Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Parsing Pipeline for Hindi-English Code-Mixed Social Media Text
Apr 11, 2016
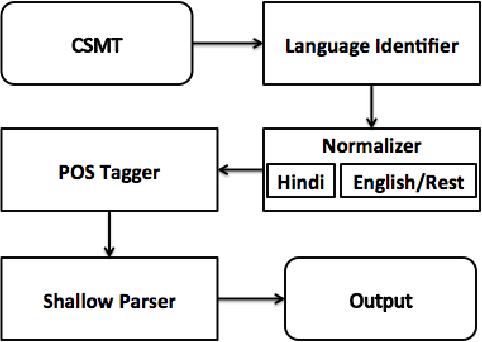
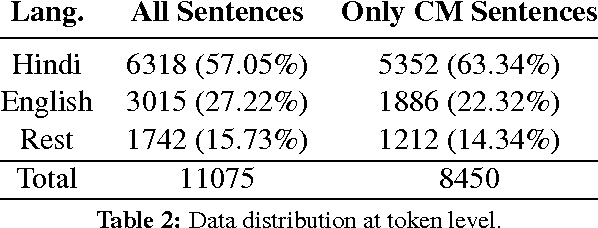
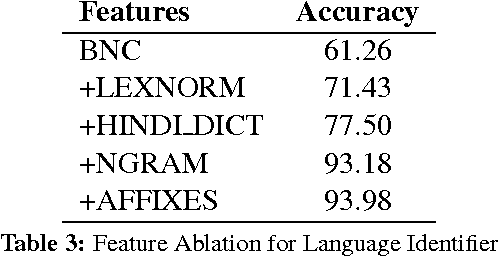
In this study, the problem of shallow parsing of Hindi-English code-mixed social media text (CSMT) has been addressed. We have annotated the data, developed a language identifier, a normalizer, a part-of-speech tagger and a shallow parser. To the best of our knowledge, we are the first to attempt shallow parsing on CSMT. The pipeline developed has been made available to the research community with the goal of enabling better text analysis of Hindi English CSMT. The pipeline is accessible at http://bit.ly/csmt-parser-api .
Via