 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeighted Gaussian Process Bandits for Non-stationary Environments
Jul 06, 2021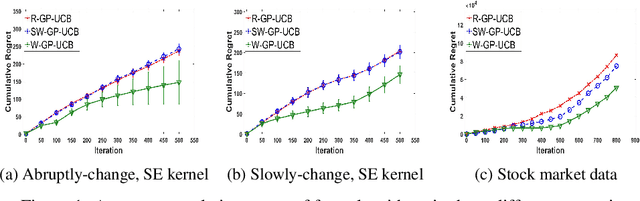



In this paper, we consider the Gaussian process (GP) bandit optimization problem in a non-stationary environment. To capture external changes, the black-box function is allowed to be time-varying within a reproducing kernel Hilbert space (RKHS). To this end, we develop WGP-UCB, a novel UCB-type algorithm based on weighted Gaussian process regression. A key challenge is how to cope with infinite-dimensional feature maps. To that end, we leverage kernel approximation techniques to prove a sublinear regret bound, which is the first (frequentist) sublinear regret guarantee on weighted time-varying bandits with general nonlinear rewards. This result generalizes both non-stationary linear bandits and standard GP-UCB algorithms. Further, a novel concentration inequality is achieved for weighted Gaussian process regression with general weights. We also provide universal upper bounds and weight-dependent upper bounds for weighted maximum information gains. These results are potentially of independent interest for applications such as news ranking and adaptive pricing, where weights can be adopted to capture the importance or quality of data. Finally, we conduct experiments to highlight the favorable gains of the proposed algorithm in many cases when compared to existing methods.
On the Equivalence between Online and Private Learnability beyond Binary Classification
Jun 02, 2020Alon et al. [2019] and Bun et al. [2020] recently showed that online learnability and private PAC learnability are equivalent in binary classification. We investigate whether this equivalence extends to multi-class classification and regression. First, we show that private learnability implies online learnability in both settings. Our extension involves studying a novel variant of the Littlestone dimension that depends on a tolerance parameter and on an appropriate generalization of the concept of threshold functions beyond binary classification. Second, we show that while online learnability continues to imply private learnability in multi-class classification, current proof techniques encounter significant hurdles in the regression setting. While the equivalence for regression remains open, we provide non-trivial sufficient conditions for an online learnable class to also be privately learnable.
Near-optimal Oracle-efficient Algorithms for Stationary and Non-Stationary Stochastic Linear Bandits
Jan 15, 2020
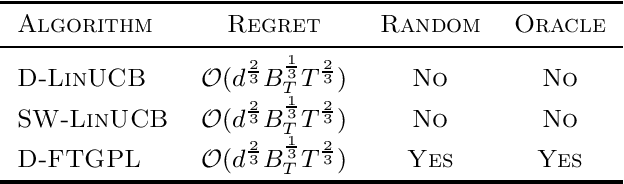
We investigate the design of two algorithms that enjoy not only computational efficiency induced by Hannan's perturbation approach, but also minimax-optimal regret bounds in linear bandit problems where the learner has access to an offline optimization oracle. We present an algorithm called Follow-The-Gaussian-Perturbed Leader (FTGPL) for stationary linear bandit where each action is associated with a $d$-dimensional feature vector, and prove that FTGPL (1) achieves the minimax-optimal $\tilde{\mathcal{O}}(d\sqrt{T})$ regret, (2) matches the empirical performance of Linear Thompson Sampling, and (3) can be efficiently implemented even in the case of infinite actions, thus achieving the best of three worlds. Furthermore, it firmly solves an open problem raised in \citet{abeille2017linear}, which perturbation achieves minimax-optimality in Linear Thompson Sampling. The weighted variant with exponential discounting, Discounted Follow-The-Gaussian-Perturbed Leader (D-FTGPL) is proposed to gracefully adjust to non-stationary environment where unknown parameter is time-varying within total variation $B_T$. It asymptotically achieves optimal dynamic regret $\tilde{\mathcal{O}}( d ^{2/3}B_T^{1/3} T^{2/3})$ and is oracle-efficient due to access to an offline optimization oracle induced by Gaussian perturbation.
On the Optimality of Perturbations in Stochastic and Adversarial Multi-armed Bandit Problems
Feb 15, 2019
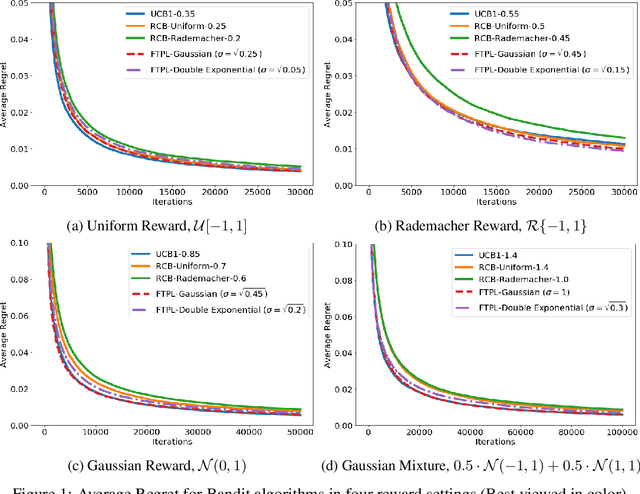
We investigate the optimality of perturbation based algorithms in the stochastic and adversarial multi-armed bandit problems. For the stochastic case, we provide a unified analysis for all sub-Weibull perturbations. The sub-Weibull family includes sub-Gaussian and sub-Exponential distributions. Our bounds are instance optimal for a range of the sub-Weibull parameter. For the adversarial setting, we prove rigorous barriers against two natural solution approaches using tools from discrete choice theory and extreme value theory. Our results suggest that the optimal perturbation, if it exists, will be of Frechet-type.