 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarsExplorer: Exploration of Unknown Terrains via Deep Reinforcement Learning and Procedurally Generated Environments
Jul 21, 2021
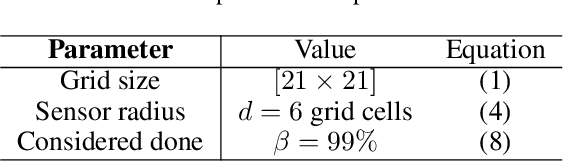
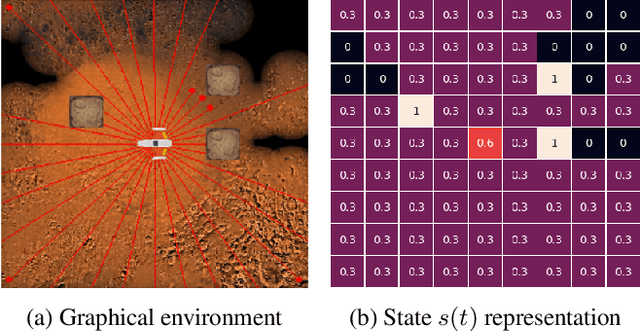
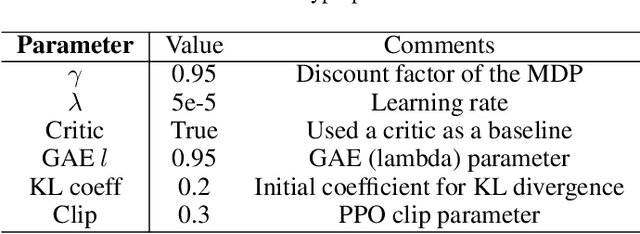
This paper is an initial endeavor to bridge the gap between powerful Deep Reinforcement Learning methodologies and the problem of exploration/coverage of unknown terrains. Within this scope, MarsExplorer, an openai-gym compatible environment tailored to exploration/coverage of unknown areas, is presented. MarsExplorer translates the original robotics problem into a Reinforcement Learning setup that various off-the-shelf algorithms can tackle. Any learned policy can be straightforwardly applied to a robotic platform without an elaborate simulation model of the robot's dynamics to apply a different learning/adaptation phase. One of its core features is the controllable multi-dimensional procedural generation of terrains, which is the key for producing policies with strong generalization capabilities. Four different state-of-the-art RL algorithms (A3C, PPO, Rainbow, and SAC) are trained on the MarsExplorer environment, and a proper evaluation of their results compared to the average human-level performance is reported. In the follow-up experimental analysis, the effect of the multi-dimensional difficulty setting on the learning capabilities of the best-performing algorithm (PPO) is analyzed. A milestone result is the generation of an exploration policy that follows the Hilbert curve without providing this information to the environment or rewarding directly or indirectly Hilbert-curve-like trajectories. The experimental analysis is concluded by comparing PPO learned policy results with frontier-based exploration context for extended terrain sizes. The source code can be found at: https://github.com/dimikout3/GeneralExplorationPolicy.
Autonomous and cooperative design of the monitor positions for a team of UAVs to maximize the quantity and quality of detected objects
Jul 02, 2020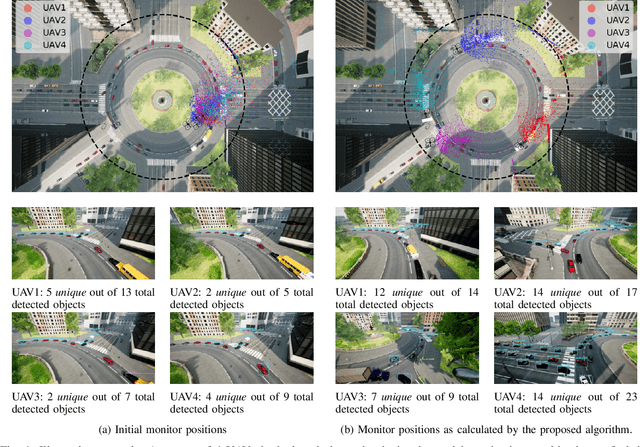



This paper tackles the problem of positioning a swarm of UAVs inside a completely unknown terrain, having as objective to maximize the overall situational awareness. The situational awareness is expressed by the number and quality of unique objects of interest, inside the UAVs' fields of view. YOLOv3 and a system to identify duplicate objects of interest were employed to assign a single score to each UAVs' configuration. Then, a novel navigation algorithm, capable of optimizing the previously defined score, without taking into consideration the dynamics of either UAVs or environment, is proposed. A cornerstone of the proposed approach is that it shares the same convergence characteristics as the block coordinate descent (BCD) family of approaches. The effectiveness and performance of the proposed navigation scheme were evaluated utilizing a series of experiments inside the AirSim simulator. The experimental evaluation indicates that the proposed navigation algorithm was able to consistently navigate the swarm of UAVs to "strategic" monitoring positions and also adapt to the different number of swarm sizes. Source code is available at https://github.com/dimikout3/ConvCAOAirSim.