 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Graph Neural Networks with Agnostic Label Selection Bias
Jan 25, 2022
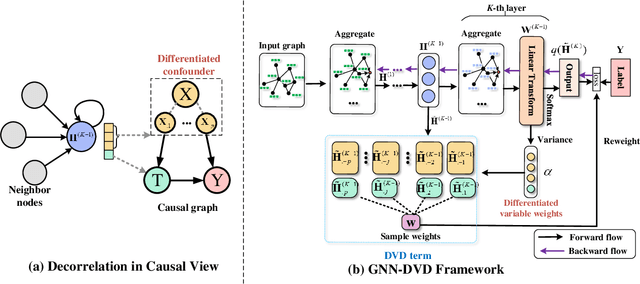
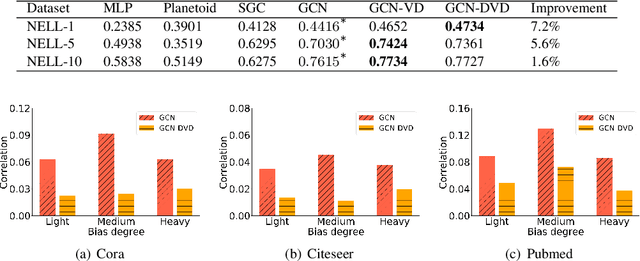
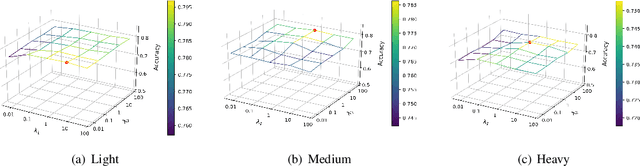
Most existing Graph Neural Networks (GNNs) are proposed without considering the selection bias in data, i.e., the inconsistent distribution between the training set with test set. In reality, the test data is not even available during the training process, making selection bias agnostic. Training GNNs with biased selected nodes leads to significant parameter estimation bias and greatly impacts the generalization ability on test nodes. In this paper, we first present an experimental investigation, which clearly shows that the selection bias drastically hinders the generalization ability of GNNs, and theoretically prove that the selection bias will cause the biased estimation on GNN parameters. Then to remove the bias in GNN estimation, we propose a novel Debiased Graph Neural Networks (DGNN) with a differentiated decorrelation regularizer. The differentiated decorrelation regularizer estimates a sample weight for each labeled node such that the spurious correlation of learned embeddings could be eliminated. We analyze the regularizer in causal view and it motivates us to differentiate the weights of the variables based on their contribution on the confounding bias. Then, these sample weights are used for reweighting GNNs to eliminate the estimation bias, thus help to improve the stability of prediction on unknown test nodes. Comprehensive experiments are conducted on several challenging graph datasets with two kinds of label selection biases. The results well verify that our proposed model outperforms the state-of-the-art methods and DGNN is a flexible framework to enhance existing GNNs.
Generalizing Graph Neural Networks on Out-Of-Distribution Graphs
Nov 23, 2021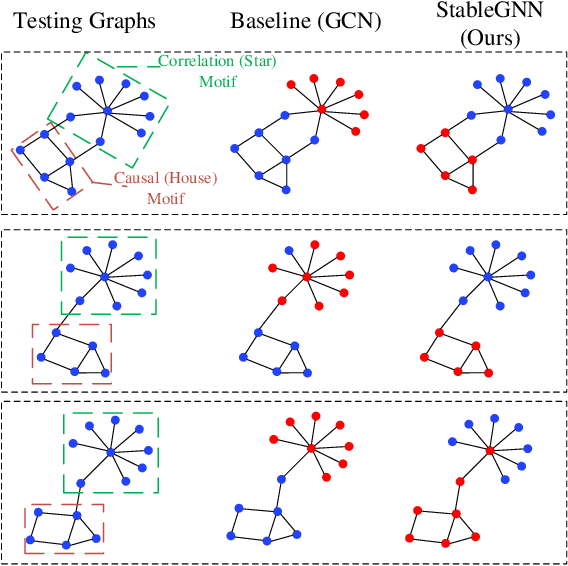
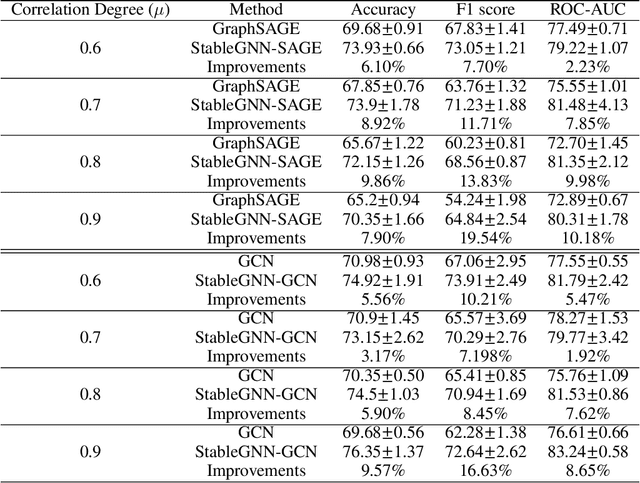
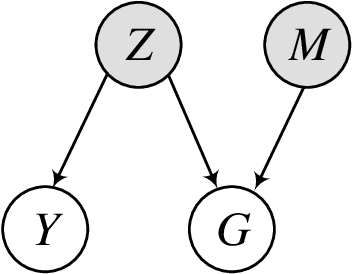
Graph Neural Networks (GNNs) are proposed without considering the agnostic distribution shifts between training and testing graphs, inducing the degeneration of the generalization ability of GNNs on Out-Of-Distribution (OOD) settings. The fundamental reason for such degeneration is that most GNNs are developed based on the I.I.D hypothesis. In such a setting, GNNs tend to exploit subtle statistical correlations existing in the training set for predictions, even though it is a spurious correlation. However, such spurious correlations may change in testing environments, leading to the failure of GNNs. Therefore, eliminating the impact of spurious correlations is crucial for stable GNNs. To this end, we propose a general causal representation framework, called StableGNN. The main idea is to extract high-level representations from graph data first and resort to the distinguishing ability of causal inference to help the model get rid of spurious correlations. Particularly, we exploit a graph pooling layer to extract subgraph-based representations as high-level representations. Furthermore, we propose a causal variable distinguishing regularizer to correct the biased training distribution. Hence, GNNs would concentrate more on the stable correlations. Extensive experiments on both synthetic and real-world OOD graph datasets well verify the effectiveness, flexibility and interpretability of the proposed framework.
Decorrelated Clustering with Data Selection Bias
Jul 02, 2020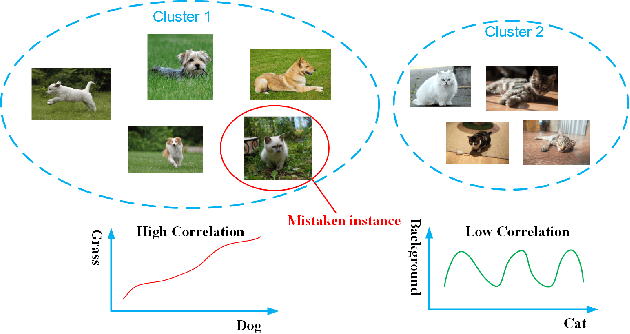
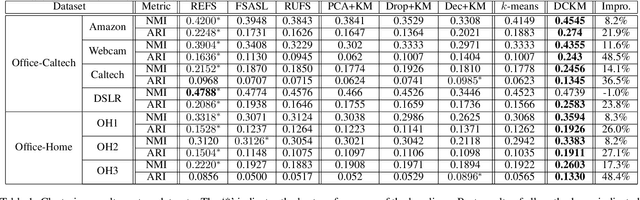
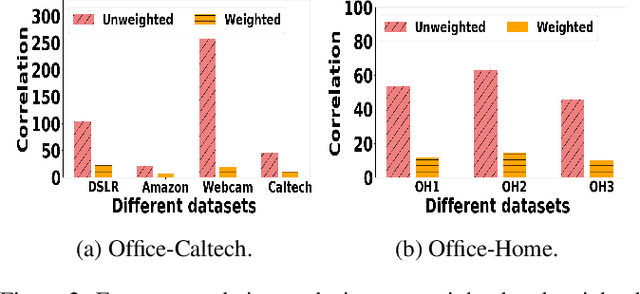
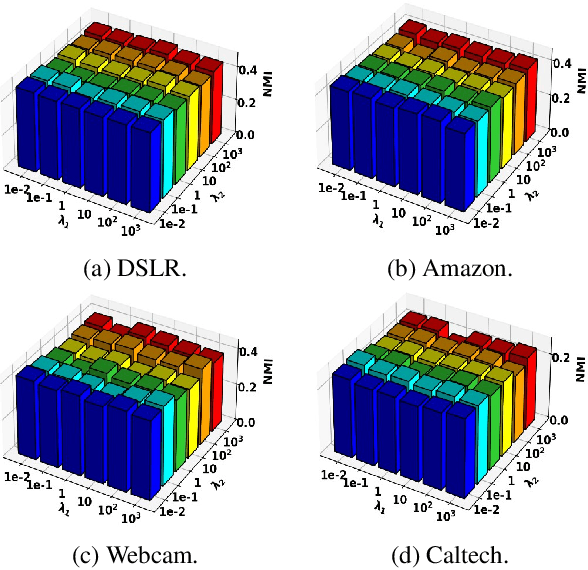
Most of existing clustering algorithms are proposed without considering the selection bias in data. In many real applications, however, one cannot guarantee the data is unbiased. Selection bias might bring the unexpected correlation between features and ignoring those unexpected correlations will hurt the performance of clustering algorithms. Therefore, how to remove those unexpected correlations induced by selection bias is extremely important yet largely unexplored for clustering. In this paper, we propose a novel Decorrelation regularized K-Means algorithm (DCKM) for clustering with data selection bias. Specifically, the decorrelation regularizer aims to learn the global sample weights which are capable of balancing the sample distribution, so as to remove unexpected correlations among features. Meanwhile, the learned weights are combined with k-means, which makes the reweighted k-means cluster on the inherent data distribution without unexpected correlation influence. Moreover, we derive the updating rules to effectively infer the parameters in DCKM. Extensive experiments results on real world datasets well demonstrate that our DCKM algorithm achieves significant performance gains, indicating the necessity of removing unexpected feature correlations induced by selection bias when clustering.
Inferring Social Status and Rich Club Effects in Enterprise Communication Networks
Apr 14, 2015
Social status, defined as the relative rank or position that an individual holds in a social hierarchy, is known to be among the most important motivating forces in social behaviors. In this paper, we consider the notion of status from the perspective of a position or title held by a person in an enterprise. We study the intersection of social status and social networks in an enterprise. We study whether enterprise communication logs can help reveal how social interactions and individual status manifest themselves in social networks. To that end, we use two enterprise datasets with three communication channels --- voice call, short message, and email --- to demonstrate the social-behavioral differences among individuals with different status. We have several interesting findings and based on these findings we also develop a model to predict social status. On the individual level, high-status individuals are more likely to be spanned as structural holes by linking to people in parts of the enterprise networks that are otherwise not well connected to one another. On the community level, the principle of homophily, social balance and clique theory generally indicate a "rich club" maintained by high-status individuals, in the sense that this community is much more connected, balanced and dense. Our model can predict social status of individuals with 93% accuracy.
* 13 pages, 4 figures