 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble Distillation for Neural Machine Translation
Aug 08, 2017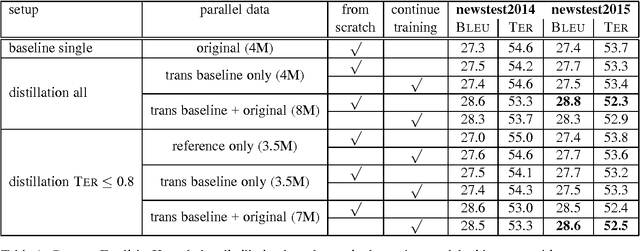
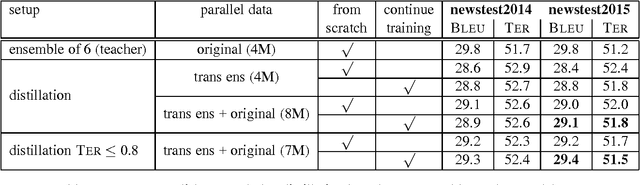
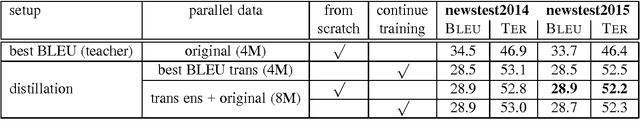
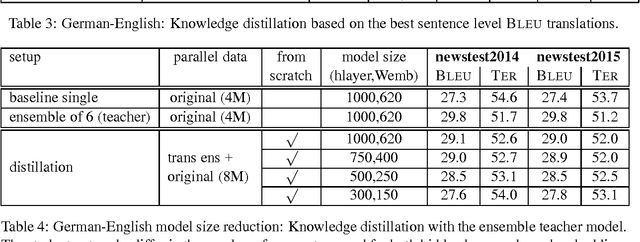
Knowledge distillation describes a method for training a student network to perform better by learning from a stronger teacher network. Translating a sentence with an Neural Machine Translation (NMT) engine is time expensive and having a smaller model speeds up this process. We demonstrate how to transfer the translation quality of an ensemble and an oracle BLEU teacher network into a single NMT system. Further, we present translation improvements from a teacher network that has the same architecture and dimensions of the student network. As the training of the student model is still expensive, we introduce a data filtering method based on the knowledge of the teacher model that not only speeds up the training, but also leads to better translation quality. Our techniques need no code change and can be easily reproduced with any NMT architecture to speed up the decoding process.
Attention-based Vocabulary Selection for NMT Decoding
Jun 12, 2017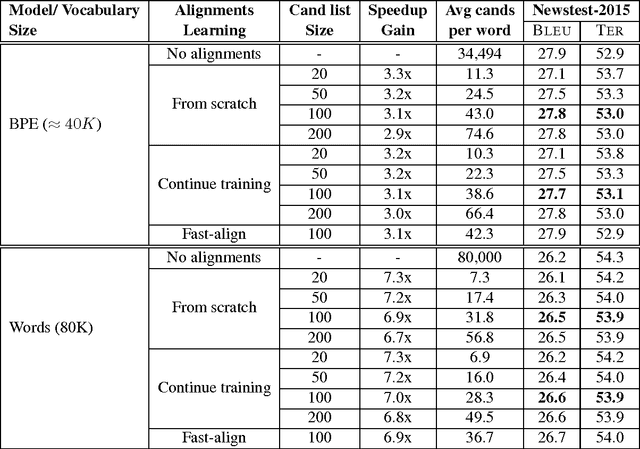
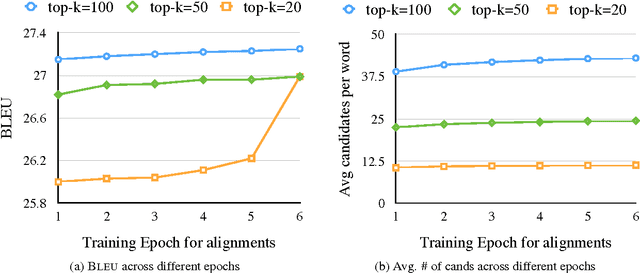
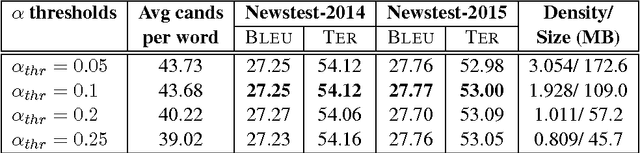
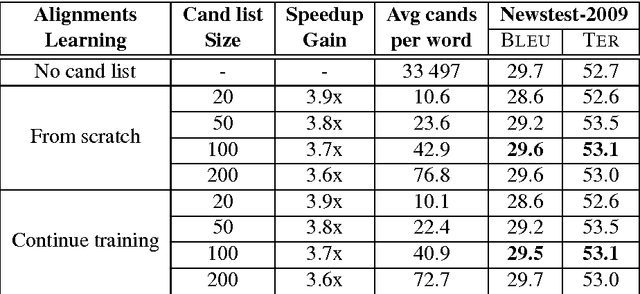
Neural Machine Translation (NMT) models usually use large target vocabulary sizes to capture most of the words in the target language. The vocabulary size is a big factor when decoding new sentences as the final softmax layer normalizes over all possible target words. To address this problem, it is widely common to restrict the target vocabulary with candidate lists based on the source sentence. Usually, the candidate lists are a combination of external word-to-word aligner, phrase table entries or most frequent words. In this work, we propose a simple and yet novel approach to learn candidate lists directly from the attention layer during NMT training. The candidate lists are highly optimized for the current NMT model and do not need any external computation of the candidate pool. We show significant decoding speedup compared with using the entire vocabulary, without losing any translation quality for two language pairs.
Coverage Embedding Models for Neural Machine Translation
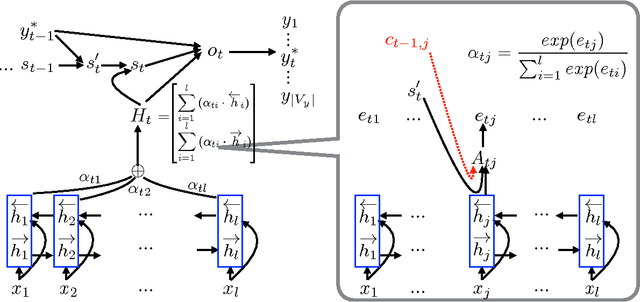
Aug 29, 2016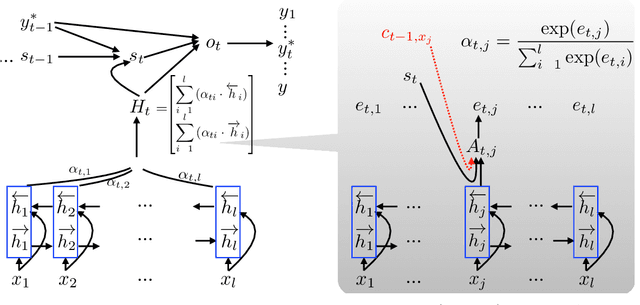
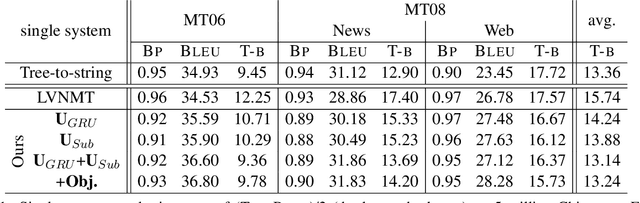
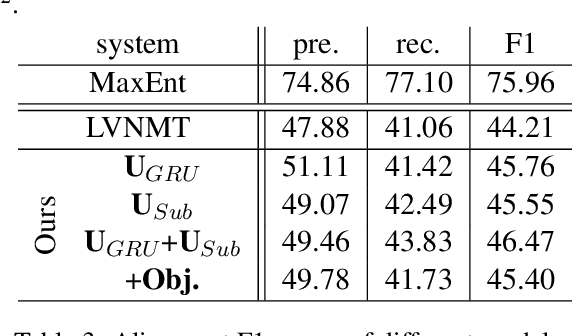
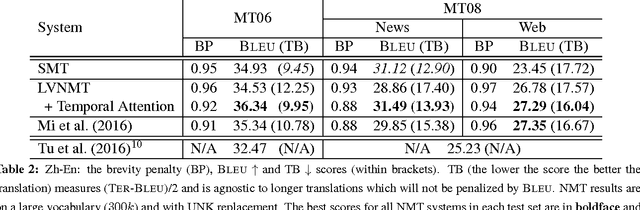
In this paper, we enhance the attention-based neural machine translation (NMT) by adding explicit coverage embedding models to alleviate issues of repeating and dropping translations in NMT. For each source word, our model starts with a full coverage embedding vector to track the coverage status, and then keeps updating it with neural networks as the translation goes. Experiments on the large-scale Chinese-to-English task show that our enhanced model improves the translation quality significantly on various test sets over the strong large vocabulary NMT system.
Temporal Attention Model for Neural Machine Translation
Aug 09, 2016
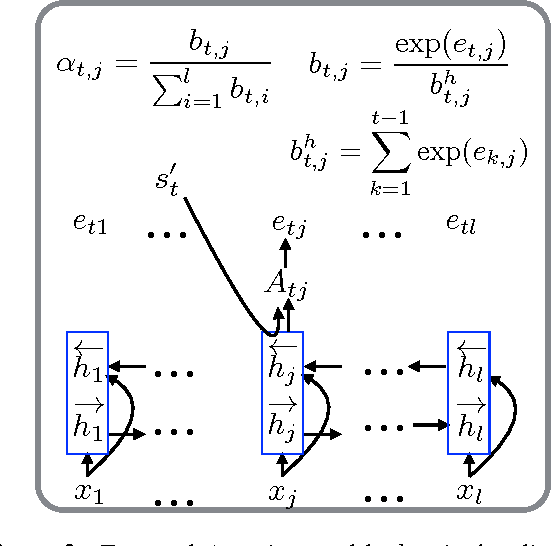
Attention-based Neural Machine Translation (NMT) models suffer from attention deficiency issues as has been observed in recent research. We propose a novel mechanism to address some of these limitations and improve the NMT attention. Specifically, our approach memorizes the alignments temporally (within each sentence) and modulates the attention with the accumulated temporal memory, as the decoder generates the candidate translation. We compare our approach against the baseline NMT model and two other related approaches that address this issue either explicitly or implicitly. Large-scale experiments on two language pairs show that our approach achieves better and robust gains over the baseline and related NMT approaches. Our model further outperforms strong SMT baselines in some settings even without using ensembles.
Zero-Resource Translation with Multi-Lingual Neural Machine Translation
Jun 13, 2016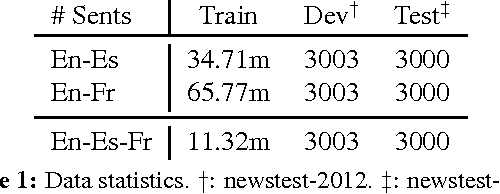
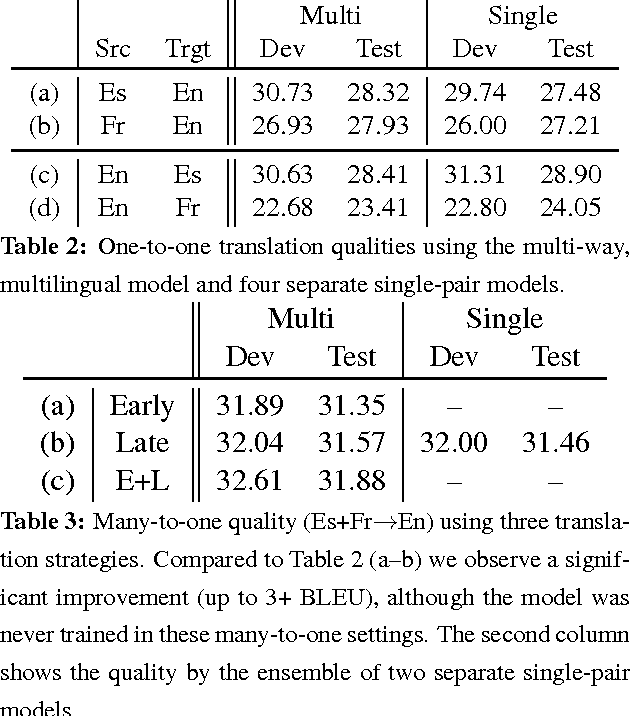
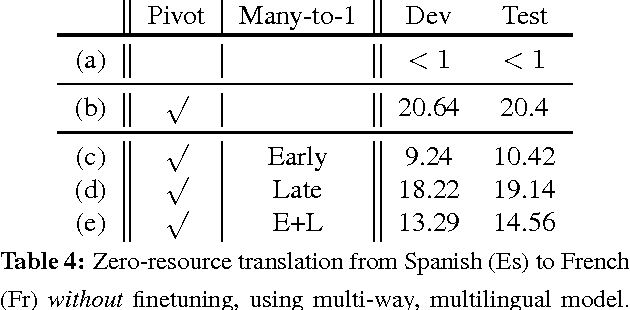
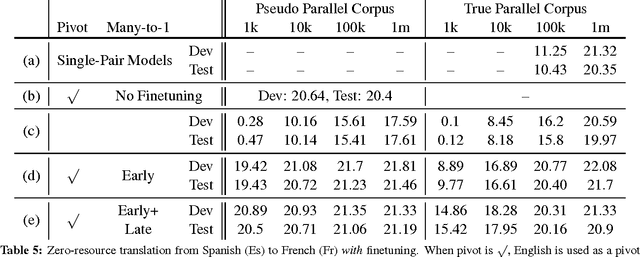
In this paper, we propose a novel finetuning algorithm for the recently introduced multi-way, mulitlingual neural machine translate that enables zero-resource machine translation. When used together with novel many-to-one translation strategies, we empirically show that this finetuning algorithm allows the multi-way, multilingual model to translate a zero-resource language pair (1) as well as a single-pair neural translation model trained with up to 1M direct parallel sentences of the same language pair and (2) better than pivot-based translation strategy, while keeping only one additional copy of attention-related parameters.