 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-optimal Oracle-efficient Algorithms for Stationary and Non-Stationary Stochastic Linear Bandits
Paper and Code

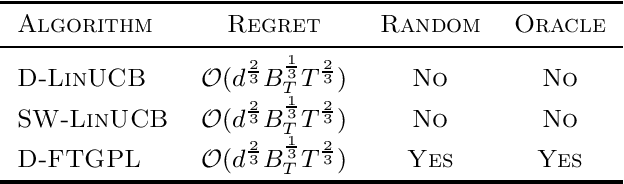
We investigate the design of two algorithms that enjoy not only computational efficiency induced by Hannan's perturbation approach, but also minimax-optimal regret bounds in linear bandit problems where the learner has access to an offline optimization oracle. We present an algorithm called Follow-The-Gaussian-Perturbed Leader (FTGPL) for stationary linear bandit where each action is associated with a $d$-dimensional feature vector, and prove that FTGPL (1) achieves the minimax-optimal $\tilde{\mathcal{O}}(d\sqrt{T})$ regret, (2) matches the empirical performance of Linear Thompson Sampling, and (3) can be efficiently implemented even in the case of infinite actions, thus achieving the best of three worlds. Furthermore, it firmly solves an open problem raised in \citet{abeille2017linear}, which perturbation achieves minimax-optimality in Linear Thompson Sampling. The weighted variant with exponential discounting, Discounted Follow-The-Gaussian-Perturbed Leader (D-FTGPL) is proposed to gracefully adjust to non-stationary environment where unknown parameter is time-varying within total variation $B_T$. It asymptotically achieves optimal dynamic regret $\tilde{\mathcal{O}}( d ^{2/3}B_T^{1/3} T^{2/3})$ and is oracle-efficient due to access to an offline optimization oracle induced by Gaussian perturbation.