 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Limited Community Recovery in Stochastic Block Models
Jun 01, 2026We study exact community recovery in the two-community stochastic block model on $n$ vertices under limited and noisy access to network data. The learner may query a noisy neighborhood oracle that reveals each true neighbor of a queried vertex independently with fixed probability and never returns non-neighbors, subject to a finite query budget. We consider both oracle-only access and a combined model where the learner also observes a single subsampled copy of the underlying graph. For oracle-only access, balanced uniform querying gives a sharp non-adaptive benchmark: when each vertex is queried the same integer number of times, the observations reduce to an SBM with attenuated edge probabilities and the Abbe-Bandeira-Hall exact-recovery threshold applies. We show that this benchmark is not adaptively optimal: a two-stage adaptive strategy succeeds with $n+o(n)$ queries in a regime where balanced uniform querying requires $m n$ queries for some $m>1$. With an additional subsampled graph, we prove a sublinear-query adaptivity gap: balanced data-independent uniform querying with a sublinear budget does not improve over the subsampled graph alone, whereas adaptive querying can target a small set of uncertain vertices and achieve exact recovery. Thus adaptive data acquisition can strictly improve the information-theoretic limits of exact recovery.
Generalization Bounds for Dependent Data using Online-to-Batch Conversion
May 22, 2024In this work, we give generalization bounds of statistical learning algorithms trained on samples drawn from a dependent data source, both in expectation and with high probability, using the Online-to-Batch conversion paradigm. We show that the generalization error of statistical learners in the dependent data setting is equivalent to the generalization error of statistical learners in the i.i.d. setting up to a term that depends on the decay rate of the underlying mixing stochastic process and is independent of the complexity of the statistical learner. Our proof techniques involve defining a new notion of stability of online learning algorithms based on Wasserstein distances and employing "near-martingale" concentration bounds for dependent random variables to arrive at appropriate upper bounds for the generalization error of statistical learners trained on dependent data.
Approximating Probability Distributions by ReLU Networks
Jan 25, 2021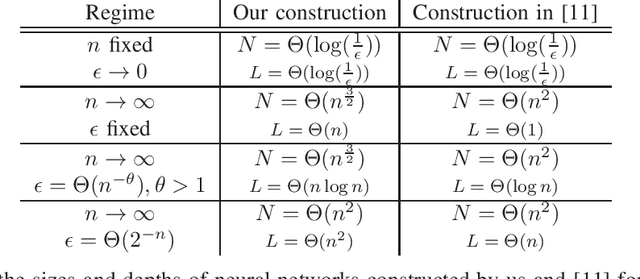
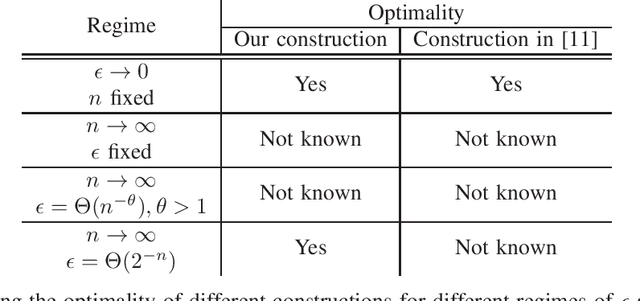
How many neurons are needed to approximate a target probability distribution using a neural network with a given input distribution and approximation error? This paper examines this question for the case when the input distribution is uniform, and the target distribution belongs to the class of histogram distributions. We obtain a new upper bound on the number of required neurons, which is strictly better than previously existing upper bounds. The key ingredient in this improvement is an efficient construction of the neural nets representing piecewise linear functions. We also obtain a lower bound on the minimum number of neurons needed to approximate the histogram distributions.