 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFD$^2$: A Dedicated Framework for Fine-Grained Dataset Distillation
Mar 26, 2026Dataset distillation (DD) compresses a large training set into a small synthetic set, reducing storage and training cost, and has shown strong results on general benchmarks. Decoupled DD further improves efficiency by splitting the pipeline into pretraining, sample distillation, and soft-label generation. However, existing decoupled methods largely rely on coarse class-label supervision and optimize samples within each class in a nearly identical manner. On fine-grained datasets, this often yields distilled samples that (i) retain large intra-class variation with subtle inter-class differences and (ii) become overly similar within the same class, limiting localized discriminative cues and hurting recognition. To solve the above-mentioned problems, we propose FD$^{2}$, a dedicated framework for Fine-grained Dataset Distillation. FD$^{2}$ localizes discriminative regions and constructs fine-grained representations for distillation. During pretraining, counterfactual attention learning aggregates discriminative representations to update class prototypes. During distillation, a fine-grained characteristic constraint aligns each sample with its class prototype while repelling others, and a similarity constraint diversifies attention across same-class samples. Experiments on multiple fine-grained and general datasets show that FD$^{2}$ integrates seamlessly with decoupled DD and improves performance in most settings, indicating strong transferability.
Semantic decomposition Network with Contrastive and Structural Constraints for Dental Plaque Segmentation
Aug 12, 2022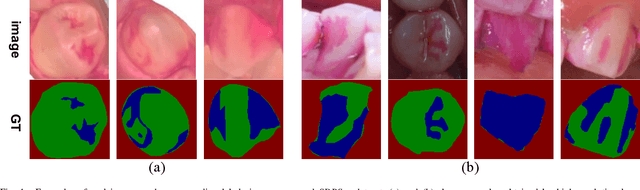
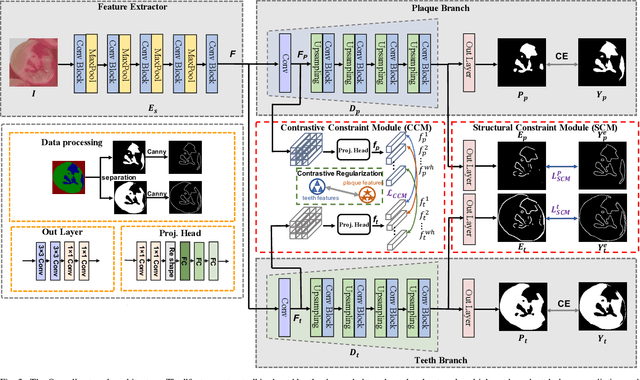

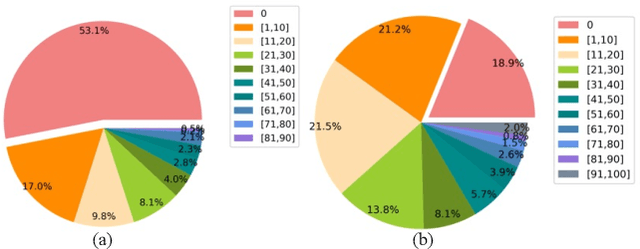
Segmenting dental plaque from images of medical reagent staining provides valuable information for diagnosis and the determination of follow-up treatment plan. However, accurate dental plaque segmentation is a challenging task that requires identifying teeth and dental plaque subjected to semantic-blur regions (i.e., confused boundaries in border regions between teeth and dental plaque) and complex variations of instance shapes, which are not fully addressed by existing methods. Therefore, we propose a semantic decomposition network (SDNet) that introduces two single-task branches to separately address the segmentation of teeth and dental plaque and designs additional constraints to learn category-specific features for each branch, thus facilitating the semantic decomposition and improving the performance of dental plaque segmentation. Specifically, SDNet learns two separate segmentation branches for teeth and dental plaque in a divide-and-conquer manner to decouple the entangled relation between them. Each branch that specifies a category tends to yield accurate segmentation. To help these two branches better focus on category-specific features, two constraint modules are further proposed: 1) contrastive constraint module (CCM) to learn discriminative feature representations by maximizing the distance between different category representations, so as to reduce the negative impact of semantic-blur regions on feature extraction; 2) structural constraint module (SCM) to provide complete structural information for dental plaque of various shapes by the supervision of an boundary-aware geometric constraint. Besides, we construct a large-scale open-source Stained Dental Plaque Segmentation dataset (SDPSeg), which provides high-quality annotations for teeth and dental plaque. Experimental results on SDPSeg datasets show SDNet achieves state-of-the-art performance.
Learning Scene Structure Guidance via Cross-Task Knowledge Transfer for Single Depth Super-Resolution
Mar 24, 2021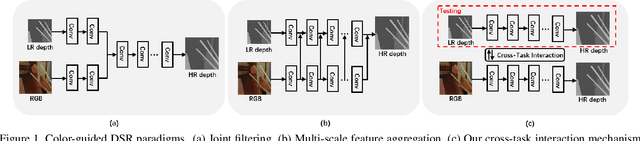
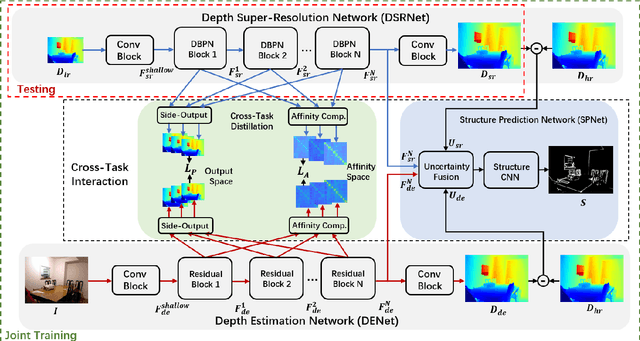
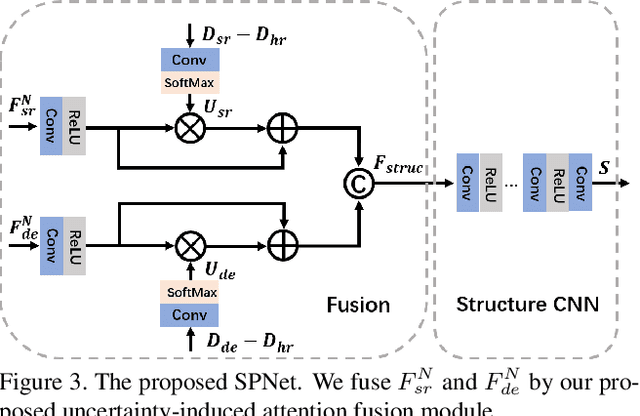

Existing color-guided depth super-resolution (DSR) approaches require paired RGB-D data as training samples where the RGB image is used as structural guidance to recover the degraded depth map due to their geometrical similarity. However, the paired data may be limited or expensive to be collected in actual testing environment. Therefore, we explore for the first time to learn the cross-modality knowledge at training stage, where both RGB and depth modalities are available, but test on the target dataset, where only single depth modality exists. Our key idea is to distill the knowledge of scene structural guidance from RGB modality to the single DSR task without changing its network architecture. Specifically, we construct an auxiliary depth estimation (DE) task that takes an RGB image as input to estimate a depth map, and train both DSR task and DE task collaboratively to boost the performance of DSR. Upon this, a cross-task interaction module is proposed to realize bilateral cross task knowledge transfer. First, we design a cross-task distillation scheme that encourages DSR and DE networks to learn from each other in a teacher-student role-exchanging fashion. Then, we advance a structure prediction (SP) task that provides extra structure regularization to help both DSR and DE networks learn more informative structure representations for depth recovery. Extensive experiments demonstrate that our scheme achieves superior performance in comparison with other DSR methods.