 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Screening of Typical and Atypical Behaviors in Children With Autism
Sep 17, 2019



This paper has been withdrawn by the authors due to insufficient or definition error(s) in the ethics approval protocol. Autism spectrum disorders (ASD) impact the cognitive, social, communicative and behavioral abilities of an individual. The development of new clinical decision support systems is of importance in reducing the delay between presentation of symptoms and an accurate diagnosis. In this work, we contribute a new database consisting of video clips of typical (normal) and atypical (such as hand flapping, spinning or rocking) behaviors, displayed in natural settings, which have been collected from the YouTube video website. We propose a preliminary non-intrusive approach based on skeleton keypoint identification using pretrained deep neural networks on human body video clips to extract features and perform body movement analysis that differentiates typical and atypical behaviors of children. Experimental results on the newly contributed database show that our platform performs best with decision tree as the classifier when compared to other popular methodologies and offers a baseline against which alternate approaches may developed and tested.
Deep Convolutional Generative Adversarial Network Based Food Recognition Using Partially Labeled Data
Dec 26, 2018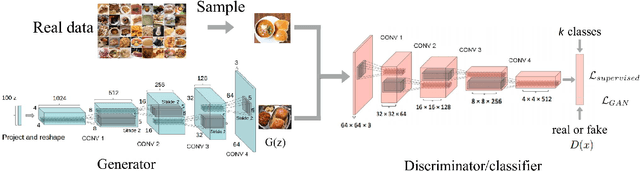

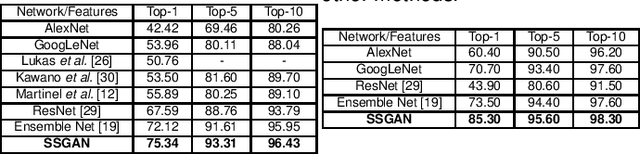
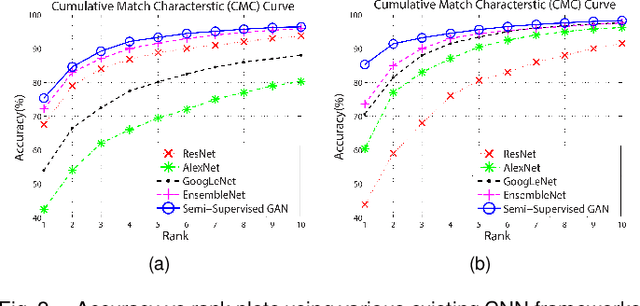
Traditional machine learning algorithms using hand-crafted feature extraction techniques (such as local binary pattern) have limited accuracy because of high variation in images of the same class (or intra-class variation) for food recognition task. In recent works, convolutional neural networks (CNN) have been applied to this task with better results than all previously reported methods. However, they perform best when trained with large amount of annotated (labeled) food images. This is problematic when obtained in large volume, because they are expensive, laborious and impractical. Our work aims at developing an efficient deep CNN learning-based method for food recognition alleviating these limitations by using partially labeled training data on generative adversarial networks (GANs). We make new enhancements to the unsupervised training architecture introduced by Goodfellow et al. (2014), which was originally aimed at generating new data by sampling a dataset. In this work, we make modifications to deep convolutional GANs to make them robust and efficient for classifying food images. Experimental results on benchmarking datasets show the superiority of our proposed method as compared to the current-state-of-the-art methodologies even when trained with partially labeled training data.
Cross-spectral Periocular Recognition: A Survey
Dec 04, 2018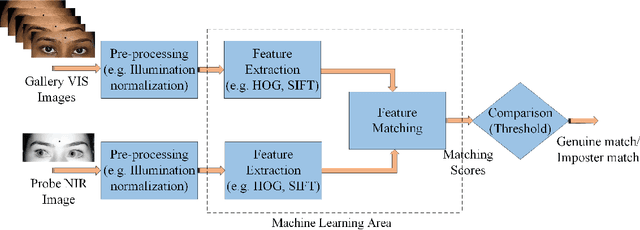
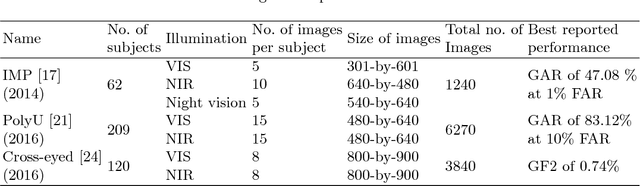
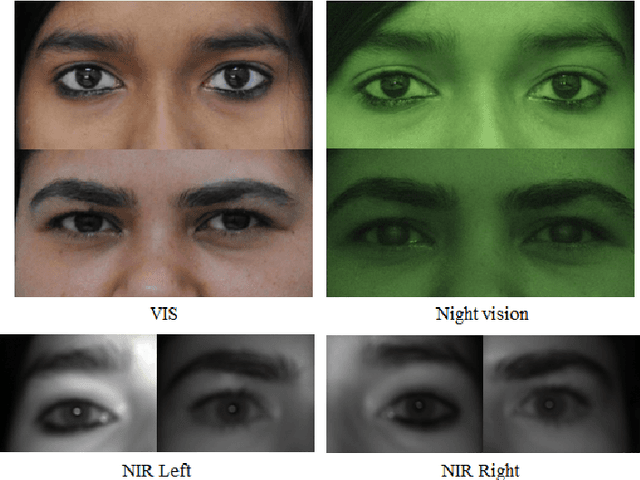
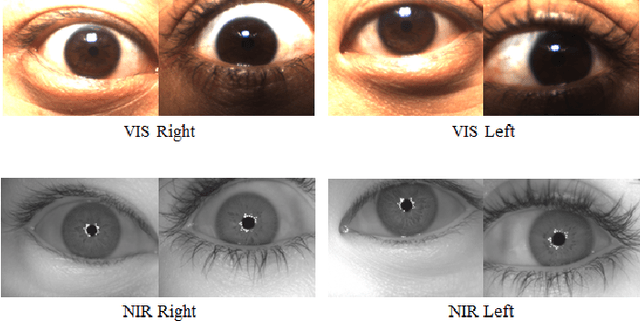
Among many biometrics such as face, iris, fingerprint and others, periocular region has the advantages over other biometrics because it is non-intrusive and serves as a balance between iris or eye region (very stringent, small area) and the whole face region (very relaxed large area). Research have shown that this is the region which does not get affected much because of various poses, aging, expression, facial changes and other artifacts, which otherwise would change to a large variation. Active research has been carried out on this topic since past few years due to its obvious advantages over face and iris biometrics in unconstrained and uncooperative scenarios. Many researchers have explored periocular biometrics involving both visible (VIS) and infra-red (IR) spectrum images. For a system to work for 24/7 (such as in surveillance scenarios), the registration process may depend on the day time VIS periocular images (or any mug shot image) and the testing or recognition process may occur in the night time involving only IR periocular images. This gives rise to a challenging research problem called the cross-spectral matching of images where VIS images are used for registration or as gallery images and IR images are used for testing or recognition process and vice versa. After intensive research of more than two decades on face and iris biometrics in cross-spectral domain, a number of researchers have now focused their work on matching heterogeneous (cross-spectral) periocular images. Though a number of surveys have been made on existing periocular biometric research, no study has been done on its cross-spectral aspect. This paper analyses and reviews current state-of-the-art techniques in cross-spectral periocular recognition including various methodologies, databases, their protocols and current-state-of-the-art recognition performances.
Deep Adaptive Temporal Pooling for Activity Recognition
Aug 22, 2018



Deep neural networks have recently achieved competitive accuracy for human activity recognition. However, there is room for improvement, especially in modeling long-term temporal importance and determining the activity relevance of different temporal segments in a video. To address this problem, we propose a learnable and differentiable module: Deep Adaptive Temporal Pooling (DATP). DATP applies a self-attention mechanism to adaptively pool the classification scores of different video segments. Specifically, using frame-level features, DATP regresses importance of different temporal segments and generates weights for them. Remarkably, DATP is trained using only the video-level label. There is no need of additional supervision except video-level activity class label. We conduct extensive experiments to investigate various input features and different weight models. Experimental results show that DATP can learn to assign large weights to key video segments. More importantly, DATP can improve training of frame-level feature extractor. This is because relevant temporal segments are assigned large weights during back-propagation. Overall, we achieve state-of-the-art performance on UCF101, HMDB51 and Kinetics datasets.
FoodNet: Recognizing Foods Using Ensemble of Deep Networks
Sep 27, 2017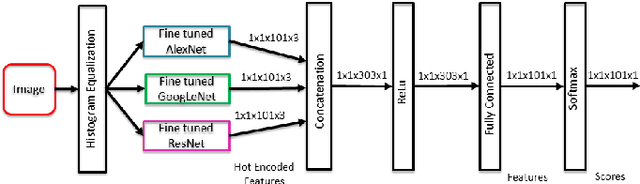

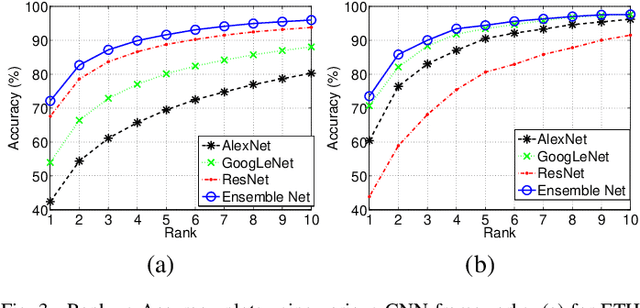
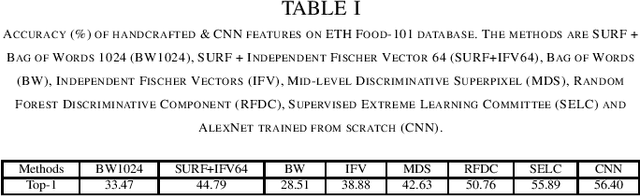
In this work we propose a methodology for an automatic food classification system which recognizes the contents of the meal from the images of the food. We developed a multi-layered deep convolutional neural network (CNN) architecture that takes advantages of the features from other deep networks and improves the efficiency. Numerous classical handcrafted features and approaches are explored, among which CNNs are chosen as the best performing features. Networks are trained and fine-tuned using preprocessed images and the filter outputs are fused to achieve higher accuracy. Experimental results on the largest real-world food recognition database ETH Food-101 and newly contributed Indian food image database demonstrate the effectiveness of the proposed methodology as compared to many other benchmark deep learned CNN frameworks.
Distinguishing Posed and Spontaneous Smiles by Facial Dynamics
Feb 17, 2017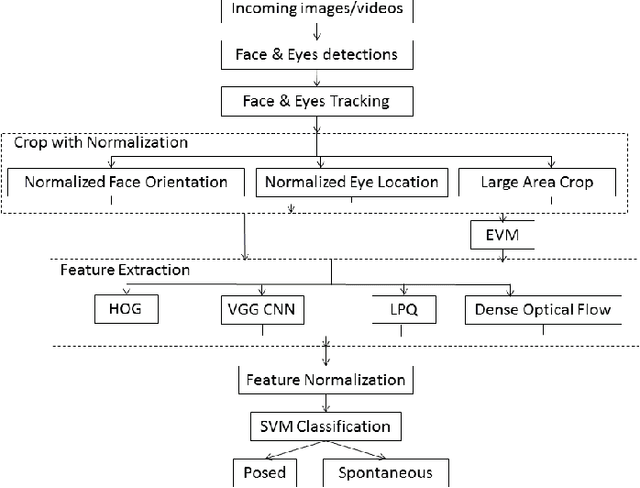
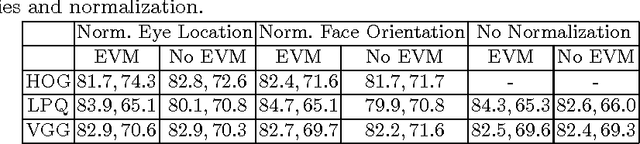
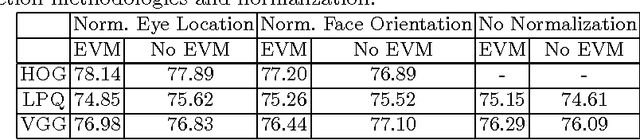
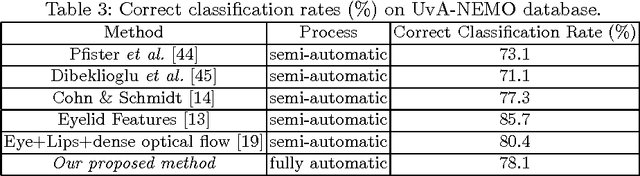
Smile is one of the key elements in identifying emotions and present state of mind of an individual. In this work, we propose a cluster of approaches to classify posed and spontaneous smiles using deep convolutional neural network (CNN) face features, local phase quantization (LPQ), dense optical flow and histogram of gradient (HOG). Eulerian Video Magnification (EVM) is used for micro-expression smile amplification along with three normalization procedures for distinguishing posed and spontaneous smiles. Although the deep CNN face model is trained with large number of face images, HOG features outperforms this model for overall face smile classification task. Using EVM to amplify micro-expressions did not have a significant impact on classification accuracy, while the normalizing facial features improved classification accuracy. Unlike many manual or semi-automatic methodologies, our approach aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large UvA-NEMO smile database show promising results as compared to other relevant methods.
Spontaneous vs. Posed smiles - can we tell the difference?
May 23, 2016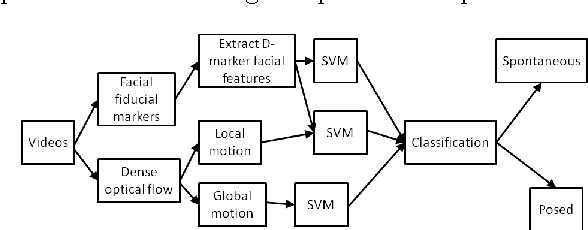

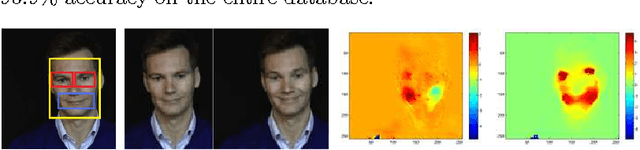

Smile is an irrefutable expression that shows the physical state of the mind in both true and deceptive ways. Generally, it shows happy state of the mind, however, `smiles' can be deceptive, for example people can give a smile when they feel happy and sometimes they might also give a smile (in a different way) when they feel pity for others. This work aims to distinguish spontaneous (felt) smile expressions from posed (deliberate) smiles by extracting and analyzing both global (macro) motion of the face and subtle (micro) changes in the facial expression features through both tracking a series of facial fiducial markers as well as using dense optical flow. Specifically the eyes and lips features are captured and used for analysis. It aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large database show promising results as compared to other relevant methods.
Improved Eigenfeature Regularization for Face Identification
Feb 10, 2016
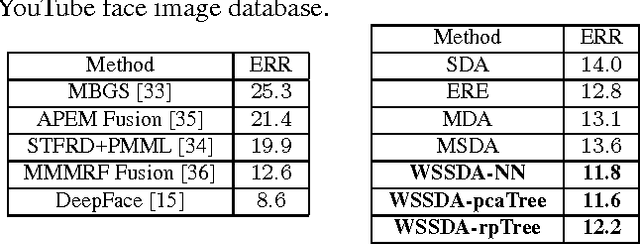


In this work, we propose to divide each class (a person) into subclasses using spatial partition trees which helps in better capturing the intra-personal variances arising from the appearances of the same individual. We perform a comprehensive analysis on within-class and within-subclass eigenspectrums of face images and propose a novel method of eigenspectrum modeling which extracts discriminative features of faces from both within-subclass and total or between-subclass scatter matrices. Effective low-dimensional face discriminative features are extracted for face recognition (FR) after performing discriminant evaluation in the entire eigenspace. Experimental results on popular face databases (AR, FERET) and the challenging unconstrained YouTube Face database show the superiority of our proposed approach on all three databases.
Appearance Based Robot and Human Activity Recognition System
Feb 10, 2016



In this work, we present an appearance based human activity recognition system. It uses background modeling to segment the foreground object and extracts useful discriminative features for representing activities performed by humans and robots. Subspace based method like principal component analysis is used to extract low dimensional features from large voluminous activity images. These low dimensional features are then used to classify an activity. An apparatus is designed using a webcam, which watches a robot replicating a human fall under indoor environment. In this apparatus, a robot performs various activities (like walking, bending, moving arms) replicating humans, which also includes a sudden fall. Experimental results on robot performing various activities and standard human activity recognition databases show the efficacy of our proposed method.
Face Recognition: Perspectives from the Real-World
Feb 09, 2016

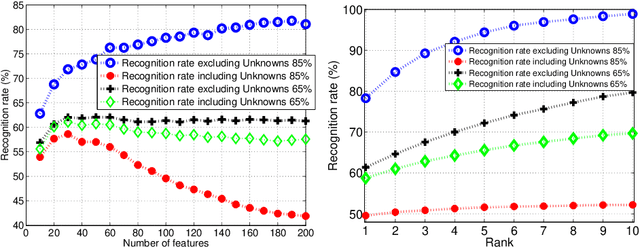
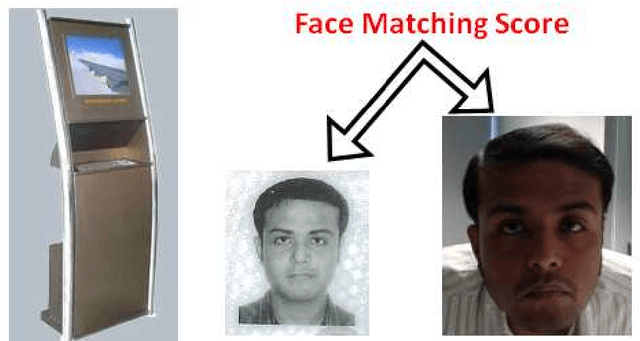
In this paper, we analyze some of our real-world deployment of face recognition (FR) systems for various applications and discuss the gaps between expectations of the user and what the system can deliver. We evaluate some of our proposed algorithms with ad-hoc modifications for applications such as FR on wearable devices (like Google Glass), monitoring of elderly people in senior citizens centers, FR of children in child care centers and face matching between a scanned IC/passport face image and a few live webcam images for automatic hotel/resort checkouts. We describe each of these applications, the challenges involved and proposed solutions. Since FR is intuitive in nature and we human beings use it for interactions with the outside world, people have high expectations of its performance in real-world scenarios. However, we analyze and discuss here that it is not the case, machine recognition of faces for each of these applications poses unique challenges and demands specific research components so as to adapt in the actual sites.