 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Facial Expression Recognition Using Convolutional Neural Networks and Conditional Random Fields
Paper and Code
Apr 24, 2017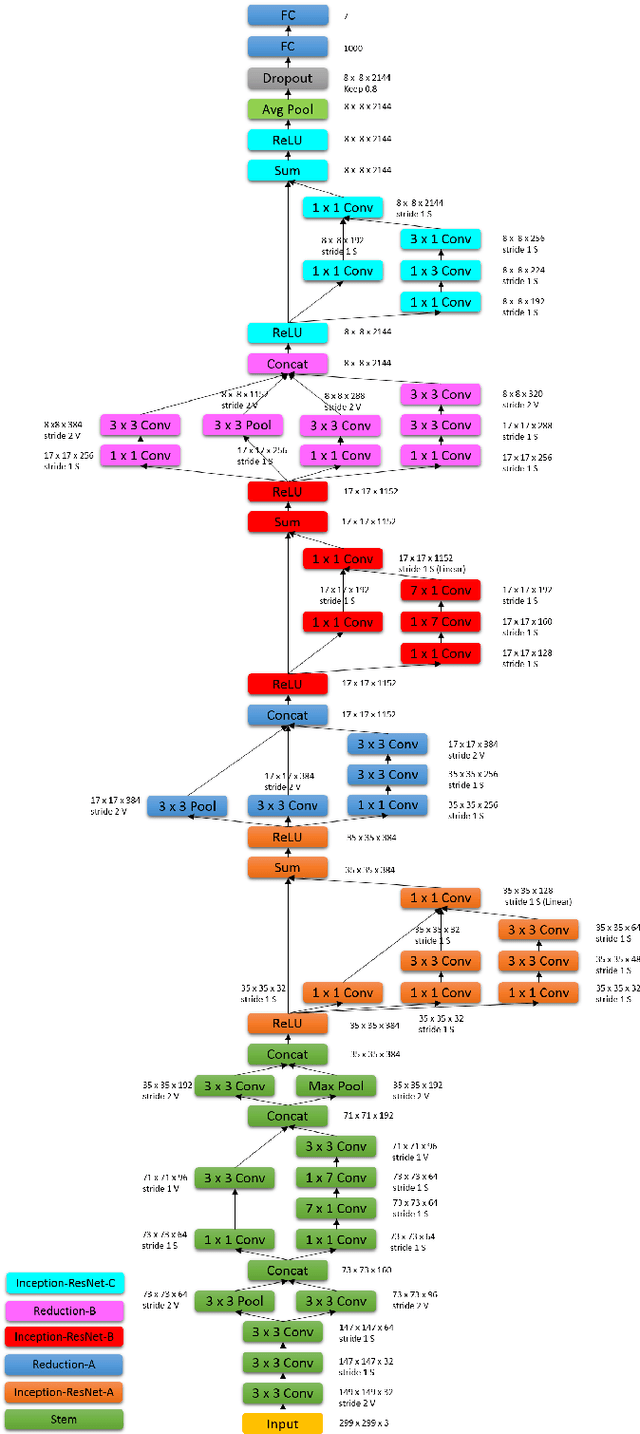
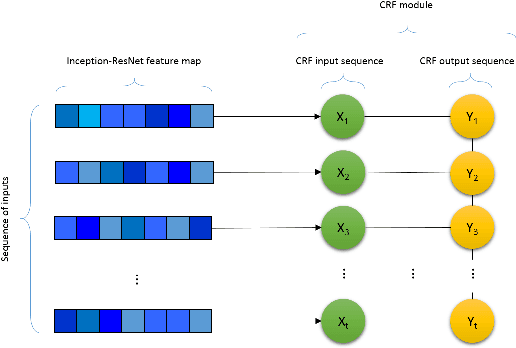
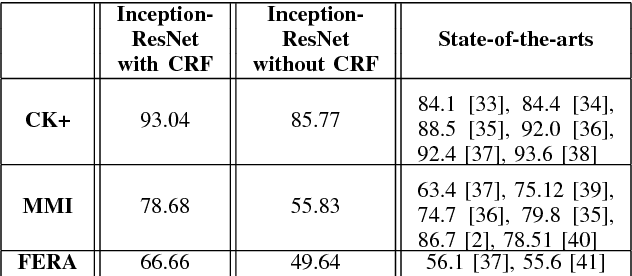
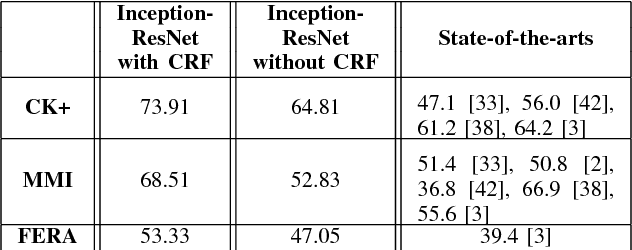
Automated Facial Expression Recognition (FER) has been a challenging task for decades. Many of the existing works use hand-crafted features such as LBP, HOG, LPQ, and Histogram of Optical Flow (HOF) combined with classifiers such as Support Vector Machines for expression recognition. These methods often require rigorous hyperparameter tuning to achieve good results. Recently Deep Neural Networks (DNN) have shown to outperform traditional methods in visual object recognition. In this paper, we propose a two-part network consisting of a DNN-based architecture followed by a Conditional Random Field (CRF) module for facial expression recognition in videos. The first part captures the spatial relation within facial images using convolutional layers followed by three Inception-ResNet modules and two fully-connected layers. To capture the temporal relation between the image frames, we use linear chain CRF in the second part of our network. We evaluate our proposed network on three publicly available databases, viz. CK+, MMI, and FERA. Experiments are performed in subject-independent and cross-database manners. Our experimental results show that cascading the deep network architecture with the CRF module considerably increases the recognition of facial expressions in videos and in particular it outperforms the state-of-the-art methods in the cross-database experiments and yields comparable results in the subject-independent experiments.