 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Context in Transformers: An Analysis of Fragmentation and Tokenization
May 13, 2026Transformers predict over a representation of a sequence. The same data can be written as bytes, characters, or subword tokens, and these representations may be lossless. Yet, under a fixed context window, they need not expose the same information to the model. This raises a basic question: how does the choice of representation change what a finite-context predictor can achieve? We study this question on Markov sources and uncover two complementary phenomena. First, we observe that moving to smaller representation units can hurt prediction even when the context window is enlarged to cover the relevant source history. To explain this, we introduce fragmentation: a lossless recoding that replaces each source symbol by several smaller units. We prove that fragmentation can strictly increase the optimal finite-context log-loss, showing that the gap is not merely an optimization or capacity issue, but can be intrinsic to the representation. This gives a theoretical account of the finite-context gap observed in byte- and character-level models such as ByT5 and CANINE relative to subword-tokenized models. Second, we study the opposite direction: greedy tokenization -- BPE, WordPiece, and related methods -- which groups source symbols into larger units. We show that tokenization can make a short token window behave like a longer source-context window, and we give a loss guarantee describing when this is achievable. The guarantee depends on how reliably token windows span the needed source history, together with the compression rate of the tokenizer. This also yields a simple diagnostic for real tokenizers: measuring how much source context a fixed token window reliably contains. Together, the two directions establish a finite-context information-theoretic framework for reasoning about representation choices in Transformers.
Error-Correction for Sparse Support Recovery Algorithms
Mar 05, 2021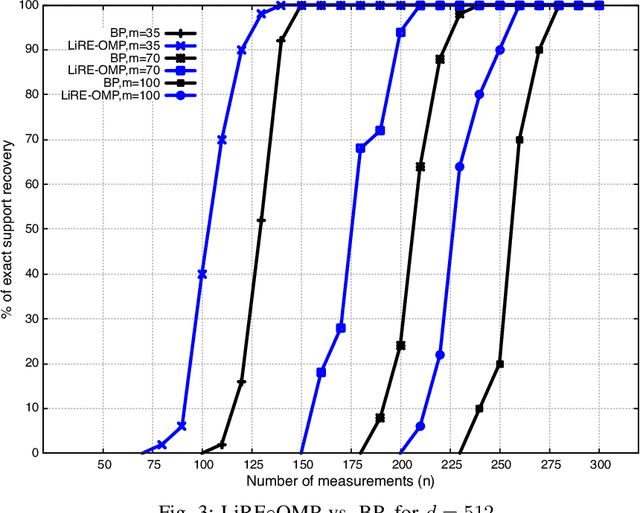
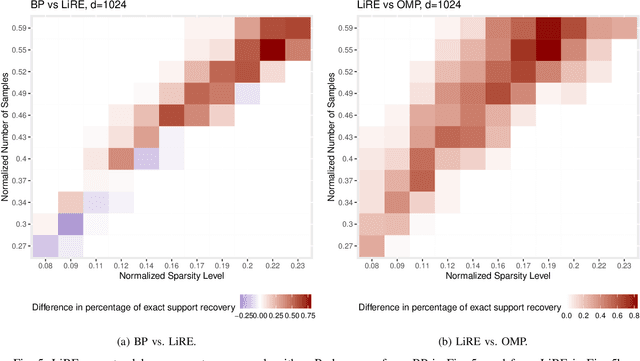
Consider the compressed sensing setup where the support $s^*$ of an $m$-sparse $d$-dimensional signal $x$ is to be recovered from $n$ linear measurements with a given algorithm. Suppose that the measurements are such that the algorithm does not guarantee perfect support recovery and that true features may be missed. Can they efficiently be retrieved? This paper addresses this question through a simple error-correction module referred to as LiRE. LiRE takes as input an estimate $s_{in}$ of the true support $s^*$, and outputs a refined support estimate $s_{out}$. In the noiseless measurement setup, sufficient conditions are established under which LiRE is guaranteed to recover the entire support, that is $s_{out}$ contains $s^*$. These conditions imply, for instance, that in the high-dimensional regime LiRE can correct a sublinear in $m$ number of errors made by Orthogonal Matching Pursuit (OMP). The computational complexity of LiRE is $O(mnd)$. Experimental results with random Gaussian design matrices show that LiRE substantially reduces the number of measurements needed for perfect support recovery via Compressive Sampling Matching Pursuit, Basis Pursuit (BP), and OMP. Interestingly, adding LiRE to OMP yields a support recovery procedure that is more accurate and significantly faster than BP. This observation carries over in the noisy measurement setup. Finally, as a standalone support recovery algorithm with a random initialization, experiments show that LiRE's reconstruction performance lies between OMP and BP. These results suggest that LiRE may be used generically, on top of any suboptimal baseline support recovery algorithm, to improve support recovery or to operate with a smaller number of measurements, at the cost of a relatively small computational overhead. Alternatively, LiRE may be used as a standalone support recovery algorithm that is competitive with respect to OMP.
Approximating Probability Distributions by ReLU Networks
Jan 25, 2021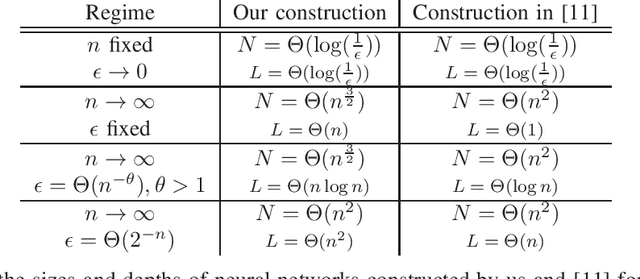
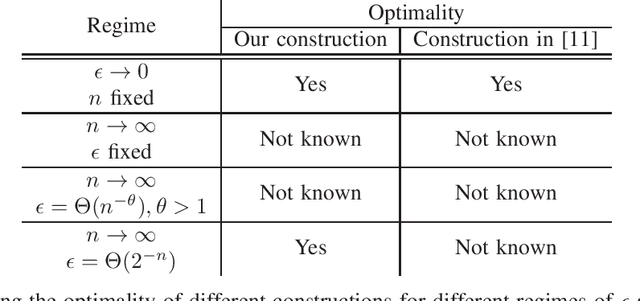
How many neurons are needed to approximate a target probability distribution using a neural network with a given input distribution and approximation error? This paper examines this question for the case when the input distribution is uniform, and the target distribution belongs to the class of histogram distributions. We obtain a new upper bound on the number of required neurons, which is strictly better than previously existing upper bounds. The key ingredient in this improvement is an efficient construction of the neural nets representing piecewise linear functions. We also obtain a lower bound on the minimum number of neurons needed to approximate the histogram distributions.
Bounds on the Approximation Power of Feedforward Neural Networks
Jun 29, 2018

The approximation power of general feedforward neural networks with piecewise linear activation functions is investigated. First, lower bounds on the size of a network are established in terms of the approximation error and network depth and width. These bounds improve upon state-of-the-art bounds for certain classes of functions, such as strongly convex functions. Second, an upper bound is established on the difference of two neural networks with identical weights but different activation functions.