 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Coverage Path Planning: Can UAV Swarms Perfect Scattered Regions Inspections?
Dec 29, 2025Unmanned Aerial Vehicles (UAVs) have revolutionized inspection tasks by offering a safer, more efficient, and flexible alternative to traditional methods. However, battery limitations often constrain their effectiveness, necessitating the development of optimized flight paths and data collection techniques. While existing approaches like coverage path planning (CPP) ensure comprehensive data collection, they can be inefficient, especially when inspecting multiple non connected Regions of Interest (ROIs). This paper introduces the Fast Inspection of Scattered Regions (FISR) problem and proposes a novel solution, the multi UAV Disjoint Areas Inspection (mUDAI) method. The introduced approach implements a two fold optimization procedure, for calculating the best image capturing positions and the most efficient UAV trajectories, balancing data resolution and operational time, minimizing redundant data collection and resource consumption. The mUDAI method is designed to enable rapid, efficient inspections of scattered ROIs, making it ideal for applications such as security infrastructure assessments, agricultural inspections, and emergency site evaluations. A combination of simulated evaluations and real world deployments is used to validate and quantify the method's ability to improve operational efficiency while preserving high quality data capture, demonstrating its effectiveness in real world operations. An open source Python implementation of the mUDAI method can be found on GitHub (https://github.com/soc12/mUDAI) and the collected and processed data from the real world experiments are all hosted on Zenodo (https://zenodo.org/records/13866483). Finally, this online platform (https://sites.google.com/view/mudai-platform/) allows interested readers to interact with the mUDAI method and generate their own multi UAV FISR missions.
Investigating the Vision Transformer Model for Image Retrieval Tasks
Jan 11, 2021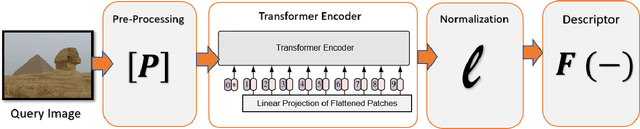
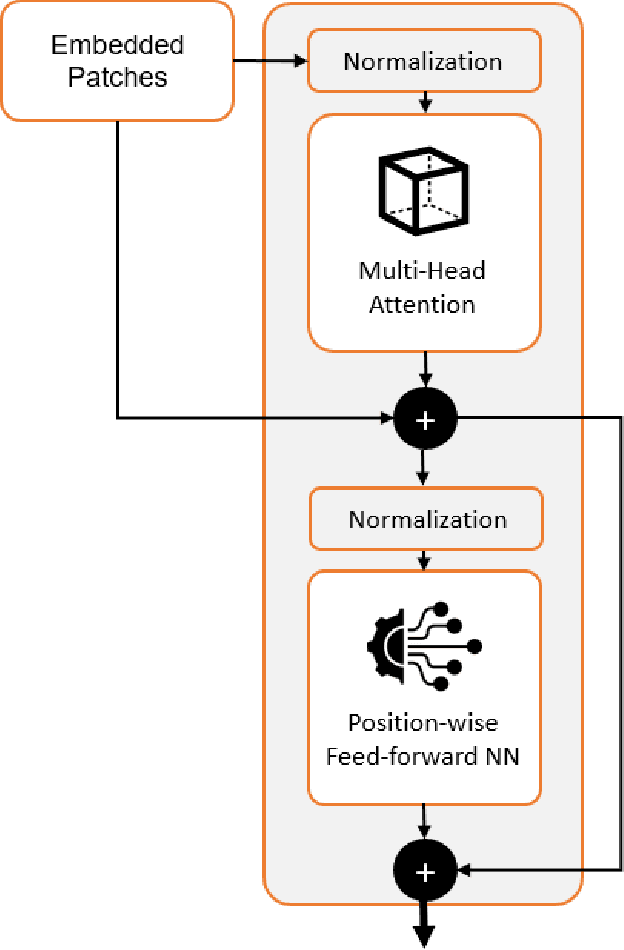
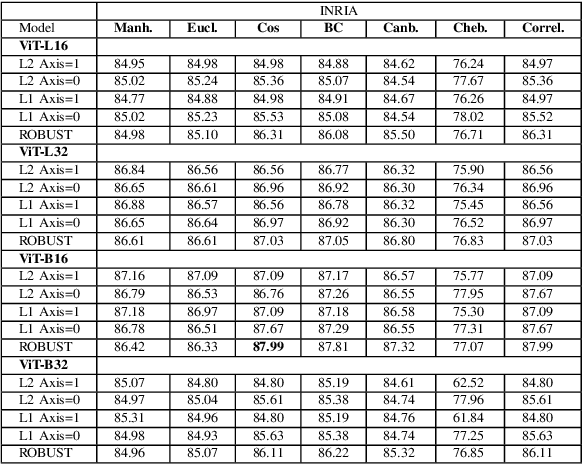
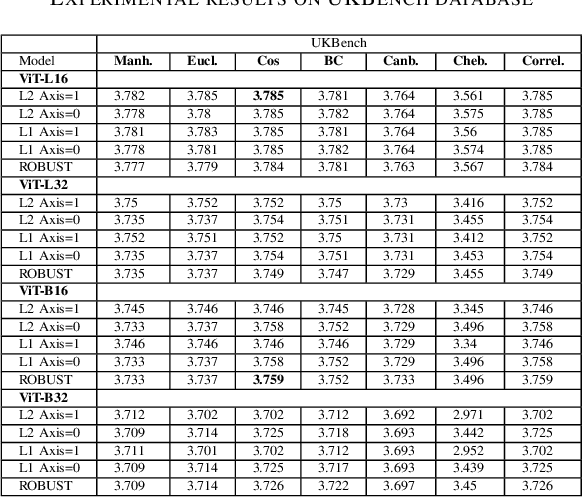
This paper introduces a plug-and-play descriptor that can be effectively adopted for image retrieval tasks without prior initialization or preparation. The description method utilizes the recently proposed Vision Transformer network while it does not require any training data to adjust parameters. In image retrieval tasks, the use of Handcrafted global and local descriptors has been very successfully replaced, over the last years, by the Convolutional Neural Networks (CNN)-based methods. However, the experimental evaluation conducted in this paper on several benchmarking datasets against 36 state-of-the-art descriptors from the literature demonstrates that a neural network that contains no convolutional layer, such as Vision Transformer, can shape a global descriptor and achieve competitive results. As fine-tuning is not required, the presented methodology's low complexity encourages adoption of the architecture as an image retrieval baseline model, replacing the traditional and well adopted CNN-based approaches and inaugurating a new era in image retrieval approaches.