 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBucketed Ranking-based Losses for Efficient Training of Object Detectors
Jul 19, 2024Ranking-based loss functions, such as Average Precision Loss and Rank&Sort Loss, outperform widely used score-based losses in object detection. These loss functions better align with the evaluation criteria, have fewer hyperparameters, and offer robustness against the imbalance between positive and negative classes. However, they require pairwise comparisons among $P$ positive and $N$ negative predictions, introducing a time complexity of $\mathcal{O}(PN)$, which is prohibitive since $N$ is often large (e.g., $10^8$ in ATSS). Despite their advantages, the widespread adoption of ranking-based losses has been hindered by their high time and space complexities. In this paper, we focus on improving the efficiency of ranking-based loss functions. To this end, we propose Bucketed Ranking-based Losses which group negative predictions into $B$ buckets ($B \ll N$) in order to reduce the number of pairwise comparisons so that time complexity can be reduced. Our method enhances the time complexity, reducing it to $\mathcal{O}(\max (N \log(N), P^2))$. To validate our method and show its generality, we conducted experiments on 2 different tasks, 3 different datasets, 7 different detectors. We show that Bucketed Ranking-based (BR) Losses yield the same accuracy with the unbucketed versions and provide $2\times$ faster training on average. We also train, for the first time, transformer-based object detectors using ranking-based losses, thanks to the efficiency of our BR. When we train CoDETR, a state-of-the-art transformer-based object detector, using our BR Loss, we consistently outperform its original results over several different backbones. Code is available at https://github.com/blisgard/BucketedRankingBasedLosses
Segment Augmentation and Differentiable Ranking for Logo Retrieval
Sep 13, 2022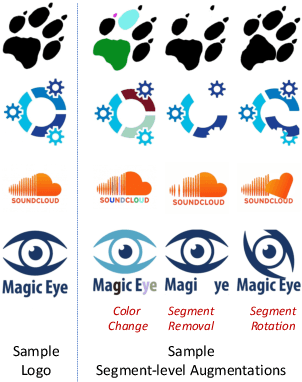
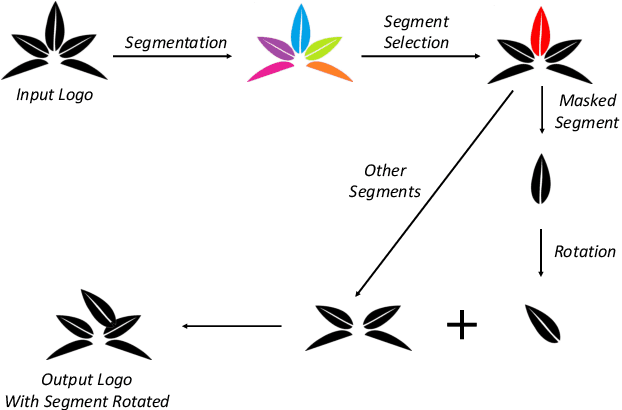

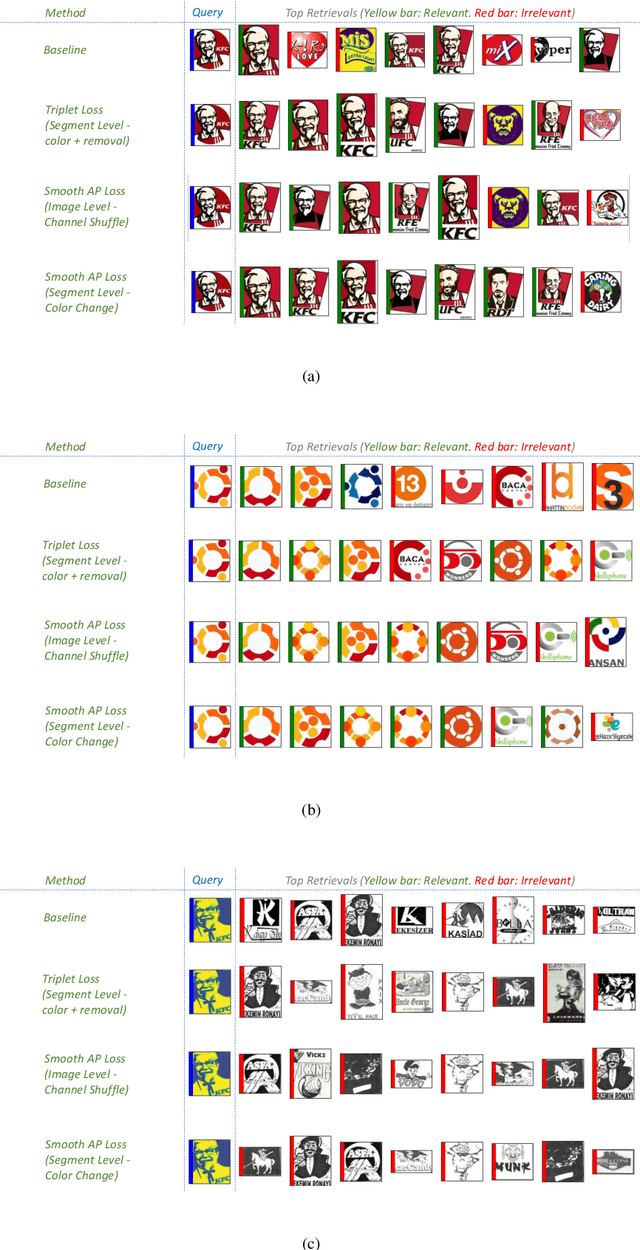
Logo retrieval is a challenging problem since the definition of similarity is more subjective compared to image retrieval tasks and the set of known similarities is very scarce. To tackle this challenge, in this paper, we propose a simple but effective segment-based augmentation strategy to introduce artificially similar logos for training deep networks for logo retrieval. In this novel augmentation strategy, we first find segments in a logo and apply transformations such as rotation, scaling, and color change, on the segments, unlike the conventional image-level augmentation strategies. Moreover, we evaluate whether the recently introduced ranking-based loss function, Smooth-AP, is a better approach for learning similarity for logo retrieval. On the large scale METU Trademark Dataset, we show that (i) our segment-based augmentation strategy improves retrieval performance compared to the baseline model or image-level augmentation strategies, and (ii) Smooth-AP indeed performs better than conventional losses for logo retrieval.