 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Vision Transformer Model for Image Retrieval Tasks
Paper and Code
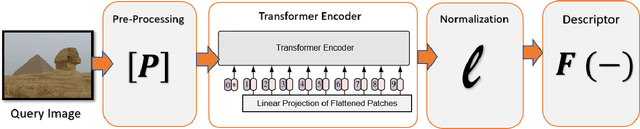
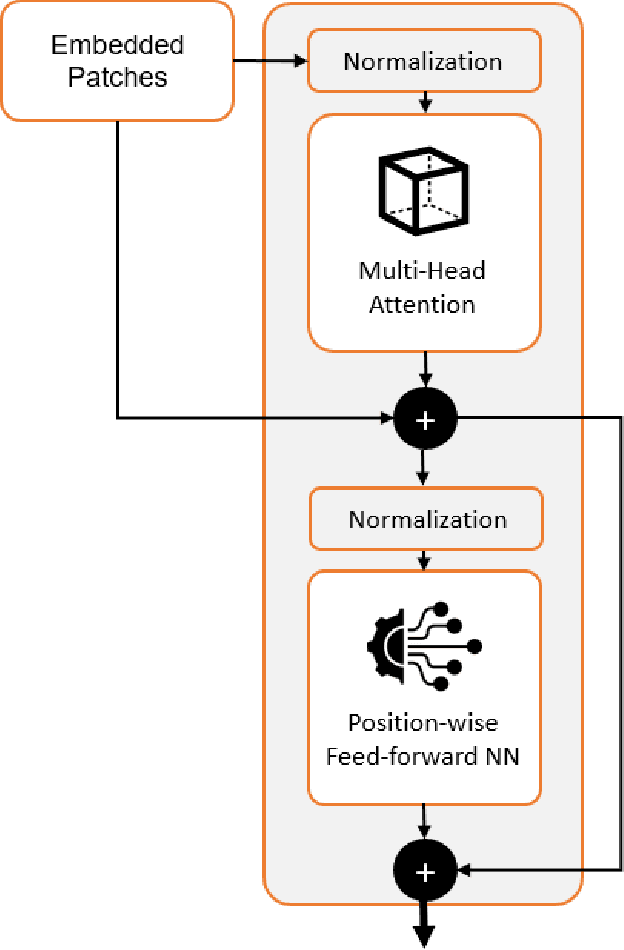
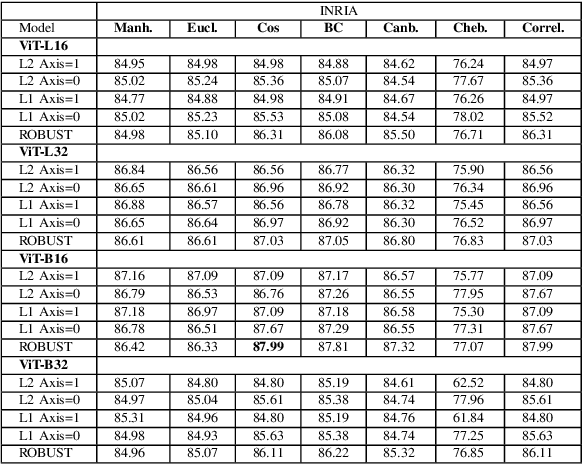
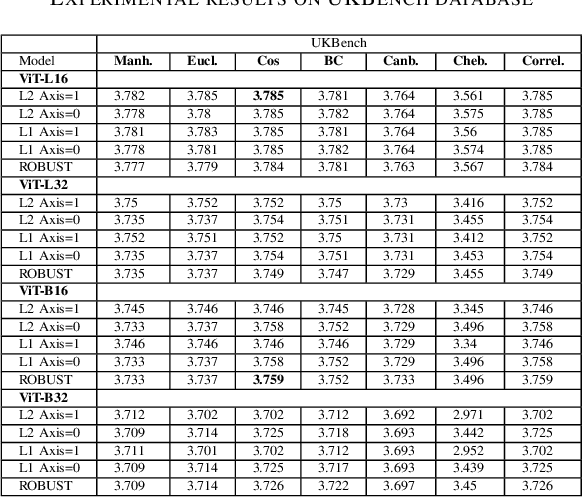
This paper introduces a plug-and-play descriptor that can be effectively adopted for image retrieval tasks without prior initialization or preparation. The description method utilizes the recently proposed Vision Transformer network while it does not require any training data to adjust parameters. In image retrieval tasks, the use of Handcrafted global and local descriptors has been very successfully replaced, over the last years, by the Convolutional Neural Networks (CNN)-based methods. However, the experimental evaluation conducted in this paper on several benchmarking datasets against 36 state-of-the-art descriptors from the literature demonstrates that a neural network that contains no convolutional layer, such as Vision Transformer, can shape a global descriptor and achieve competitive results. As fine-tuning is not required, the presented methodology's low complexity encourages adoption of the architecture as an image retrieval baseline model, replacing the traditional and well adopted CNN-based approaches and inaugurating a new era in image retrieval approaches.