 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Coverage Path Planning: Can UAV Swarms Perfect Scattered Regions Inspections?
Dec 29, 2025Unmanned Aerial Vehicles (UAVs) have revolutionized inspection tasks by offering a safer, more efficient, and flexible alternative to traditional methods. However, battery limitations often constrain their effectiveness, necessitating the development of optimized flight paths and data collection techniques. While existing approaches like coverage path planning (CPP) ensure comprehensive data collection, they can be inefficient, especially when inspecting multiple non connected Regions of Interest (ROIs). This paper introduces the Fast Inspection of Scattered Regions (FISR) problem and proposes a novel solution, the multi UAV Disjoint Areas Inspection (mUDAI) method. The introduced approach implements a two fold optimization procedure, for calculating the best image capturing positions and the most efficient UAV trajectories, balancing data resolution and operational time, minimizing redundant data collection and resource consumption. The mUDAI method is designed to enable rapid, efficient inspections of scattered ROIs, making it ideal for applications such as security infrastructure assessments, agricultural inspections, and emergency site evaluations. A combination of simulated evaluations and real world deployments is used to validate and quantify the method's ability to improve operational efficiency while preserving high quality data capture, demonstrating its effectiveness in real world operations. An open source Python implementation of the mUDAI method can be found on GitHub (https://github.com/soc12/mUDAI) and the collected and processed data from the real world experiments are all hosted on Zenodo (https://zenodo.org/records/13866483). Finally, this online platform (https://sites.google.com/view/mudai-platform/) allows interested readers to interact with the mUDAI method and generate their own multi UAV FISR missions.
Terrain-Aware Adaptation for Two-Dimensional UAV Path Planners
Jul 24, 2025Multi-UAV Coverage Path Planning (mCPP) algorithms in popular commercial software typically treat a Region of Interest (RoI) only as a 2D plane, ignoring important3D structure characteristics. This leads to incomplete 3Dreconstructions, especially around occluded or vertical surfaces. In this paper, we propose a modular algorithm that can extend commercial two-dimensional path planners to facilitate terrain-aware planning by adjusting altitude and camera orientations. To demonstrate it, we extend the well-known DARP (Divide Areas for Optimal Multi-Robot Coverage Path Planning) algorithm and produce DARP-3D. We present simulation results in multiple 3D environments and a real-world flight test using DJI hardware. Compared to baseline, our approach consistently captures improved 3D reconstructions, particularly in areas with significant vertical features. An open-source implementation of the algorithm is available here:https://github.com/konskara/TerraPlan
RobotIQ: Empowering Mobile Robots with Human-Level Planning for Real-World Execution
Feb 18, 2025

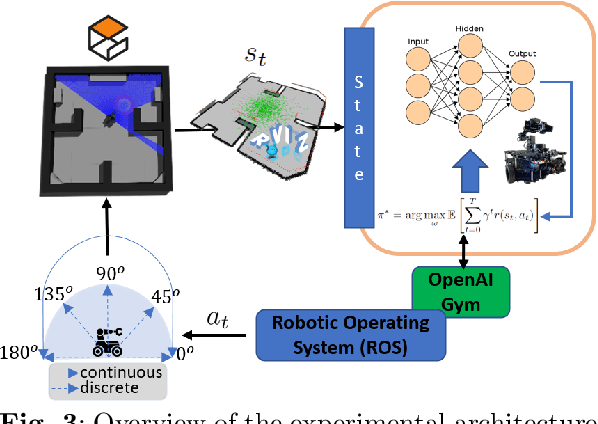

This paper introduces RobotIQ, a framework that empowers mobile robots with human-level planning capabilities, enabling seamless communication via natural language instructions through any Large Language Model. The proposed framework is designed in the ROS architecture and aims to bridge the gap between humans and robots, enabling robots to comprehend and execute user-expressed text or voice commands. Our research encompasses a wide spectrum of robotic tasks, ranging from fundamental logical, mathematical, and learning reasoning for transferring knowledge in domains like navigation, manipulation, and object localization, enabling the application of learned behaviors from simulated environments to real-world operations. All encapsulated within a modular crafted robot library suite of API-wise control functions, RobotIQ offers a fully functional AI-ROS-based toolset that allows researchers to design and develop their own robotic actions tailored to specific applications and robot configurations. The effectiveness of the proposed system was tested and validated both in simulated and real-world experiments focusing on a home service scenario that included an assistive application designed for elderly people. RobotIQ with an open-source, easy-to-use, and adaptable robotic library suite for any robot can be found at https://github.com/emmarapt/RobotIQ.
Overcome the Fear Of Missing Out: Active Sensing UAV Scanning for Precision Agriculture
Dec 15, 2023This paper deals with the problem of informative path planning for a UAV deployed for precision agriculture applications. First, we observe that the ``fear of missing out'' data lead to uniform, conservative scanning policies over the whole agricultural field. Consequently, employing a non-uniform scanning approach can mitigate the expenditure of time in areas with minimal or negligible real value, while ensuring heightened precision in information-dense regions. Turning to the available informative path planning methodologies, we discern that certain methods entail intensive computational requirements, while others necessitate training on an ideal world simulator. To address the aforementioned issues, we propose an active sensing coverage path planning approach, named OverFOMO, that regulates the speed of the UAV in accordance with both the relative quantity of the identified classes, i.e. crops and weeds, and the confidence level of such detections. To identify these instances, a robust Deep Learning segmentation model is deployed. The computational needs of the proposed algorithm are independent of the size of the agricultural field, rendering its applicability on modern UAVs quite straightforward. The proposed algorithm was evaluated with a simu-realistic pipeline, combining data from real UAV missions and the high-fidelity dynamics of AirSim simulator, showcasing its performance improvements over the established state of affairs for this type of missions. An open-source implementation of the algorithm and the evaluation pipeline is also available: \url{https://github.com/emmarapt/OverFOMO}.
Cooperative Multi-UAV Coverage Mission Planning Platform for Remote Sensing Applications
Jan 19, 2022



This paper proposes a novel mission planning platform, capable of efficiently deploying a team of UAVs to cover complex-shaped areas, in various remote sensing applications. Under the hood lies a novel optimization scheme for grid-based methods, utilizing Simulated Annealing algorithm, that significantly increases the achieved percentage of coverage and improves the qualitative features of the generated paths. Extensive simulated evaluation in comparison with a state-of-the-art alternative methodology, for coverage path planning (CPP) operations, establishes the performance gains in terms of achieved coverage and overall duration of the generated missions. On top of that, DARP algorithm is employed to allocate sub-tasks to each member of the swarm, taking into account each UAV's sensing and operational capabilities, their initial positions and any no-fly-zones possibly defined inside the operational area. This feature is of paramount importance in real-life applications, as it has the potential to achieve tremendous performance improvements in terms of time demanded to complete a mission, while at the same time it unlocks a wide new range of applications, that was previously not feasible due to the limited battery life of UAVs. In order to investigate the actual efficiency gains that are introduced by the multi-UAV utilization, a simulated study is performed as well. All of these capabilities are packed inside an end-to-end platform that eases the utilization of UAVs' swarms in remote sensing applications. Its versatility is demonstrated via two different real-life applications: (i) a photogrametry for precision agriculture and (ii) an indicative search and rescue for first responders missions, that were performed utilizing a swarm of commercial UAVs. The source code can be found at: https://github.com/savvas-ap/mCPP-optimized-DARP
* An implementation of the mCPP methodology introduced in this work, as well as a link for a demonstrative video and a link for a fully functional, on-line hosted instance of the presented platform can be found here: https://github.com/savvas-ap/mCPP-optimized-DARP
A distributed, plug-n-play algorithm for multi-robot applications with a priori non-computable objective functions
Nov 14, 2021


This paper presents a distributed algorithm applicable to a wide range of practical multi-robot applications. In such multi-robot applications, the user-defined objectives of the mission can be cast as a general optimization problem, without explicit guidelines of the subtasks per different robot. Owing to the unknown environment, unknown robot dynamics, sensor nonlinearities, etc., the analytic form of the optimization cost function is not available a priori. Therefore, standard gradient-descent-like algorithms are not applicable to these problems. To tackle this, we introduce a new algorithm that carefully designs each robot's subcost function, the optimization of which can accomplish the overall team objective. Upon this transformation, we propose a distributed methodology based on the cognitive-based adaptive optimization (CAO) algorithm, that is able to approximate the evolution of each robot's cost function and to adequately optimize its decision variables (robot actions). The latter can be achieved by online learning only the problem-specific characteristics that affect the accomplishment of mission objectives. The overall, low-complexity algorithm can straightforwardly incorporate any kind of operational constraint, is fault tolerant, and can appropriately tackle time-varying cost functions. A cornerstone of this approach is that it shares the same convergence characteristics as those of block coordinate descent algorithms. The proposed algorithm is evaluated in three heterogeneous simulation set-ups under multiple scenarios, against both general-purpose and problem-specific algorithms. Source code is available at \url{https://github.com/athakapo/A-distributed-plug-n-play-algorithm-for-multi-robot-applications}.
MarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments
Jul 21, 2021
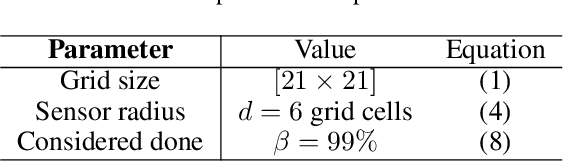
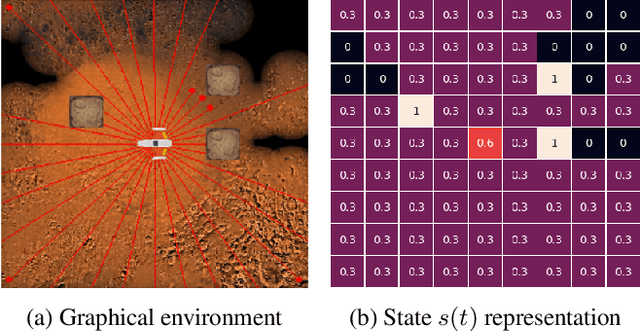
This paper is an initial endeavor to bridge the gap between powerful Deep Reinforcement Learning methodologies and the problem of exploration/coverage of unknown terrains. Within this scope, MarsExplorer, an openai-gym compatible environment tailored to exploration/coverage of unknown areas, is presented. MarsExplorer translates the original robotics problem into a Reinforcement Learning setup that various off-the-shelf algorithms can tackle. Any learned policy can be straightforwardly applied to a robotic platform without an elaborate simulation model of the robot's dynamics to apply a different learning/adaptation phase. One of its core features is the controllable multi-dimensional procedural generation of terrains, which is the key for producing policies with strong generalization capabilities. Four different state-of-the-art RL algorithms (A3C, PPO, Rainbow, and SAC) are trained on the MarsExplorer environment, and a proper evaluation of their results compared to the average human-level performance is reported. In the follow-up experimental analysis, the effect of the multi-dimensional difficulty setting on the learning capabilities of the best-performing algorithm (PPO) is analyzed. A milestone result is the generation of an exploration policy that follows the Hilbert curve without providing this information to the environment or rewarding directly or indirectly Hilbert-curve-like trajectories. The experimental analysis is concluded by comparing PPO learned policy results with frontier-based exploration context for extended terrain sizes. The source code can be found at: https://github.com/dimikout3/GeneralExplorationPolicy.
Autonomous and cooperative design of the monitor positions for a team of UAVs to maximize the quantity and quality of detected objects
Jul 02, 2020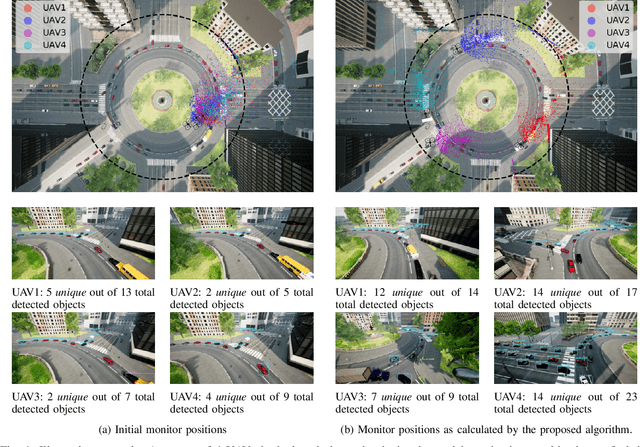



This paper tackles the problem of positioning a swarm of UAVs inside a completely unknown terrain, having as objective to maximize the overall situational awareness. The situational awareness is expressed by the number and quality of unique objects of interest, inside the UAVs' fields of view. YOLOv3 and a system to identify duplicate objects of interest were employed to assign a single score to each UAVs' configuration. Then, a novel navigation algorithm, capable of optimizing the previously defined score, without taking into consideration the dynamics of either UAVs or environment, is proposed. A cornerstone of the proposed approach is that it shares the same convergence characteristics as the block coordinate descent (BCD) family of approaches. The effectiveness and performance of the proposed navigation scheme were evaluated utilizing a series of experiments inside the AirSim simulator. The experimental evaluation indicates that the proposed navigation algorithm was able to consistently navigate the swarm of UAVs to "strategic" monitoring positions and also adapt to the different number of swarm sizes. Source code is available at https://github.com/dimikout3/ConvCAOAirSim.