 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA pooling based scene text proposal technique for scene text reading in the wild
Nov 25, 2018


Automatic reading texts in scenes has attracted increasing interest in recent years as texts often carry rich semantic information that is useful for scene understanding. In this paper, we propose a novel scene text proposal technique aiming for accurate reading texts in scenes. Inspired by the pooling layer in the deep neural network architecture, a pooling based scene text proposal technique is developed. A novel score function is designed which exploits the histogram of oriented gradients and is capable of ranking the proposals according to their probabilities of being text. An end-to-end scene text reading system has also been developed by incorporating the proposed scene text proposal technique where false alarms elimination and words recognition are performed simultaneously. Extensive experiments over several public datasets show that the proposed technique can handle multi-orientation and multi-language scene texts and obtains outstanding proposal performance. The developed end-to-end systems also achieve very competitive scene text spotting and reading performance.
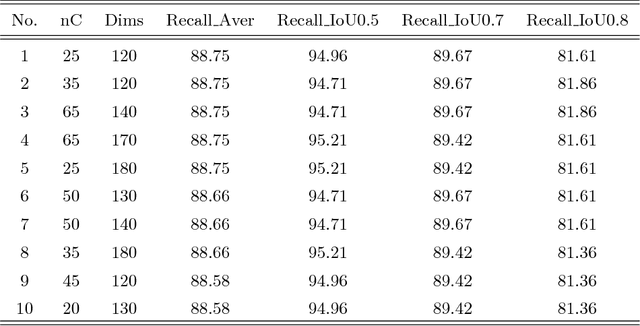
* The article has 34 pages with nine figures, six tables. It has been accepted to publish in Journal of Pattern Recognition
Out of the Black Box: Properties of deep neural networks and their applications
Aug 10, 2018



Deep neural networks are powerful machine learning approaches that have exhibited excellent results on many classification tasks. However, they are considered as black boxes and some of their properties remain to be formalized. In the context of image recognition, it is still an arduous task to understand why an image is recognized or not. In this study, we formalize some properties shared by eight state-of-the-art deep neural networks in order to grasp the principles allowing a given deep neural network to classify an image. Our results, tested on these eight networks, show that an image can be sub-divided into several regions (patches) responding at different degrees of probability (local property). With the same patch, some locations in the image can answer two (or three) orders of magnitude higher than other locations (spatial property). Some locations are activators and others inhibitors (activation-inhibition property). The repetition of the same patch can increase (or decrease) the probability of recognition of an object (cumulative property). Furthermore, we propose a new approach called Deepception that exploits these properties to deceive a deep neural network. We obtain for the VGG-VDD-19 neural network a fooling ratio of 88\%. Thanks to our "Psychophysics" approach, no prior knowledge on the networks architectures is required.
Distinguishing Posed and Spontaneous Smiles by Facial Dynamics
Feb 17, 2017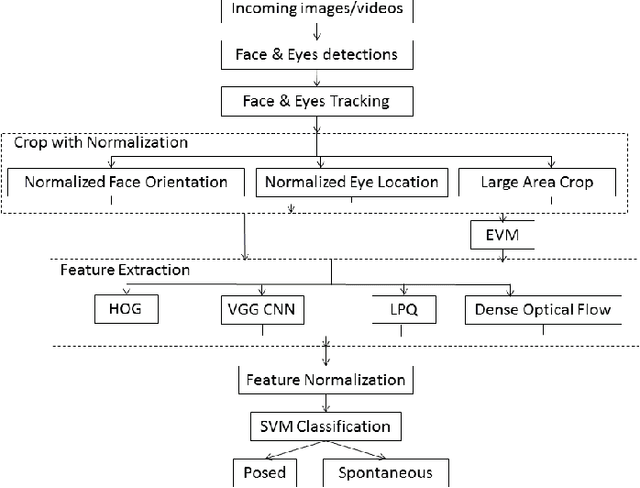
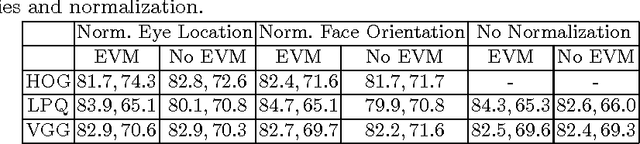
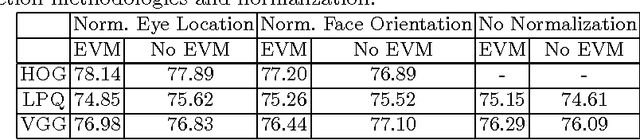
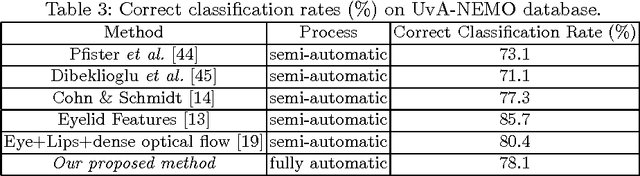
Smile is one of the key elements in identifying emotions and present state of mind of an individual. In this work, we propose a cluster of approaches to classify posed and spontaneous smiles using deep convolutional neural network (CNN) face features, local phase quantization (LPQ), dense optical flow and histogram of gradient (HOG). Eulerian Video Magnification (EVM) is used for micro-expression smile amplification along with three normalization procedures for distinguishing posed and spontaneous smiles. Although the deep CNN face model is trained with large number of face images, HOG features outperforms this model for overall face smile classification task. Using EVM to amplify micro-expressions did not have a significant impact on classification accuracy, while the normalizing facial features improved classification accuracy. Unlike many manual or semi-automatic methodologies, our approach aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large UvA-NEMO smile database show promising results as compared to other relevant methods.
Spontaneous vs. Posed smiles - can we tell the difference?
May 23, 2016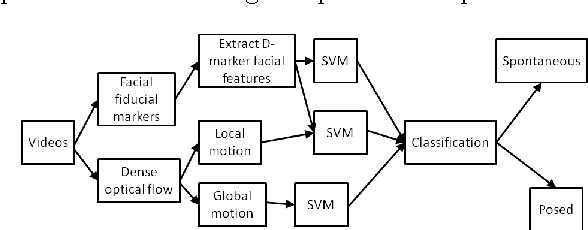


Smile is an irrefutable expression that shows the physical state of the mind in both true and deceptive ways. Generally, it shows happy state of the mind, however, `smiles' can be deceptive, for example people can give a smile when they feel happy and sometimes they might also give a smile (in a different way) when they feel pity for others. This work aims to distinguish spontaneous (felt) smile expressions from posed (deliberate) smiles by extracting and analyzing both global (macro) motion of the face and subtle (micro) changes in the facial expression features through both tracking a series of facial fiducial markers as well as using dense optical flow. Specifically the eyes and lips features are captured and used for analysis. It aims to automatically classify all smiles into either `spontaneous' or `posed' categories, by using support vector machines (SVM). Experimental results on large database show promising results as compared to other relevant methods.