 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Class Similarity to Improve Deep Neural Network Robustness
Dec 27, 2018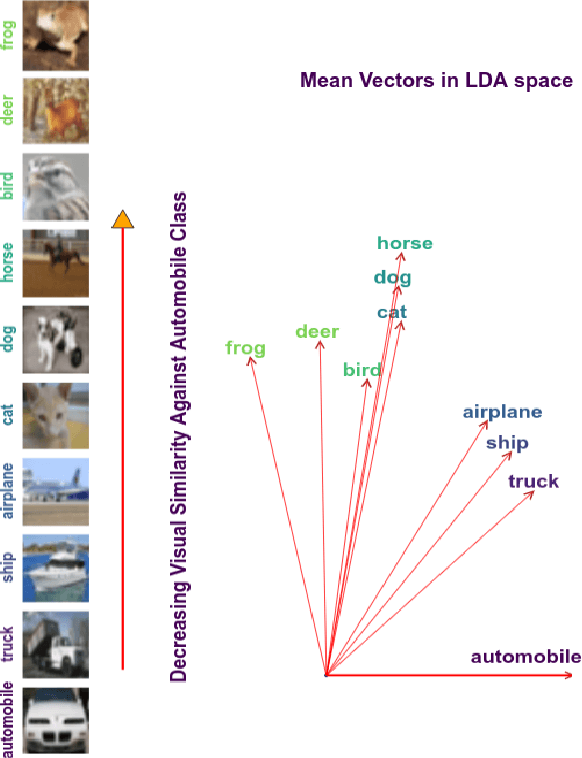
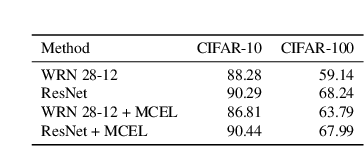

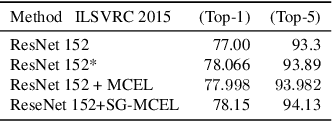
Traditionally artificial neural networks (ANNs) are trained by minimizing the cross-entropy between a provided groundtruth delta distribution (encoded as one-hot vector) and the ANN's predictive softmax distribution. It seems, however, unacceptable to penalize networks equally for missclassification between classes. Confusing the class "Automobile" with the class "Truck" should be penalized less than confusing the class "Automobile" with the class "Donkey". To avoid such representation issues and learn cleaner classification boundaries in the network, this paper presents a variation of cross-entropy loss which depends not only on the sample class but also on a data-driven prior "class-similarity distribution" across the classes encoded in a matrix form. We explore learning the class-similarity distribution using a datadriven method and then show that by training with our modified similarity-driven loss, we obtain slightly better generalization performance over multiple architectures and datasets as well as improved performance on noisy testing scenarios.