 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPS: Discriminative Pseudo-Label Sampling with Self-Supervised Transformers for Weakly Supervised Object Localization
Paper and Code

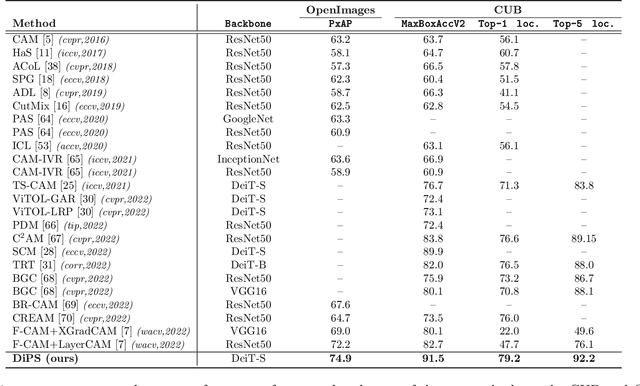
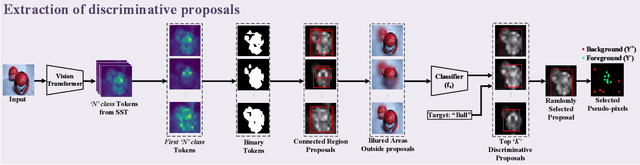
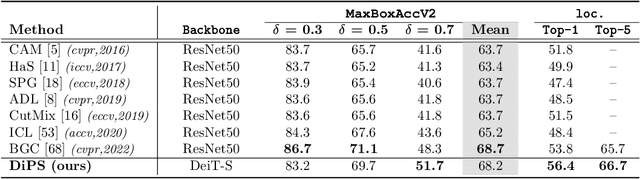
Self-supervised vision transformers (SSTs) have shown great potential to yield rich localization maps that highlight different objects in an image. However, these maps remain class-agnostic since the model is unsupervised. They often tend to decompose the image into multiple maps containing different objects while being unable to distinguish the object of interest from background noise objects. In this paper, Discriminative Pseudo-label Sampling (DiPS) is introduced to leverage these class-agnostic maps for weakly-supervised object localization (WSOL), where only image-class labels are available. Given multiple attention maps, DiPS relies on a pre-trained classifier to identify the most discriminative regions of each attention map. This ensures that the selected ROIs cover the correct image object while discarding the background ones, and, as such, provides a rich pool of diverse and discriminative proposals to cover different parts of the object. Subsequently, these proposals are used as pseudo-labels to train our new transformer-based WSOL model designed to perform classification and localization tasks. Unlike standard WSOL methods, DiPS optimizes performance in both tasks by using a transformer encoder and a dedicated output head for each task, each trained using dedicated loss functions. To avoid overfitting a single proposal and promote better object coverage, a single proposal is randomly selected among the top ones for a training image at each training step. Experimental results on the challenging CUB, ILSVRC, OpenImages, and TelDrone datasets indicate that our architecture, in combination with our transformer-based proposals, can yield better localization performance than state-of-the-art methods.