 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Transformers for Weakly Supervised Object Localization in Unconstrained Videos
Jul 08, 2024



Weakly-Supervised Video Object Localization (WSVOL) involves localizing an object in videos using only video-level labels, also referred to as tags. State-of-the-art WSVOL methods like Temporal CAM (TCAM) rely on class activation mapping (CAM) and typically require a pre-trained CNN classifier. However, their localization accuracy is affected by their tendency to minimize the mutual information between different instances of a class and exploit temporal information during training for downstream tasks, e.g., detection and tracking. In the absence of bounding box annotation, it is challenging to exploit precise information about objects from temporal cues because the model struggles to locate objects over time. To address these issues, a novel method called transformer based CAM for videos (TrCAM-V), is proposed for WSVOL. It consists of a DeiT backbone with two heads for classification and localization. The classification head is trained using standard classification loss (CL), while the localization head is trained using pseudo-labels that are extracted using a pre-trained CLIP model. From these pseudo-labels, the high and low activation values are considered to be foreground and background regions, respectively. Our TrCAM-V method allows training a localization network by sampling pseudo-pixels on the fly from these regions. Additionally, a conditional random field (CRF) loss is employed to align the object boundaries with the foreground map. During inference, the model can process individual frames for real-time localization applications. Extensive experiments on challenging YouTube-Objects unconstrained video datasets show that our TrCAM-V method achieves new state-of-the-art performance in terms of classification and localization accuracy.
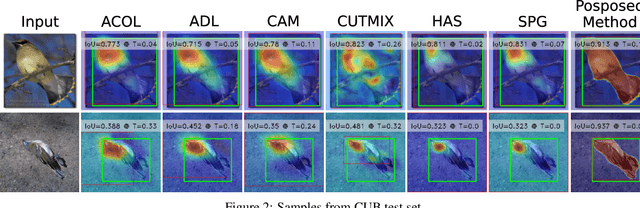
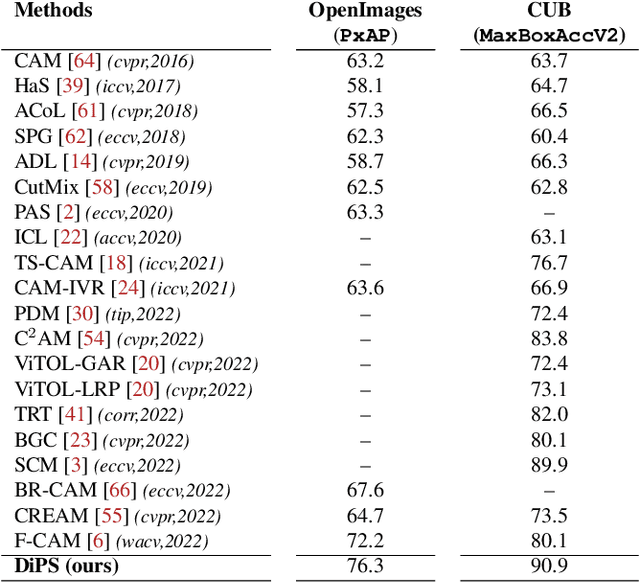
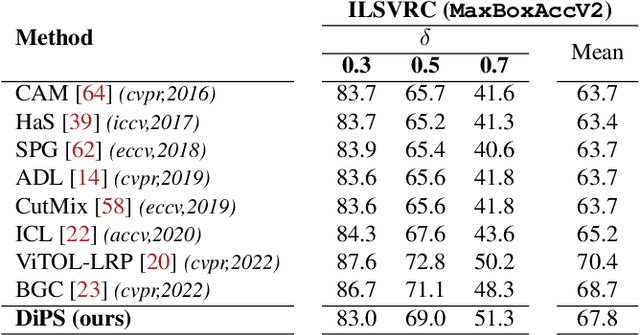
DiPS: Discriminative Pseudo-Label Sampling with Self-Supervised Transformers for Weakly Supervised Object Localization
Oct 19, 2023
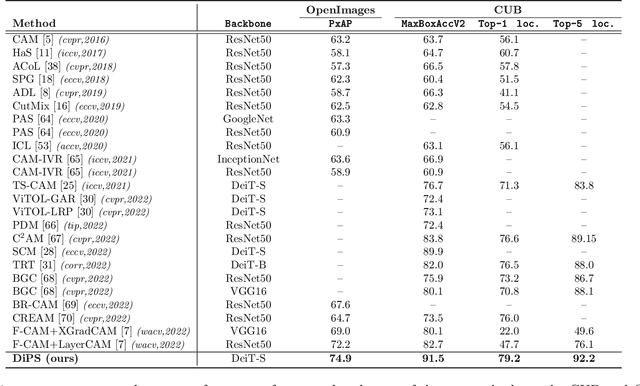
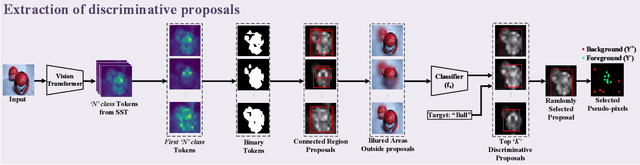
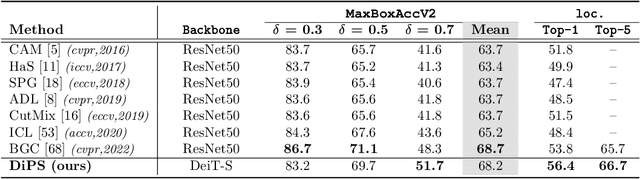
Self-supervised vision transformers (SSTs) have shown great potential to yield rich localization maps that highlight different objects in an image. However, these maps remain class-agnostic since the model is unsupervised. They often tend to decompose the image into multiple maps containing different objects while being unable to distinguish the object of interest from background noise objects. In this paper, Discriminative Pseudo-label Sampling (DiPS) is introduced to leverage these class-agnostic maps for weakly-supervised object localization (WSOL), where only image-class labels are available. Given multiple attention maps, DiPS relies on a pre-trained classifier to identify the most discriminative regions of each attention map. This ensures that the selected ROIs cover the correct image object while discarding the background ones, and, as such, provides a rich pool of diverse and discriminative proposals to cover different parts of the object. Subsequently, these proposals are used as pseudo-labels to train our new transformer-based WSOL model designed to perform classification and localization tasks. Unlike standard WSOL methods, DiPS optimizes performance in both tasks by using a transformer encoder and a dedicated output head for each task, each trained using dedicated loss functions. To avoid overfitting a single proposal and promote better object coverage, a single proposal is randomly selected among the top ones for a training image at each training step. Experimental results on the challenging CUB, ILSVRC, OpenImages, and TelDrone datasets indicate that our architecture, in combination with our transformer-based proposals, can yield better localization performance than state-of-the-art methods.
Constrained Sampling for Class-Agnostic Weakly Supervised Object Localization
Sep 09, 2022
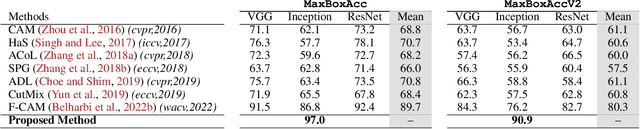
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new discriminative proposals sampling method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB benchmark dataset indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. Our method provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization
Sep 09, 2022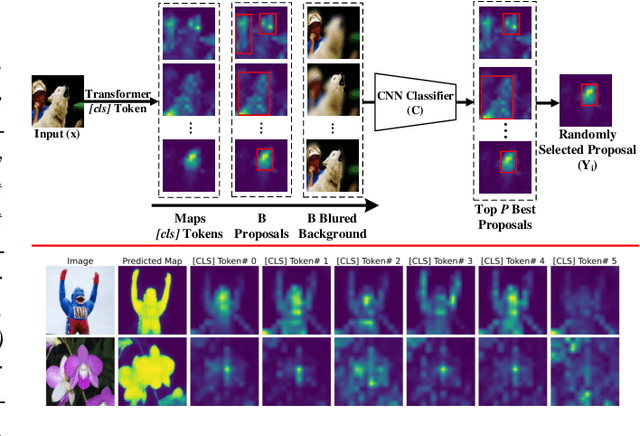
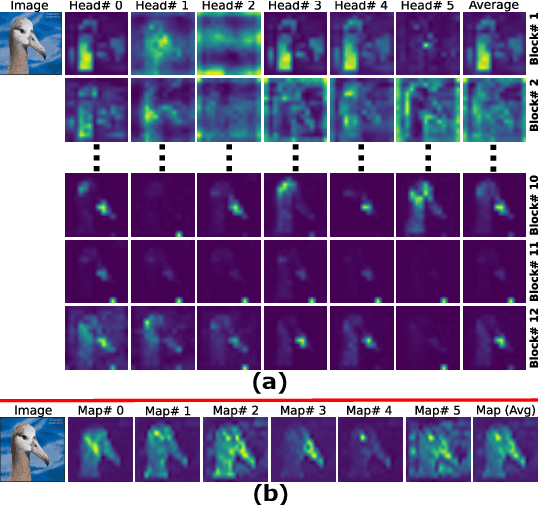
Self-supervised vision transformers can generate accurate localization maps of the objects in an image. However, since they decompose the scene into multiple maps containing various objects, and they do not rely on any explicit supervisory signal, they cannot distinguish between the object of interest from other objects, as required in weakly-supervised object localization (WSOL). To address this issue, we propose leveraging the multiple maps generated by the different transformer heads to acquire pseudo-labels for training a WSOL model. In particular, a new Discriminative Proposals Sampling (DiPS) method is introduced that relies on a pretrained CNN classifier to identify discriminative regions. Then, foreground and background pixels are sampled from these regions in order to train a WSOL model for generating activation maps that can accurately localize objects belonging to a specific class. Empirical results on the challenging CUB, OpenImages, and ILSVRC benchmark datasets indicate that our proposed approach can outperform state-of-art methods over a wide range of threshold values. DiPS provides class activation maps with a better coverage of foreground object regions w.r.t. the background.
F-CAM: Full Resolution CAM via Guided Parametric Upscaling
Sep 15, 2021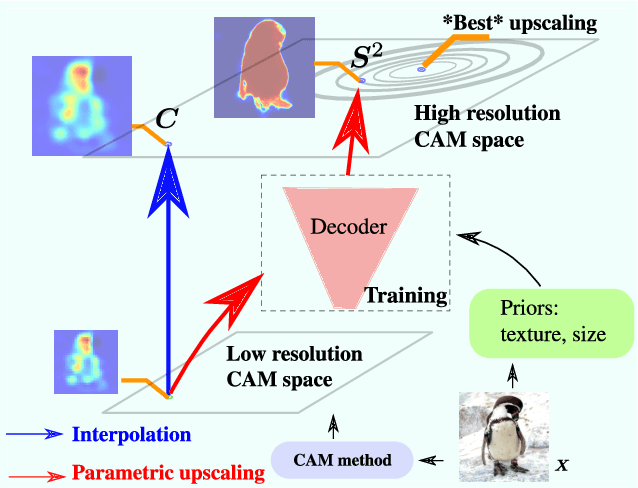
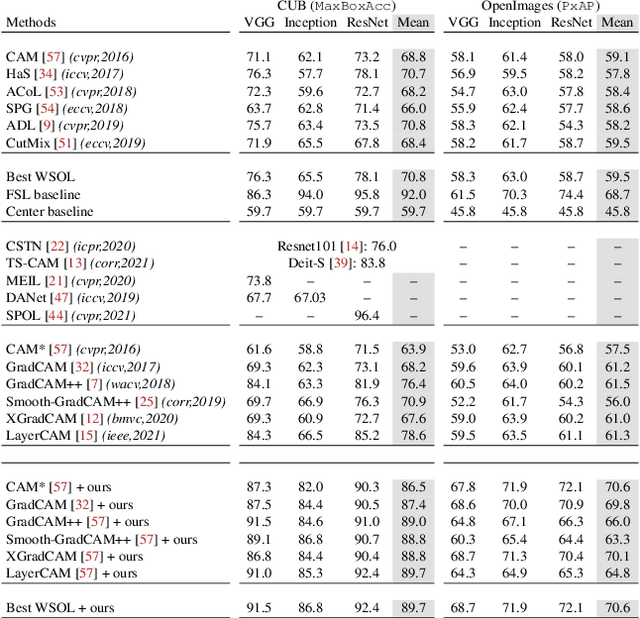
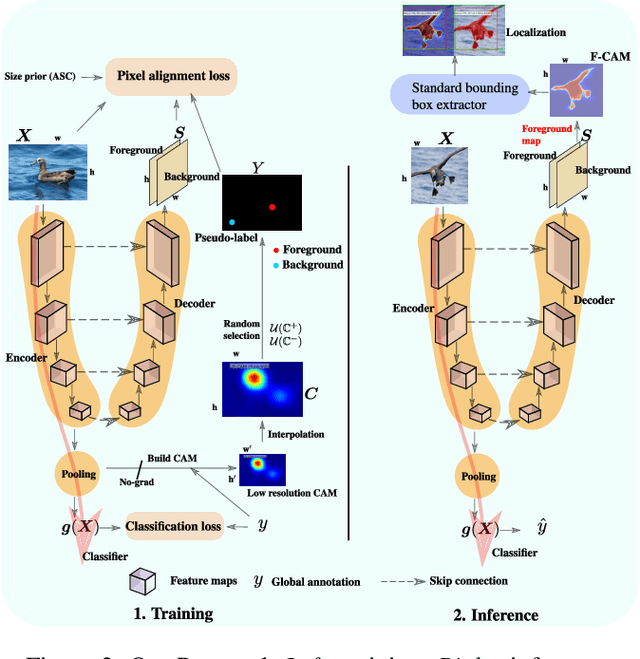
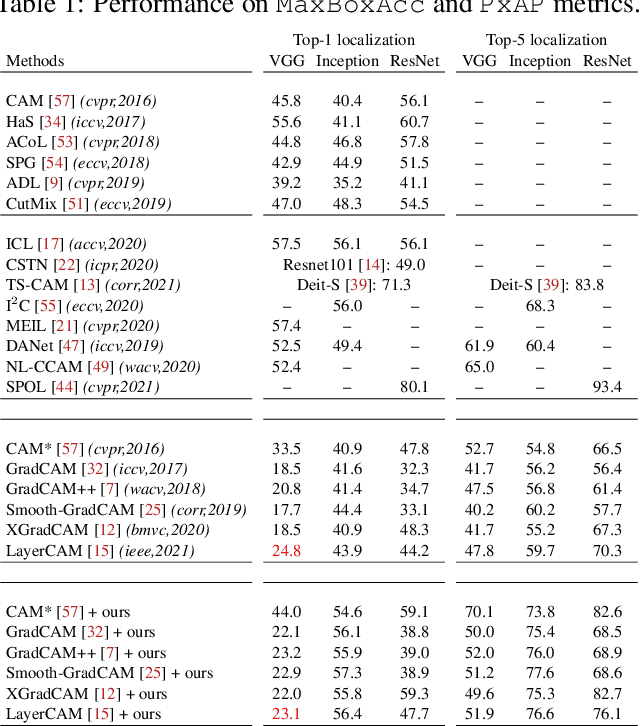
Class Activation Mapping (CAM) methods have recently gained much attention for weakly-supervised object localization (WSOL) tasks, allowing for CNN visualization and interpretation without training on fully annotated image datasets. CAM methods are typically integrated within off-the-shelf CNN backbones, such as ResNet50. Due to convolution and downsampling/pooling operations, these backbones yield low resolution CAMs with a down-scaling factor of up to 32, making accurate localization more difficult. Interpolation is required to restore a full size CAMs, but without considering the statistical properties of the objects, leading to activations with inconsistent boundaries and inaccurate localizations. As an alternative, we introduce a generic method for parametric upscaling of CAMs that allows constructing accurate full resolution CAMs (F-CAMs). In particular, we propose a trainable decoding architecture that can be connected to any CNN classifier to produce more accurate CAMs. Given an original (low resolution) CAM, foreground and background pixels are randomly sampled for fine-tuning the decoder. Additional priors such as image statistics, and size constraints are also considered to expand and refine object boundaries. Extensive experiments using three CNN backbones and six WSOL baselines on the CUB-200-2011 and OpenImages datasets, indicate that our F-CAM method yields a significant improvement in CAM localization accuracy. F-CAM performance is competitive with state-of-art WSOL methods, yet it requires fewer computational resources during inference.
Intelligent Link Adaptation for Grant-Free Access Cellular Networks: A Distributed Deep Reinforcement Learning Approach
Jul 08, 2021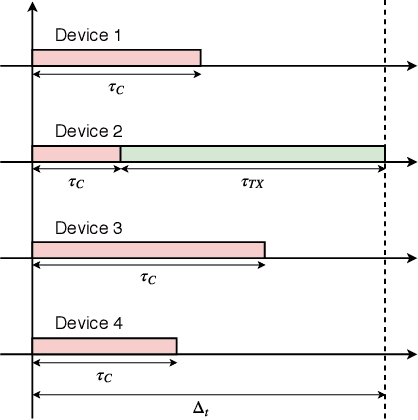
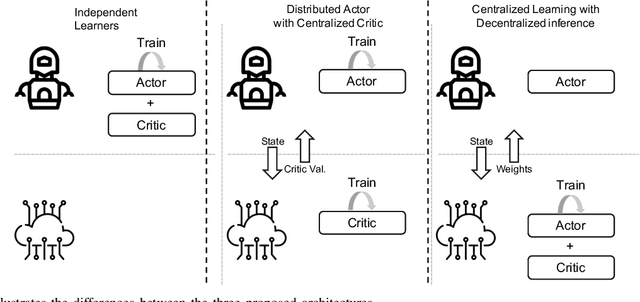
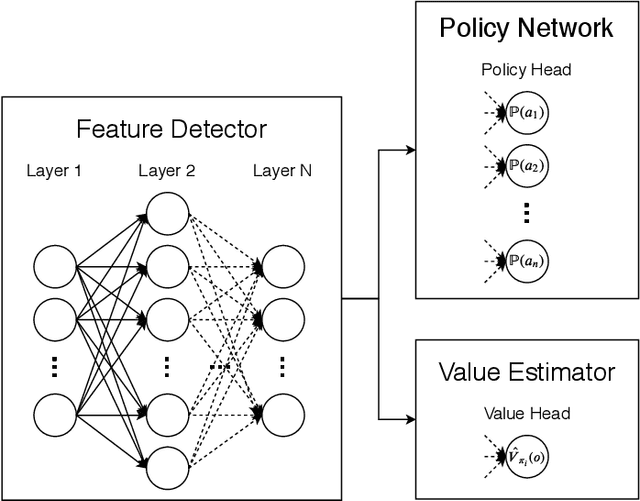
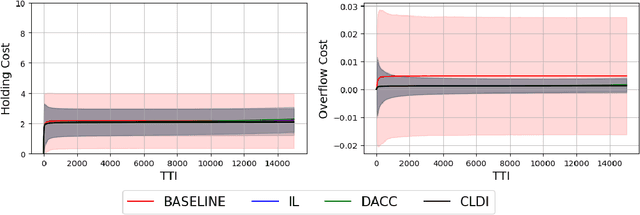
With the continuous growth of machine-type devices (MTDs), it is expected that massive machine-type communication (mMTC) will be the dominant form of traffic in future wireless networks. Applications based on this technology, have fundamentally different traffic characteristics from human-to-human (H2H) communication, which involves a relatively small number of devices transmitting large packets consistently. Conversely, in mMTC applications, a very large number of MTDs transmit small packets sporadically. Therefore, conventional grant-based access schemes commonly adopted for H2H service, are not suitable for mMTC, as they incur in a large overhead associated with the channel request procedure. We propose three grant-free distributed optimization architectures that are able to significantly minimize the average power consumption of the network. The problem of physical layer (PHY) and medium access control (MAC) optimization in grant-free random access transmission is is modeled as a partially observable stochastic game (POSG) aimed at minimizing the average transmit power under a per-device delay constraint. The results show that the proposed architectures are able to achieve significantly less average latency than a baseline, while spending less power. Moreover, the proposed architectures are more robust than the baseline, as they present less variance in the performance for different system realizations.