 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA distributed, plug-n-play algorithm for multi-robot applications with a priori non-computable objective functions
Nov 14, 2021


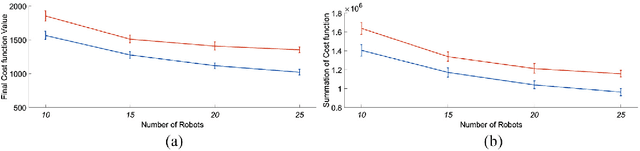
This paper presents a distributed algorithm applicable to a wide range of practical multi-robot applications. In such multi-robot applications, the user-defined objectives of the mission can be cast as a general optimization problem, without explicit guidelines of the subtasks per different robot. Owing to the unknown environment, unknown robot dynamics, sensor nonlinearities, etc., the analytic form of the optimization cost function is not available a priori. Therefore, standard gradient-descent-like algorithms are not applicable to these problems. To tackle this, we introduce a new algorithm that carefully designs each robot's subcost function, the optimization of which can accomplish the overall team objective. Upon this transformation, we propose a distributed methodology based on the cognitive-based adaptive optimization (CAO) algorithm, that is able to approximate the evolution of each robot's cost function and to adequately optimize its decision variables (robot actions). The latter can be achieved by online learning only the problem-specific characteristics that affect the accomplishment of mission objectives. The overall, low-complexity algorithm can straightforwardly incorporate any kind of operational constraint, is fault tolerant, and can appropriately tackle time-varying cost functions. A cornerstone of this approach is that it shares the same convergence characteristics as those of block coordinate descent algorithms. The proposed algorithm is evaluated in three heterogeneous simulation set-ups under multiple scenarios, against both general-purpose and problem-specific algorithms. Source code is available at \url{https://github.com/athakapo/A-distributed-plug-n-play-algorithm-for-multi-robot-applications}.
Investigating the Vision Transformer Model for Image Retrieval Tasks
Jan 11, 2021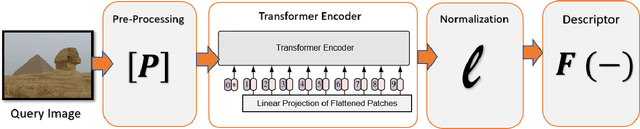
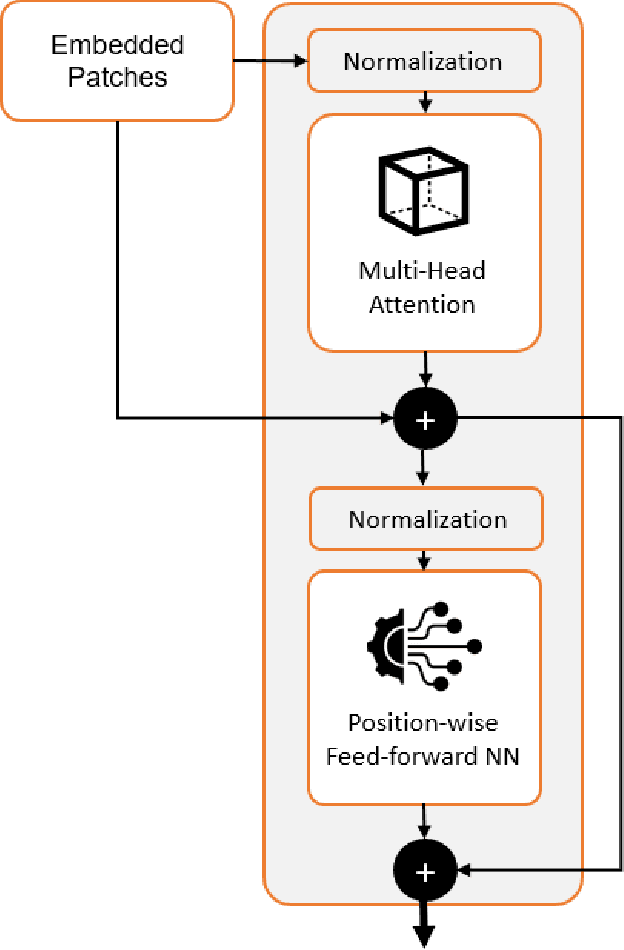
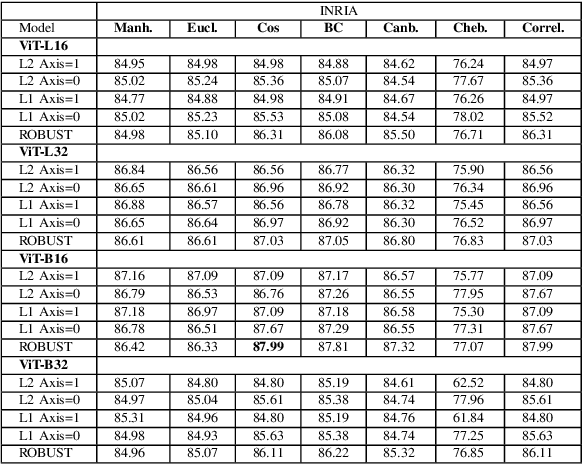
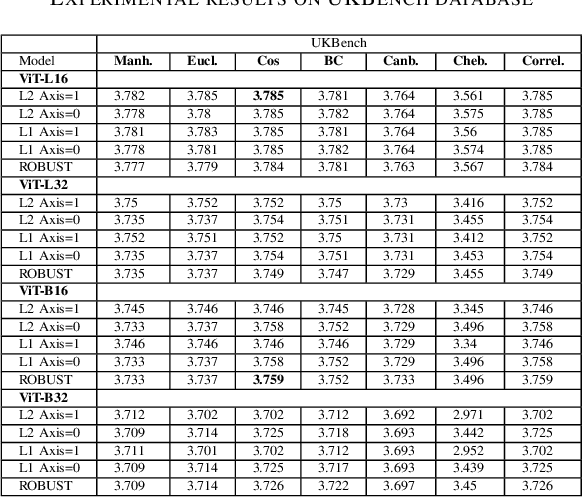
This paper introduces a plug-and-play descriptor that can be effectively adopted for image retrieval tasks without prior initialization or preparation. The description method utilizes the recently proposed Vision Transformer network while it does not require any training data to adjust parameters. In image retrieval tasks, the use of Handcrafted global and local descriptors has been very successfully replaced, over the last years, by the Convolutional Neural Networks (CNN)-based methods. However, the experimental evaluation conducted in this paper on several benchmarking datasets against 36 state-of-the-art descriptors from the literature demonstrates that a neural network that contains no convolutional layer, such as Vision Transformer, can shape a global descriptor and achieve competitive results. As fine-tuning is not required, the presented methodology's low complexity encourages adoption of the architecture as an image retrieval baseline model, replacing the traditional and well adopted CNN-based approaches and inaugurating a new era in image retrieval approaches.