 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustifying State-space Models for Long Sequences via Approximate Diagonalization
Oct 02, 2023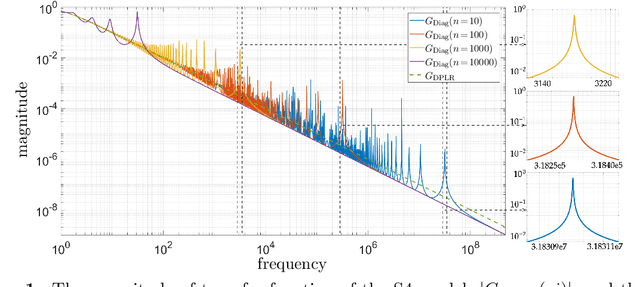
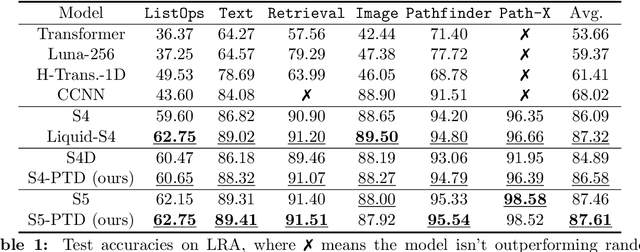
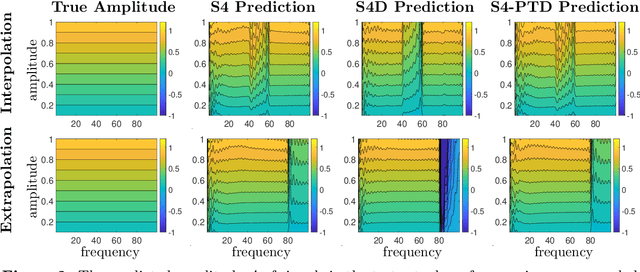
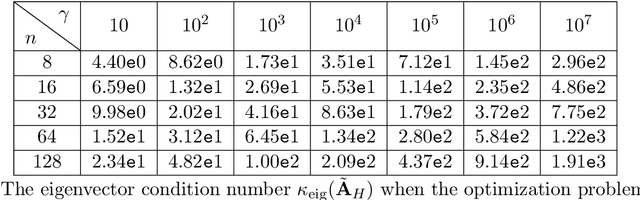
State-space models (SSMs) have recently emerged as a framework for learning long-range sequence tasks. An example is the structured state-space sequence (S4) layer, which uses the diagonal-plus-low-rank structure of the HiPPO initialization framework. However, the complicated structure of the S4 layer poses challenges; and, in an effort to address these challenges, models such as S4D and S5 have considered a purely diagonal structure. This choice simplifies the implementation, improves computational efficiency, and allows channel communication. However, diagonalizing the HiPPO framework is itself an ill-posed problem. In this paper, we propose a general solution for this and related ill-posed diagonalization problems in machine learning. We introduce a generic, backward-stable "perturb-then-diagonalize" (PTD) methodology, which is based on the pseudospectral theory of non-normal operators, and which may be interpreted as the approximate diagonalization of the non-normal matrices defining SSMs. Based on this, we introduce the S4-PTD and S5-PTD models. Through theoretical analysis of the transfer functions of different initialization schemes, we demonstrate that the S4-PTD/S5-PTD initialization strongly converges to the HiPPO framework, while the S4D/S5 initialization only achieves weak convergences. As a result, our new models show resilience to Fourier-mode noise-perturbed inputs, a crucial property not achieved by the S4D/S5 models. In addition to improved robustness, our S5-PTD model averages 87.6% accuracy on the Long-Range Arena benchmark, demonstrating that the PTD methodology helps to improve the accuracy of deep learning models.
Topological Regularization via Persistence-Sensitive Optimization
Nov 10, 2020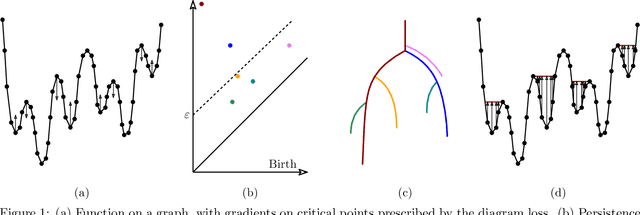


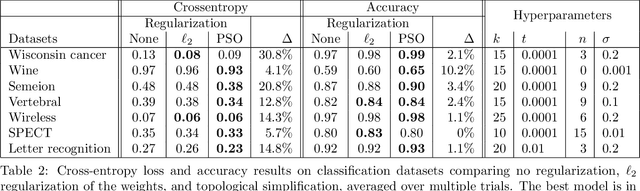
Optimization, a key tool in machine learning and statistics, relies on regularization to reduce overfitting. Traditional regularization methods control a norm of the solution to ensure its smoothness. Recently, topological methods have emerged as a way to provide a more precise and expressive control over the solution, relying on persistent homology to quantify and reduce its roughness. All such existing techniques back-propagate gradients through the persistence diagram, which is a summary of the topological features of a function. Their downside is that they provide information only at the critical points of the function. We propose a method that instead builds on persistence-sensitive simplification and translates the required changes to the persistence diagram into changes on large subsets of the domain, including both critical and regular points. This approach enables a faster and more precise topological regularization, the benefits of which we illustrate with experimental evidence.