 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBReG-NeXt: Facial Affect Computing Using Adaptive Residual Networks With Bounded Gradient
Apr 18, 2020
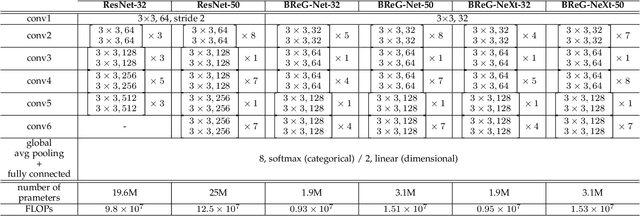
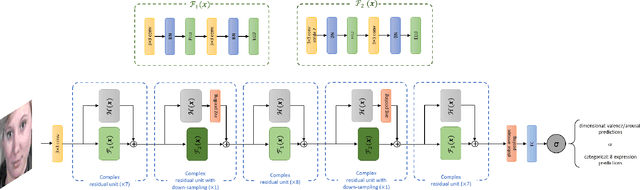

This paper introduces BReG-NeXt, a residual-based network architecture using a function wtih bounded derivative instead of a simple shortcut path (a.k.a. identity mapping) in the residual units for automatic recognition of facial expressions based on the categorical and dimensional models of affect. Compared to ResNet, our proposed adaptive complex mapping results in a shallower network with less numbers of training parameters and floating point operations per second (FLOPs). Adding trainable parameters to the bypass function further improves fitting and training the network and hence recognizing subtle facial expressions such as contempt with a higher accuracy. We conducted comprehensive experiments on the categorical and dimensional models of affect on the challenging in-the-wild databases of AffectNet, FER2013, and Affect-in-Wild. Our experimental results show that our adaptive complex mapping approach outperforms the original ResNet consisting of a simple identity mapping as well as other state-of-the-art methods for Facial Expression Recognition (FER). Various metrics are reported in both affect models to provide a comprehensive evaluation of our method. In the categorical model, BReG-NeXt-50 with only 3.1M training parameters and 15 MFLOPs, achieves 68.50% and 71.53% accuracy on AffectNet and FER2013 databases, respectively. In the dimensional model, BReG-NeXt achieves 0.2577 and 0.2882 RMSE value on AffectNet and Affect-in-Wild databases, respectively.
Bounded Residual Gradient Networks (BReG-Net) for Facial Affect Computing
Mar 05, 2019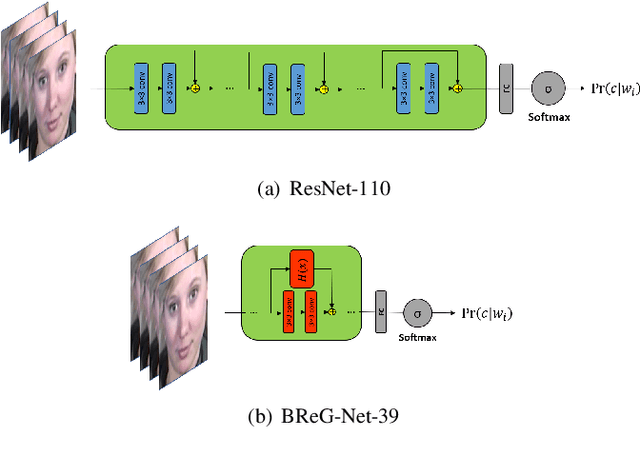
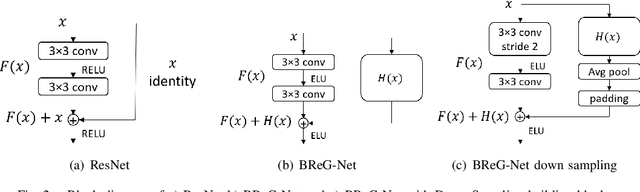
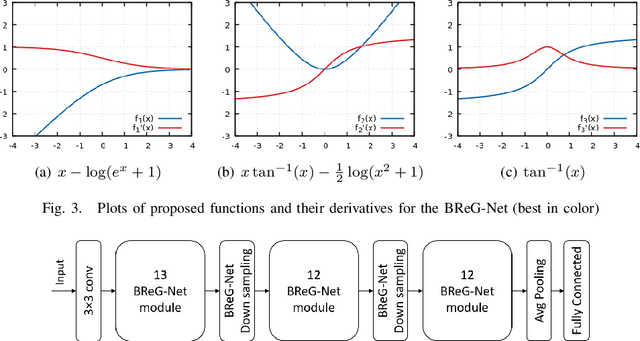
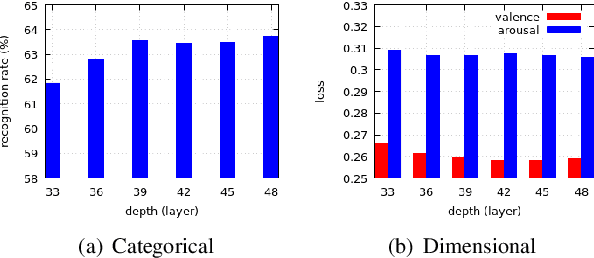
Residual-based neural networks have shown remarkable results in various visual recognition tasks including Facial Expression Recognition (FER). Despite the tremendous efforts have been made to improve the performance of FER systems using DNNs, existing methods are not generalizable enough for practical applications. This paper introduces Bounded Residual Gradient Networks (BReG-Net) for facial expression recognition, in which the shortcut connection between the input and the output of the ResNet module is replaced with a differentiable function with a bounded gradient. This configuration prevents the network from facing the vanishing or exploding gradient problem. We show that utilizing such non-linear units will result in shallower networks with better performance. Further, by using a weighted loss function which gives a higher priority to less represented categories, we can achieve an overall better recognition rate. The results of our experiments show that BReG-Nets outperform state-of-the-art methods on three publicly available facial databases in the wild, on both the categorical and dimensional models of affect.
Leveraging Class Similarity to Improve Deep Neural Network Robustness
Dec 27, 2018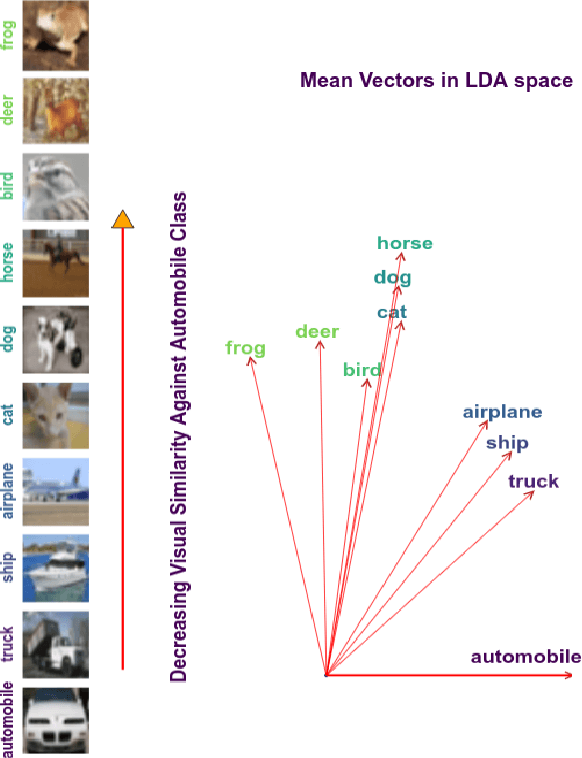
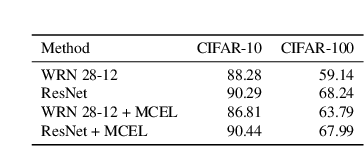

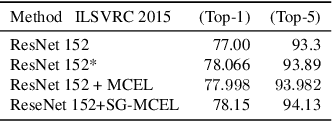
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross-entropy between a provided groundtruth delta distribution (encoded as one-hot vector) and the ANN's predictive softmax distribution. It seems, however, unacceptable to penalize networks equally for missclassification between classes. Confusing the class "Automobile" with the class "Truck" should be penalized less than confusing the class "Automobile" with the class "Donkey". To avoid such representation issues and learn cleaner classification boundaries in the network, this paper presents a variation of cross-entropy loss which depends not only on the sample class but also on a data-driven prior "class-similarity distribution" across the classes encoded in a matrix form. We explore learning the class-similarity distribution using a datadriven method and then show that by training with our modified similarity-driven loss, we obtain slightly better generalization performance over multiple architectures and datasets as well as improved performance on noisy testing scenarios.