 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks
Paper and Code
May 22, 2017
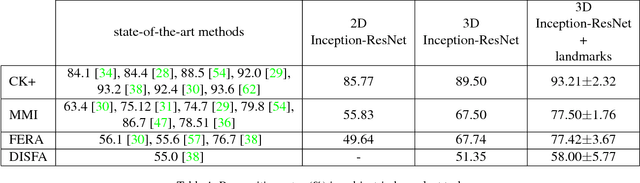


Deep Neural Networks (DNNs) have shown to outperform traditional methods in various visual recognition tasks including Facial Expression Recognition (FER). In spite of efforts made to improve the accuracy of FER systems using DNN, existing methods still are not generalizable enough in practical applications. This paper proposes a 3D Convolutional Neural Network method for FER in videos. This new network architecture consists of 3D Inception-ResNet layers followed by an LSTM unit that together extracts the spatial relations within facial images as well as the temporal relations between different frames in the video. Facial landmark points are also used as inputs to our network which emphasize on the importance of facial components rather than the facial regions that may not contribute significantly to generating facial expressions. Our proposed method is evaluated using four publicly available databases in subject-independent and cross-database tasks and outperforms state-of-the-art methods.