 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBucketed Ranking-based Losses for Efficient Training of Object Detectors
Jul 19, 2024Ranking-based loss functions, such as Average Precision Loss and Rank&Sort Loss, outperform widely used score-based losses in object detection. These loss functions better align with the evaluation criteria, have fewer hyperparameters, and offer robustness against the imbalance between positive and negative classes. However, they require pairwise comparisons among $P$ positive and $N$ negative predictions, introducing a time complexity of $\mathcal{O}(PN)$, which is prohibitive since $N$ is often large (e.g., $10^8$ in ATSS). Despite their advantages, the widespread adoption of ranking-based losses has been hindered by their high time and space complexities. In this paper, we focus on improving the efficiency of ranking-based loss functions. To this end, we propose Bucketed Ranking-based Losses which group negative predictions into $B$ buckets ($B \ll N$) in order to reduce the number of pairwise comparisons so that time complexity can be reduced. Our method enhances the time complexity, reducing it to $\mathcal{O}(\max (N \log(N), P^2))$. To validate our method and show its generality, we conducted experiments on 2 different tasks, 3 different datasets, 7 different detectors. We show that Bucketed Ranking-based (BR) Losses yield the same accuracy with the unbucketed versions and provide $2\times$ faster training on average. We also train, for the first time, transformer-based object detectors using ranking-based losses, thanks to the efficiency of our BR. When we train CoDETR, a state-of-the-art transformer-based object detector, using our BR Loss, we consistently outperform its original results over several different backbones. Code is available at https://github.com/blisgard/BucketedRankingBasedLosses
Mask-aware IoU for Anchor Assignment in Real-time Instance Segmentation
Oct 19, 2021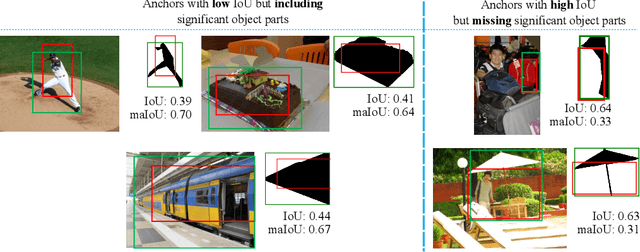
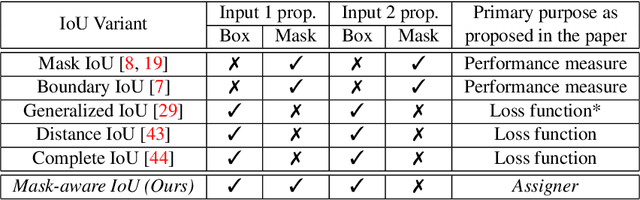
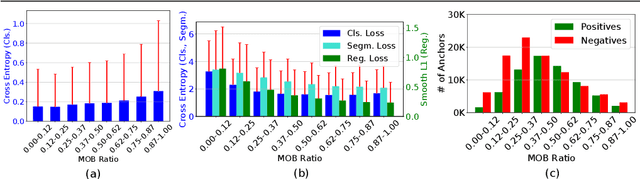
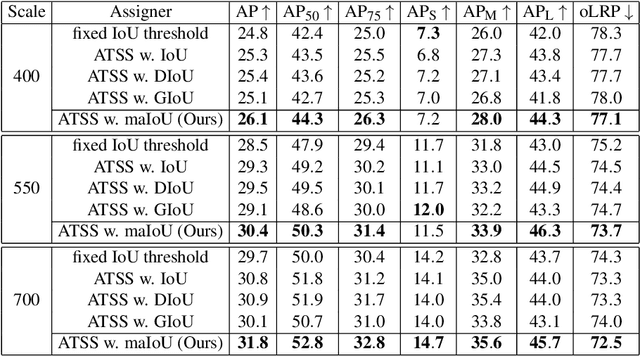
This paper presents Mask-aware Intersection-over-Union (maIoU) for assigning anchor boxes as positives and negatives during training of instance segmentation methods. Unlike conventional IoU or its variants, which only considers the proximity of two boxes; maIoU consistently measures the proximity of an anchor box with not only a ground truth box but also its associated ground truth mask. Thus, additionally considering the mask, which, in fact, represents the shape of the object, maIoU enables a more accurate supervision during training. We present the effectiveness of maIoU on a state-of-the-art (SOTA) assigner, ATSS, by replacing IoU operation by our maIoU and training YOLACT, a SOTA real-time instance segmentation method. Using ATSS with maIoU consistently outperforms (i) ATSS with IoU by $\sim 1$ mask AP, (ii) baseline YOLACT with fixed IoU threshold assigner by $\sim 2$ mask AP over different image sizes and (iii) decreases the inference time by $25 \%$ owing to using less anchors. Then, exploiting this efficiency, we devise maYOLACT, a faster and $+6$ AP more accurate detector than YOLACT. Our best model achieves $37.7$ mask AP at $25$ fps on COCO test-dev establishing a new state-of-the-art for real-time instance segmentation. Code is available at https://github.com/kemaloksuz/Mask-aware-IoU
Rank & Sort Loss for Object Detection and Instance Segmentation
Jul 24, 2021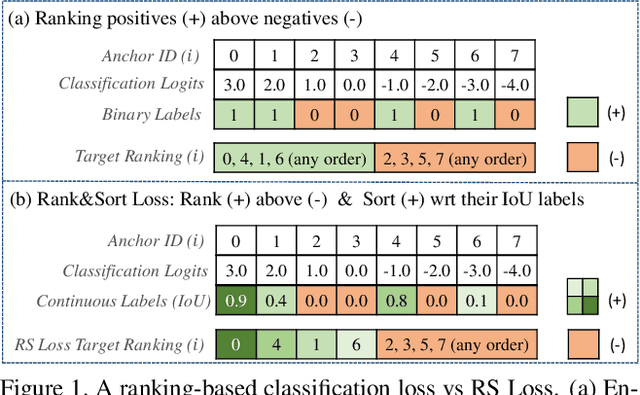
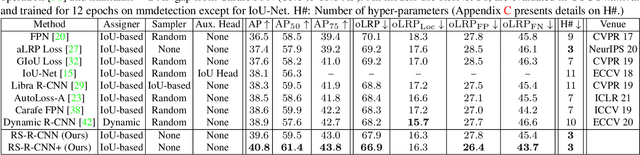
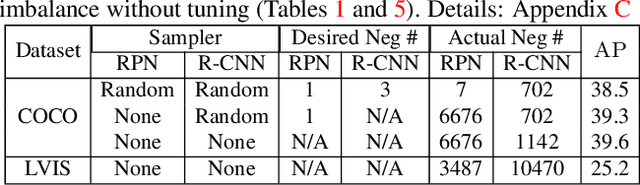
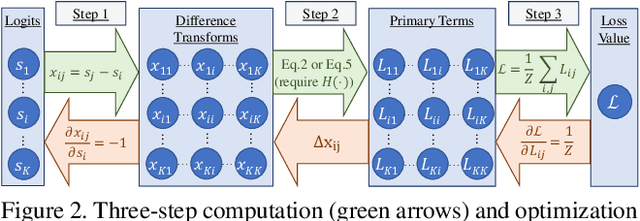
We propose Rank & Sort (RS) Loss, as a ranking-based loss function to train deep object detection and instance segmentation methods (i.e. visual detectors). RS Loss supervises the classifier, a sub-network of these methods, to rank each positive above all negatives as well as to sort positives among themselves with respect to (wrt.) their continuous localisation qualities (e.g. Intersection-over-Union - IoU). To tackle the non-differentiable nature of ranking and sorting, we reformulate the incorporation of error-driven update with backpropagation as Identity Update, which enables us to model our novel sorting error among positives. With RS Loss, we significantly simplify training: (i) Thanks to our sorting objective, the positives are prioritized by the classifier without an additional auxiliary head (e.g. for centerness, IoU, mask-IoU), (ii) due to its ranking-based nature, RS Loss is robust to class imbalance, and thus, no sampling heuristic is required, and (iii) we address the multi-task nature of visual detectors using tuning-free task-balancing coefficients. Using RS Loss, we train seven diverse visual detectors only by tuning the learning rate, and show that it consistently outperforms baselines: e.g. our RS Loss improves (i) Faster R-CNN by ~ 3 box AP and aLRP Loss (ranking-based baseline) by ~ 2 box AP on COCO dataset, (ii) Mask R-CNN with repeat factor sampling (RFS) by 3.5 mask AP (~ 7 AP for rare classes) on LVIS dataset; and also outperforms all counterparts. Code available at https://github.com/kemaloksuz/RankSortLoss
One Metric to Measure them All: Localisation Recall Precision for Evaluating Visual Detection Tasks
Nov 21, 2020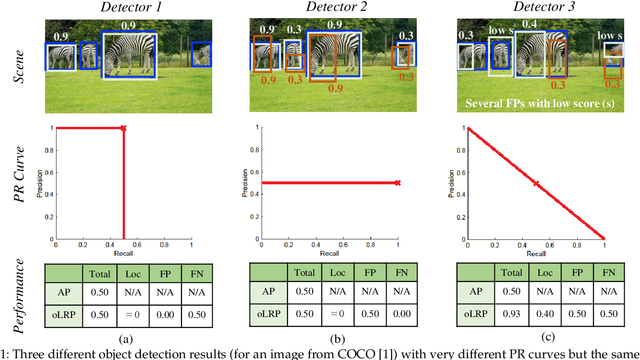

Despite being widely used as a performance measure for visual detection tasks, Average Precision (AP) is limited in (i) including localisation quality, (ii) interpretability and (iii) applicability to outputs without confidence scores. Panoptic Quality (PQ), a measure proposed for evaluating panoptic segmentation (Kirillov et al., 2019), does not suffer from these limitations but is limited to panoptic segmentation. In this paper, we propose Localisation Recall Precision (LRP) Error as the performance measure for all visual detection tasks. LRP Error, initially proposed only for object detection by Oksuz et al. (2018), does not suffer from the aforementioned limitations and is applicable to all visual detection tasks. We also introduce Optimal LRP (oLRP) Error as the minimum LRP error obtained over confidence scores to evaluate visual detectors and obtain optimal thresholds for deployment. We provide a detailed comparative analysis of LRP with AP and PQ, and use 35 state-of-the-art visual detectors from four common visual detection tasks (i.e. object detection, keypoint detection, instance segmentation and panoptic segmentation) to empirically show that LRP provides richer and more discriminative information than its counterparts. Code available at: https://github.com/kemaloksuz/LRP-Error
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
Oct 23, 2020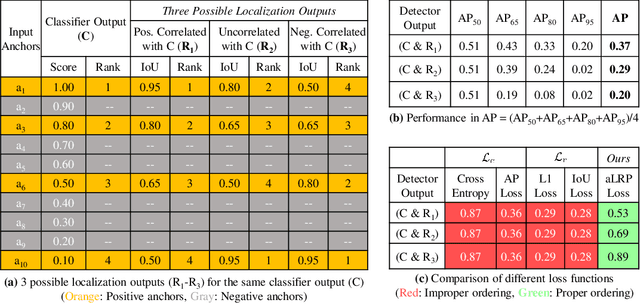

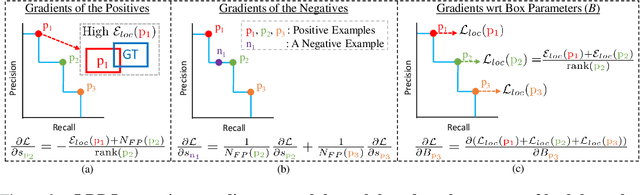

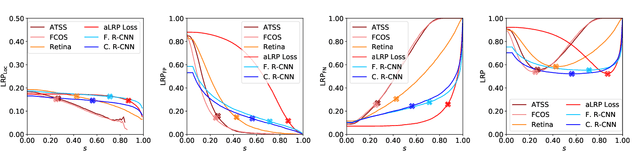
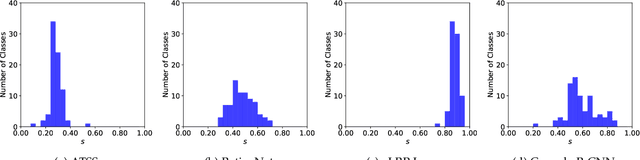
We propose \textit{average Localisation-Recall-Precision} (aLRP), a unified, bounded, balanced and ranking-based loss function for both classification and localisation tasks in object detection. aLRP extends the Localisation-Recall-Precision (LRP) performance metric (Oksuz et al., 2018) inspired from how Average Precision (AP) Loss extends precision to a ranking-based loss function for classification (Chen et al., 2020). aLRP has the following distinct advantages: (i) aLRP is the first ranking-based loss function for both classification and localisation tasks. (ii) Thanks to using ranking for both tasks, aLRP naturally enforces high-quality localisation for high-precision classification. (iii) aLRP provides provable balance between positives and negatives. (iv) Compared to on average $\sim$6 hyperparameters in the loss functions of state-of-the-art detectors, aLRP Loss has only one hyperparameter, which we did not tune in practice. On the COCO dataset, aLRP Loss improves its ranking-based predecessor, AP Loss, up to around $5$ AP points, achieves $48.9$ AP without test time augmentation and outperforms all one-stage detectors. Code available at: https://github.com/kemaloksuz/aLRPLoss .
Generating Positive Bounding Boxes for Balanced Training of Object Detectors
Sep 21, 2019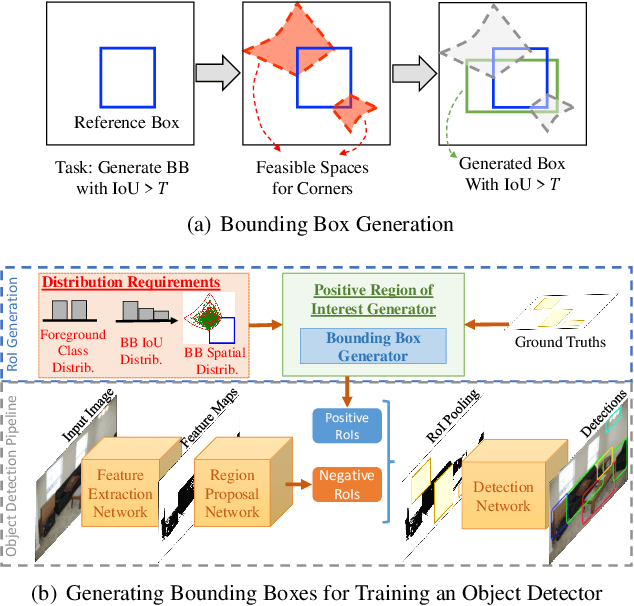
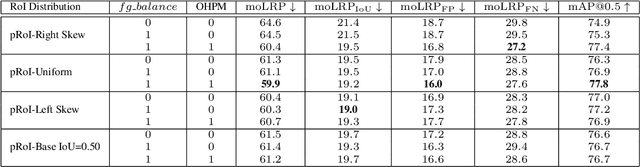
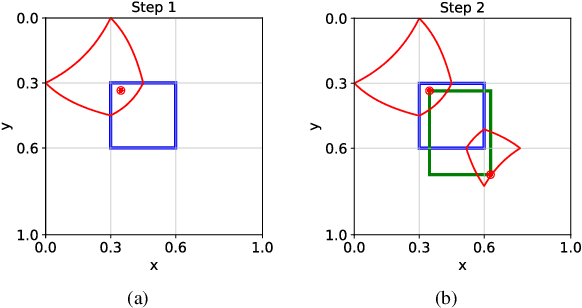

Two-stage deep object detectors generate a set of regions-of-interest (RoI) in the first stage, then, in the second stage, identify objects among the proposed RoIs that sufficiently overlap with a ground truth (GT) box. The second stage is known to suffer from a bias towards RoIs that have low intersection-over-union (IoU) with the associated GT boxes. To address this issue, we first propose a sampling method to generate bounding boxes (BB) that overlap with a given reference box more than a given IoU threshold. Then, we use this BB generation method to develop a positive RoI (pRoI) generator that produces RoIs following any desired spatial or IoU distribution, for the second-stage. We show that our pRoI generator is able to simulate other sampling methods for positive examples such as hard example mining and prime sampling. Using our generator as an analysis tool, we show that (i) IoU imbalance has an adverse effect on performance, (ii) hard positive example mining improves the performance only for certain input IoU distributions, and (iii) the imbalance among the foreground classes has an adverse effect on performance and that it can be alleviated at the batch level. Finally, we train Faster R-CNN using our pRoI generator and, compared to conventional training, obtain better or on-par performance for low IoUs and significant improvements for higher IoUs (e.g. for $IoU=0.8$, $\mathrm{mAP@0.8}$ improves by $10.9\%$). The code will be made publicly available.
Imbalance Problems in Object Detection: A Review
Aug 31, 2019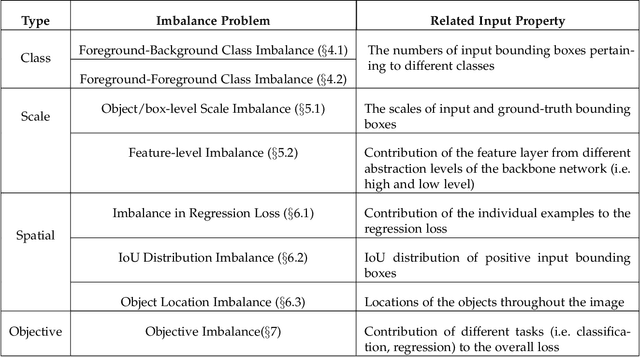
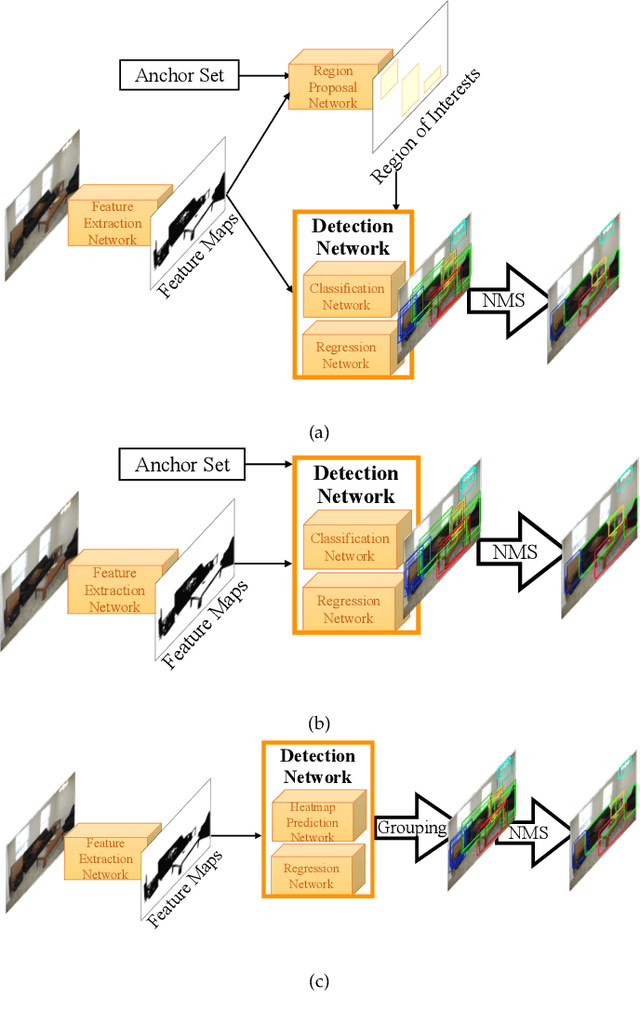
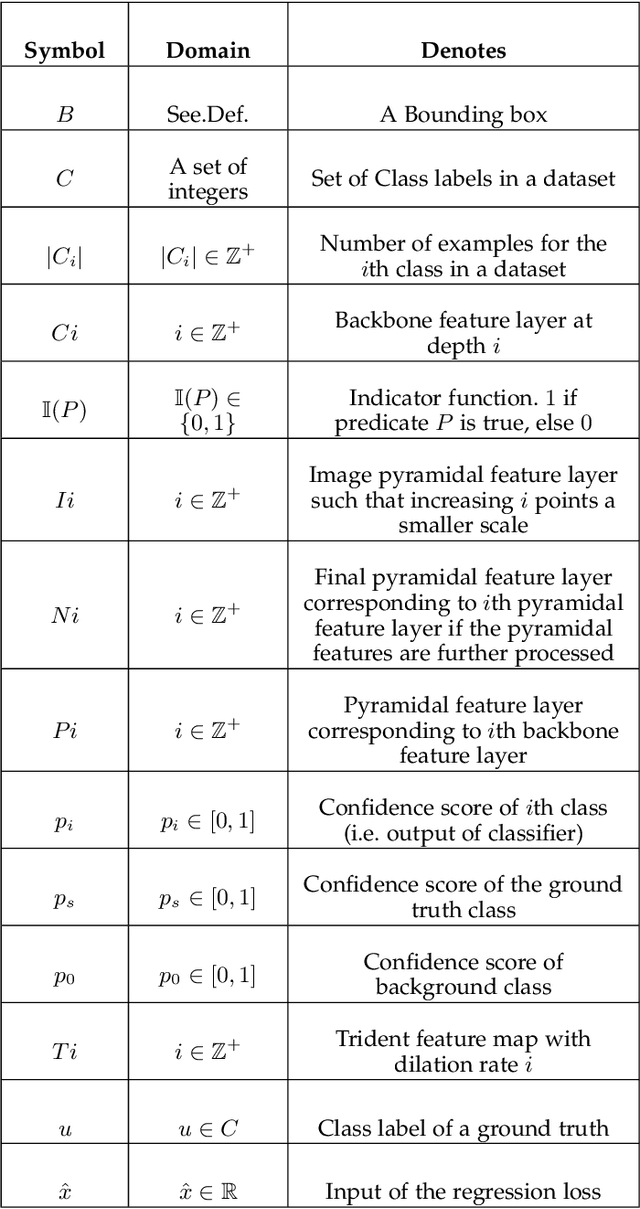
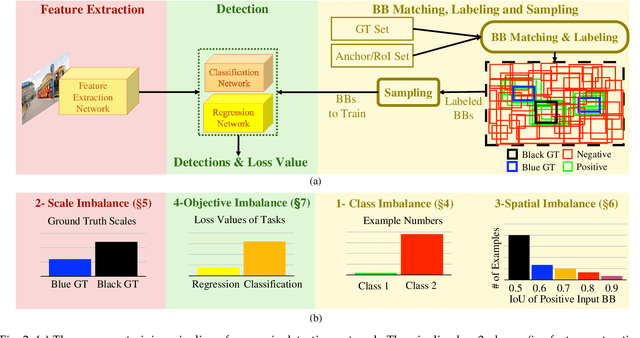
In this paper, we present a comprehensive review of the imbalance problems in object detection. To analyze the problems in a systematic manner, we introduce two taxonomies; one for the problems and the other for the proposed solutions. Following the taxonomy for the problems, we discuss each problem in depth and present a unifying yet critical perspective on the solutions in the literature. In addition, we identify major open issues regarding the existing imbalance problems as well as imbalance problems that have not been discussed before. Moreover, in order to keep our review up to date, we provide an accompanying webpage which categorizes papers addressing imbalance problems, according to our problem-based taxonomy. Researchers can track newer studies on this webpage available at: https://github.com/kemaloksuz/ObjectDetectionImbalance .
Localization Recall Precision (LRP): A New Performance Metric for Object Detection
Jul 05, 2018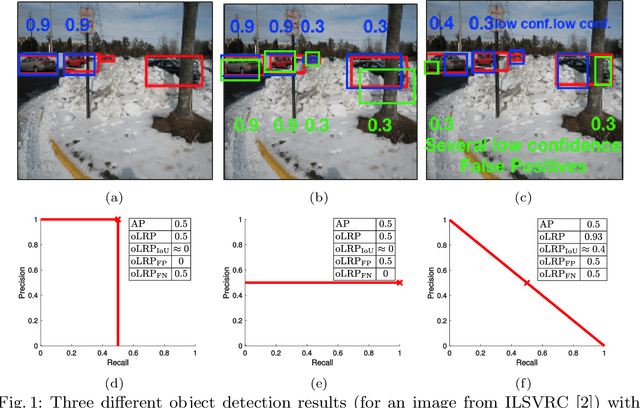
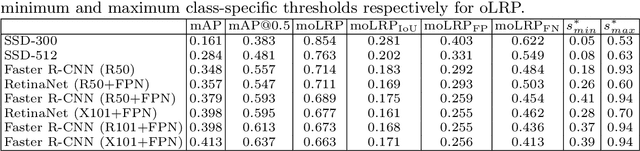
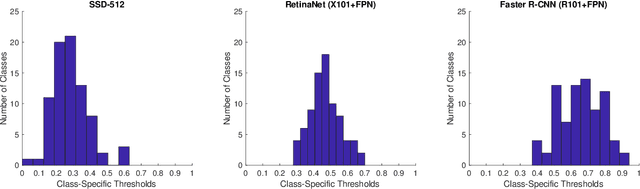
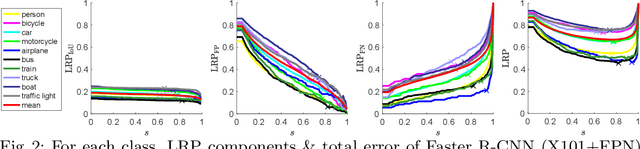
Average precision (AP), the area under the recall-precision (RP) curve, is the standard performance measure for object detection. Despite its wide acceptance, it has a number of shortcomings, the most important of which are (i) the inability to distinguish very different RP curves, and (ii) the lack of directly measuring bounding box localization accuracy. In this paper, we propose 'Localization Recall Precision (LRP) Error', a new metric which we specifically designed for object detection. LRP Error is composed of three components related to localization, false negative (FN) rate and false positive (FP) rate. Based on LRP, we introduce the 'Optimal LRP', the minimum achievable LRP error representing the best achievable configuration of the detector in terms of recall-precision and the tightness of the boxes. In contrast to AP, which considers precisions over the entire recall domain, Optimal LRP determines the 'best' confidence score threshold for a class, which balances the trade-off between localization and recall-precision. In our experiments, we show that, for state-of-the-art object (SOTA) detectors, Optimal LRP provides richer and more discriminative information than AP. We also demonstrate that the best confidence score thresholds vary significantly among classes and detectors. Moreover, we present LRP results of a simple online video object detector which uses a SOTA still image object detector and show that the class-specific optimized thresholds increase the accuracy against the common approach of using a general threshold for all classes. At https://github.com/cancam/LRP we provide the source code that can compute LRP for the PASCAL VOC and MSCOCO datasets. Our source code can easily be adapted to other datasets as well.