 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bi-Encoder LSTM Model For Learning Unstructured Dialogs
Apr 25, 2021


Creating a data-driven model that is trained on a large dataset of unstructured dialogs is a crucial step in developing Retrieval-based Chatbot systems. This paper presents a Long Short Term Memory (LSTM) based architecture that learns unstructured multi-turn dialogs and provides results on the task of selecting the best response from a collection of given responses. Ubuntu Dialog Corpus Version 2 was used as the corpus for training. We show that our model achieves 0.8%, 1.0% and 0.3% higher accuracy for Recall@1, Recall@2 and Recall@5 respectively than the benchmark model. We also show results on experiments performed by using several similarity functions, model hyper-parameters and word embeddings on the proposed architecture
Deep Active Shape Model for Face Alignment and Pose Estimation in Mobile Environment
Mar 11, 2021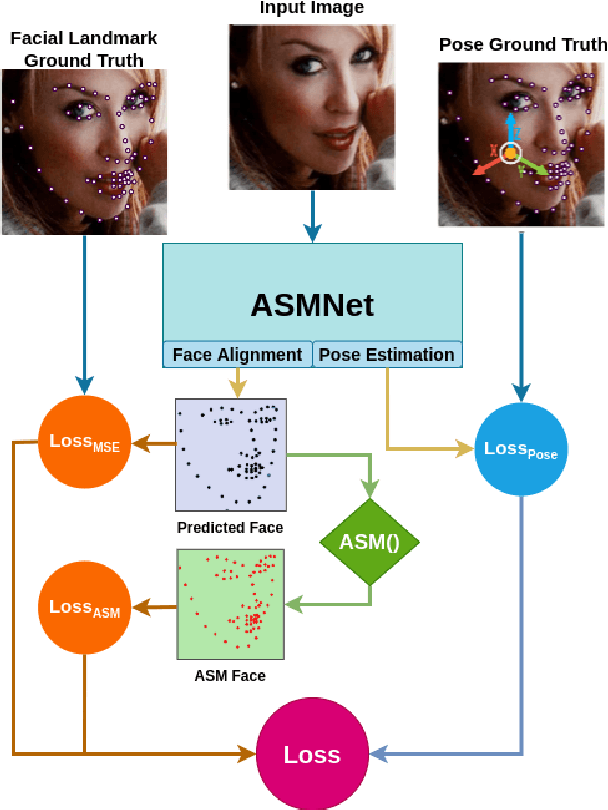
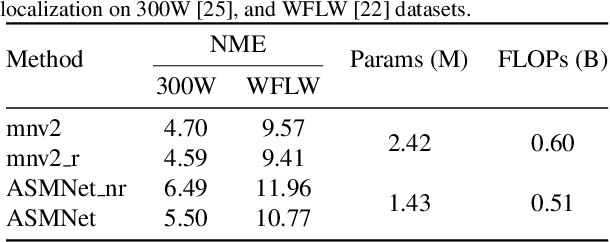
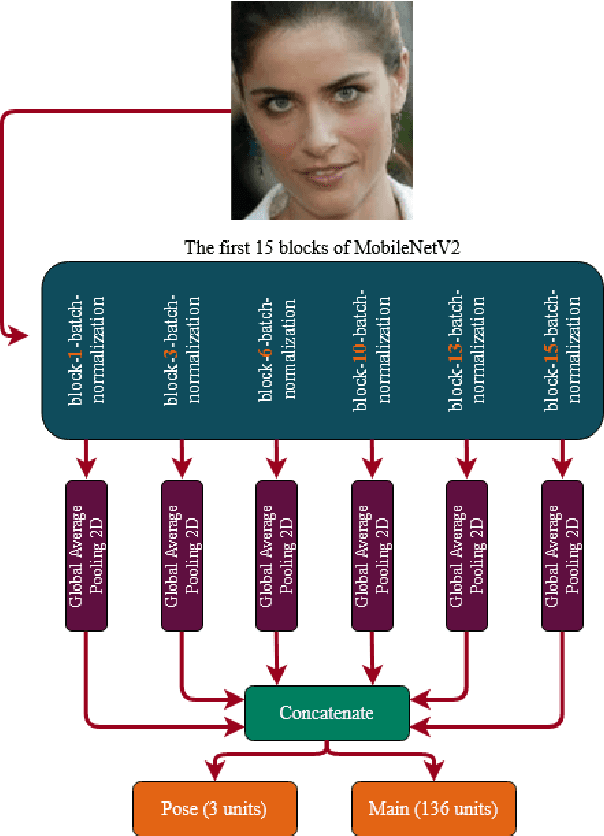
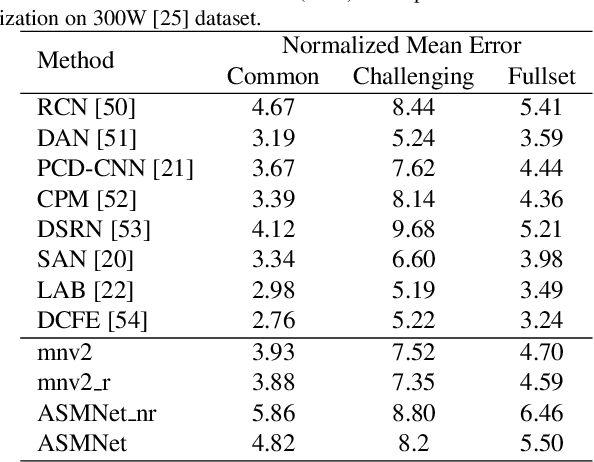
Active Shape Model (ASM) is a statistical model of object shapes that represents a target structure. ASM can guide machine learning algorithms to fit a set of points representing an object (e.g., face) onto an image. This paper presents a lightweight Convolutional Neural Network (CNN) architecture with a loss function being assisted by ASM for face alignment and estimating head pose in the wild. We use ASM to first guide the network towards learning the smoother distribution of the facial landmark points. Then, during the training process, inspired by the transfer learning, we gradually harden the regression problem and lead the network towards learning the original landmark points distribution. We define multi-tasks in our loss function that are responsible for detecting facial landmark points, as well as estimating face pose. Learning multiple correlated tasks simultaneously builds synergy and improves the performance of individual tasks. We compare the performance of our proposed CNN, ASMNet with MobileNetV2 (which is about 2 times bigger ASMNet) in both face alignment and pose estimation tasks. Experimental results on challenging datasets show that by using the proposed ASM assisted loss function, ASMNet performance is comparable with MobileNetV2 in face alignment task. Besides, for face pose estimation, ASMNet performs much better than MobileNetV2. Moreover, overall ASMNet achieves an acceptable performance for facial landmark points detection and pose estimation while having a significantly smaller number of parameters and floating-point operations comparing to many CNN-based proposed models.
Deep Learning-based Symbolic Indoor Positioning using the Serving eNodeB
Sep 28, 2020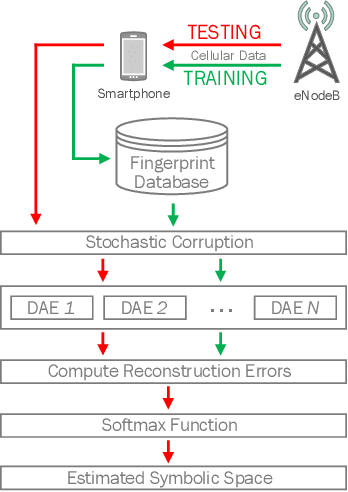

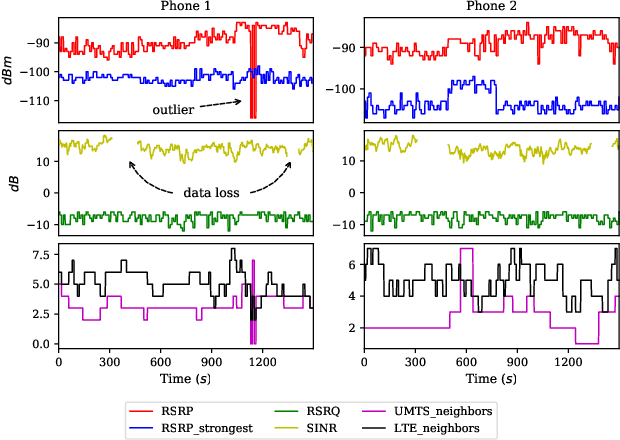
This paper presents a novel indoor positioning method designed for residential apartments. The proposed method makes use of cellular signals emitting from a serving eNodeB which eliminates the need for specialized positioning infrastructure. Additionally, it utilizes Denoising Autoencoders to mitigate the effects of cellular signal loss. We evaluated the proposed method using real-world data collected from two different smartphones inside a representative apartment of eight symbolic spaces. Experimental results verify that the proposed method outperforms conventional symbolic indoor positioning techniques in various performance metrics. To promote reproducibility and foster new research efforts, we made all the data and codes associated with this work publicly available.
Leveraging Class Similarity to Improve Deep Neural Network Robustness
Dec 27, 2018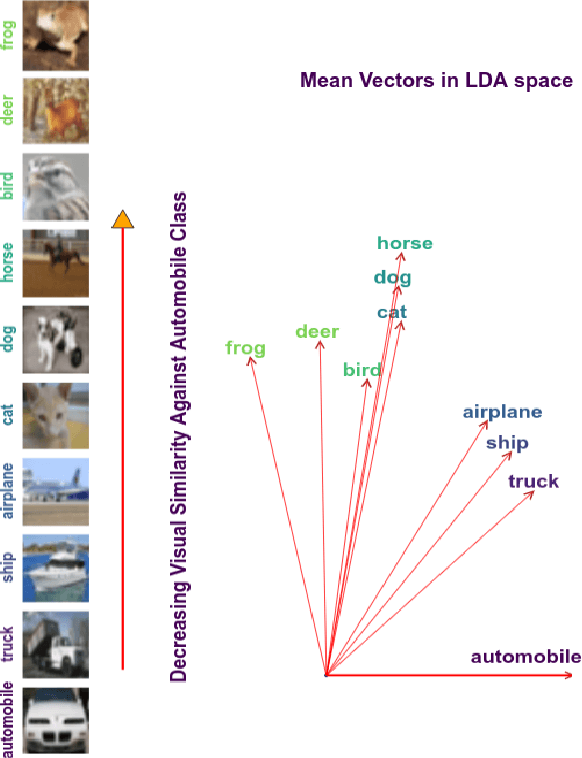
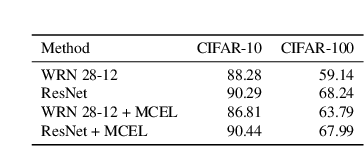

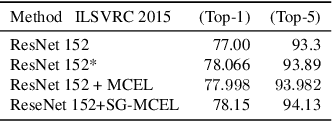
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross-entropy between a provided groundtruth delta distribution (encoded as one-hot vector) and the ANN's predictive softmax distribution. It seems, however, unacceptable to penalize networks equally for missclassification between classes. Confusing the class "Automobile" with the class "Truck" should be penalized less than confusing the class "Automobile" with the class "Donkey". To avoid such representation issues and learn cleaner classification boundaries in the network, this paper presents a variation of cross-entropy loss which depends not only on the sample class but also on a data-driven prior "class-similarity distribution" across the classes encoded in a matrix form. We explore learning the class-similarity distribution using a datadriven method and then show that by training with our modified similarity-driven loss, we obtain slightly better generalization performance over multiple architectures and datasets as well as improved performance on noisy testing scenarios.