 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Text in Challenging Stone Inscriptions: A Character-Context-Aware Patching Strategy for Binarization
Jan 07, 2026Binarization is a popular first step towards text extraction in historical artifacts. Stone inscription images pose severe challenges for binarization due to poor contrast between etched characters and the stone background, non-uniform surface degradation, distracting artifacts, and highly variable text density and layouts. These conditions frequently cause existing binarization techniques to fail and struggle to isolate coherent character regions. Many approaches sub-divide the image into patches to improve text fragment resolution and improve binarization performance. With this in mind, we present a robust and adaptive patching strategy to binarize challenging Indic inscriptions. The patches from our approach are used to train an Attention U-Net for binarization. The attention mechanism allows the model to focus on subtle structural cues, while our dynamic sampling and patch selection method ensures that the model learns to overcome surface noise and layout irregularities. We also introduce a carefully annotated, pixel-precise dataset of Indic stone inscriptions at the character-fragment level. We demonstrate that our novel patching mechanism significantly boosts binarization performance across classical and deep learning baselines. Despite training only on single script Indic dataset, our model exhibits strong zero-shot generalization to other Indic and non-indic scripts, highlighting its robustness and script-agnostic generalization capabilities. By producing clean, structured representations of inscription content, our method lays the foundation for downstream tasks such as script identification, OCR, and historical text analysis. Project page: https://ihdia.iiit.ac.in/shilalekhya-binarization/
Exploring zero-shot structure-based protein fitness prediction
Apr 23, 2025The ability to make zero-shot predictions about the fitness consequences of protein sequence changes with pre-trained machine learning models enables many practical applications. Such models can be applied for downstream tasks like genetic variant interpretation and protein engineering without additional labeled data. The advent of capable protein structure prediction tools has led to the availability of orders of magnitude more precomputed predicted structures, giving rise to powerful structure-based fitness prediction models. Through our experiments, we assess several modeling choices for structure-based models and their effects on downstream fitness prediction. Zero-shot fitness prediction models can struggle to assess the fitness landscape within disordered regions of proteins, those that lack a fixed 3D structure. We confirm the importance of matching protein structures to fitness assays and find that predicted structures for disordered regions can be misleading and affect predictive performance. Lastly, we evaluate an additional structure-based model on the ProteinGym substitution benchmark and show that simple multi-modal ensembles are strong baselines.
* 26 pages, 7 figures
CoTCoNet: An Optimized Coupled Transformer-Convolutional Network with an Adaptive Graph Reconstruction for Leukemia Detection
Oct 11, 2024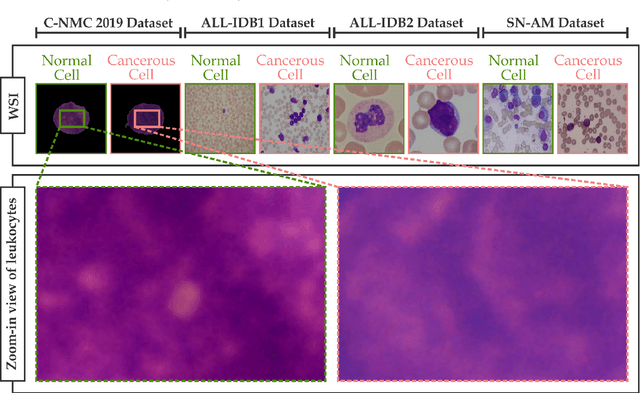
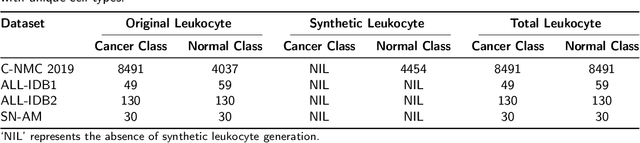
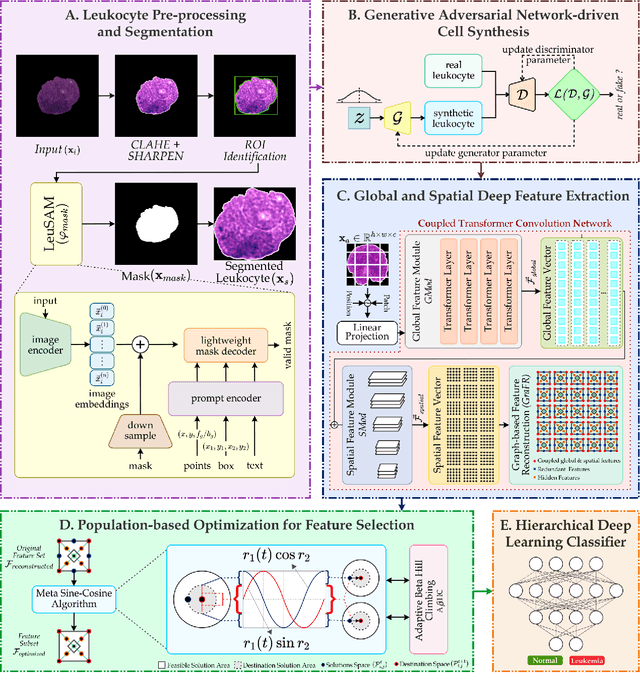

Swift and accurate blood smear analysis is an effective diagnostic method for leukemia and other hematological malignancies. However, manual leukocyte count and morphological evaluation using a microscope is time-consuming and prone to errors. Conventional image processing methods also exhibit limitations in differentiating cells due to the visual similarity between malignant and benign cell morphology. This limitation is further compounded by the skewed training data that hinders the extraction of reliable and pertinent features. In response to these challenges, we propose an optimized Coupled Transformer Convolutional Network (CoTCoNet) framework for the classification of leukemia, which employs a well-designed transformer integrated with a deep convolutional network to effectively capture comprehensive global features and scalable spatial patterns, enabling the identification of complex and large-scale hematological features. Further, the framework incorporates a graph-based feature reconstruction module to reveal the hidden or unobserved hard-to-see biological features of leukocyte cells and employs a Population-based Meta-Heuristic Algorithm for feature selection and optimization. To mitigate data imbalance issues, we employ a synthetic leukocyte generator. In the evaluation phase, we initially assess CoTCoNet on a dataset containing 16,982 annotated cells, and it achieves remarkable accuracy and F1-Score rates of 0.9894 and 0.9893, respectively. To broaden the generalizability of our model, we evaluate it across four publicly available diverse datasets, which include the aforementioned dataset. This evaluation demonstrates that our method outperforms current state-of-the-art approaches. We also incorporate an explainability approach in the form of feature visualization closely aligned with cell annotations to provide a deeper understanding of the framework.
Shallow Parsing Pipeline for Hindi-English Code-Mixed Social Media Text
Apr 11, 2016
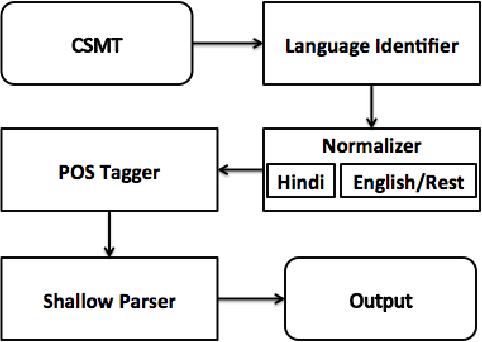
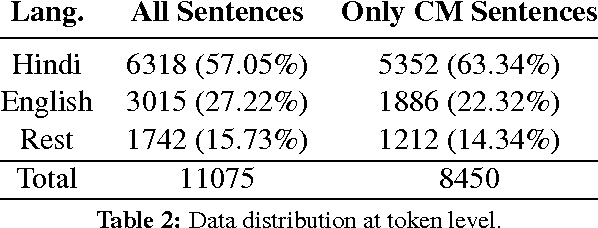
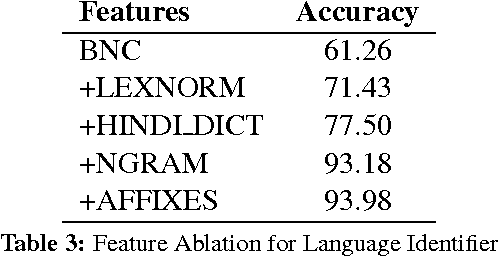
In this study, the problem of shallow parsing of Hindi-English code-mixed social media text (CSMT) has been addressed. We have annotated the data, developed a language identifier, a normalizer, a part-of-speech tagger and a shallow parser. To the best of our knowledge, we are the first to attempt shallow parsing on CSMT. The pipeline developed has been made available to the research community with the goal of enabling better text analysis of Hindi English CSMT. The pipeline is accessible at http://bit.ly/csmt-parser-api .