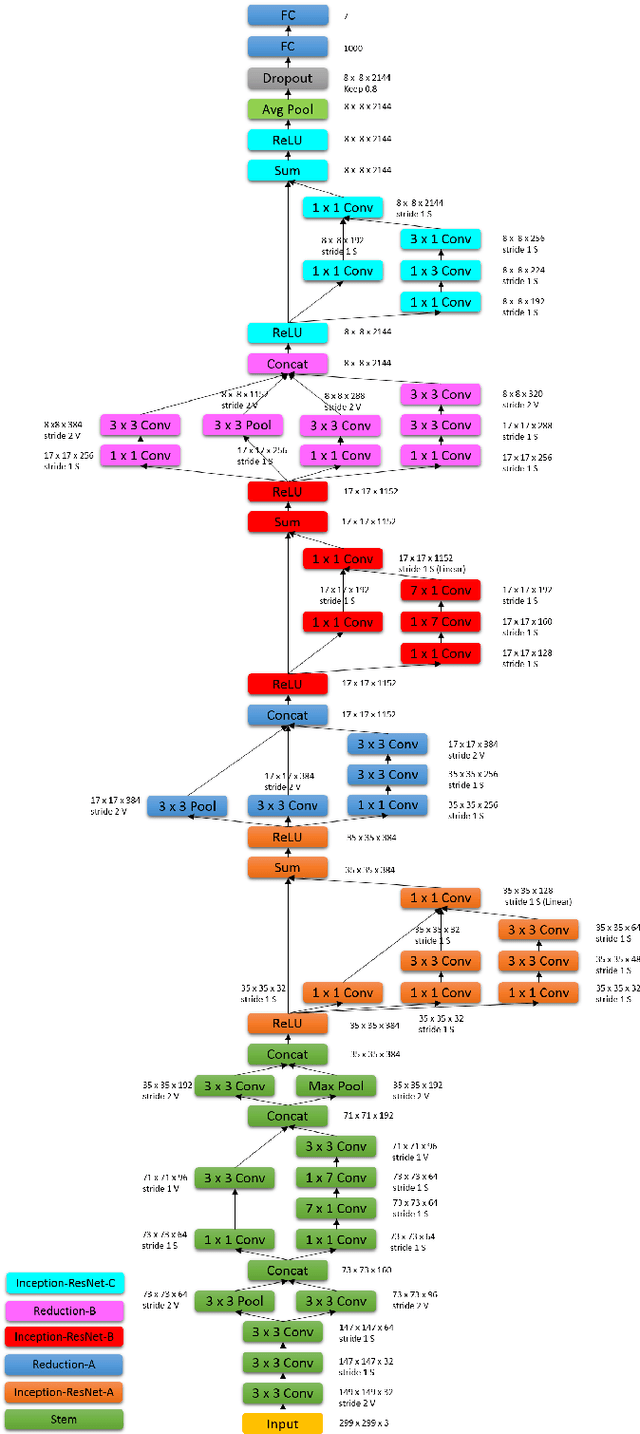
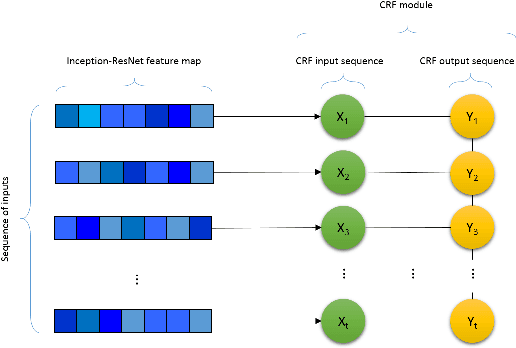
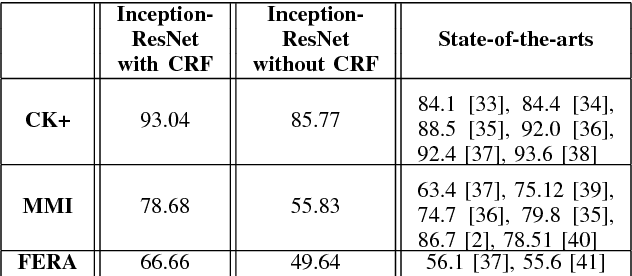
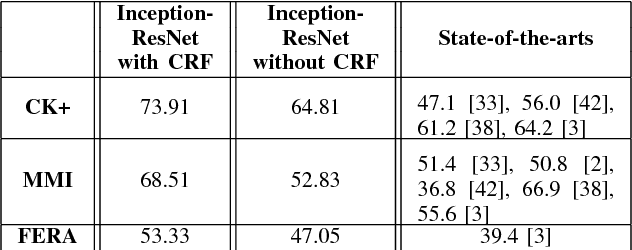
Automated Facial Expression Recognition (FER) has been a challenging task for decades. Many of the existing works use hand-crafted features such as LBP, HOG, LPQ, and Histogram of Optical Flow (HOF) combined with classifiers such as Support Vector Machines for expression recognition. These methods often require rigorous hyperparameter tuning to achieve good results. Recently Deep Neural Networks (DNN) have shown to outperform traditional methods in visual object recognition. In this paper, we propose a two-part network consisting of a DNN-based architecture followed by a Conditional Random Field (CRF) module for facial expression recognition in videos. The first part captures the spatial relation within facial images using convolutional layers followed by three Inception-ResNet modules and two fully-connected layers. To capture the temporal relation between the image frames, we use linear chain CRF in the second part of our network. We evaluate our proposed network on three publicly available databases, viz. CK+, MMI, and FERA. Experiments are performed in subject-independent and cross-database manners. Our experimental results show that cascading the deep network architecture with the CRF module considerably increases the recognition of facial expressions in videos and in particular it outperforms the state-of-the-art methods in the cross-database experiments and yields comparable results in the subject-independent experiments.