 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Impact of Environmental Pollutants on Multiple Sclerosis Progression
Aug 30, 2024


Multiple Sclerosis (MS) is a chronic autoimmune and inflammatory neurological disorder characterised by episodes of symptom exacerbation, known as relapses. In this study, we investigate the role of environmental factors in relapse occurrence among MS patients, using data from the H2020 BRAINTEASER project. We employed predictive models, including Random Forest (RF) and Logistic Regression (LR), with varying sets of input features to predict the occurrence of relapses based on clinical and pollutant data collected over a week. The RF yielded the best result, with an AUC-ROC score of 0.713. Environmental variables, such as precipitation, NO2, PM2.5, humidity, and temperature, were found to be relevant to the prediction.
Evaluation of Predictive Reliability to Foster Trust in Artificial Intelligence. A case study in Multiple Sclerosis
Feb 27, 2024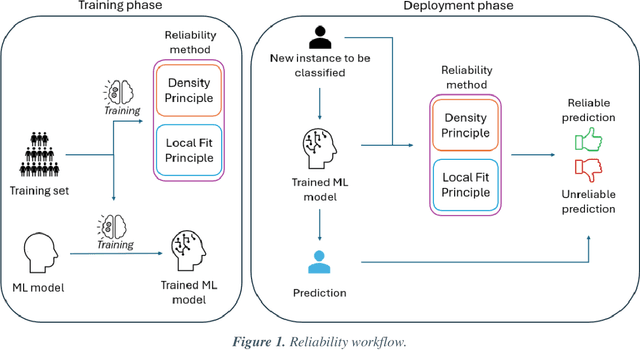

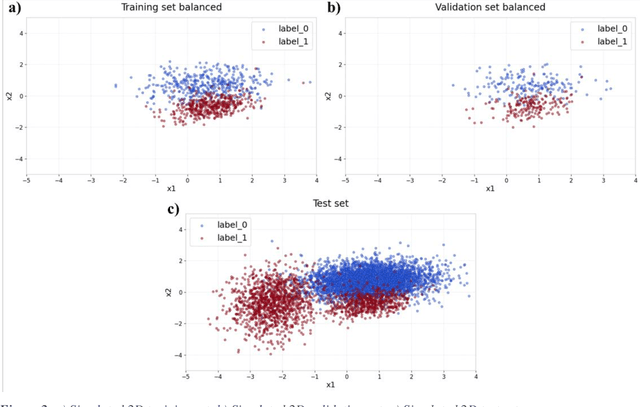
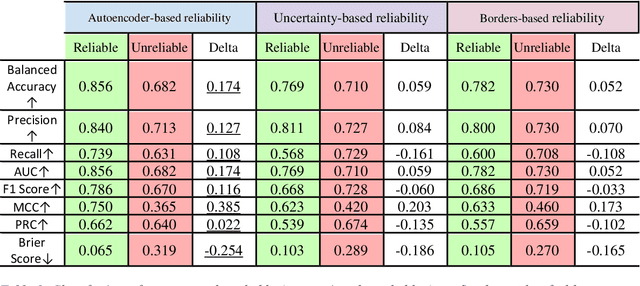
Applying Artificial Intelligence (AI) and Machine Learning (ML) in critical contexts, such as medicine, requires the implementation of safety measures to reduce risks of harm in case of prediction errors. Spotting ML failures is of paramount importance when ML predictions are used to drive clinical decisions. ML predictive reliability measures the degree of trust of a ML prediction on a new instance, thus allowing decision-makers to accept or reject it based on its reliability. To assess reliability, we propose a method that implements two principles. First, our approach evaluates whether an instance to be classified is coming from the same distribution of the training set. To do this, we leverage Autoencoders (AEs) ability to reconstruct the training set with low error. An instance is considered Out-of-Distribution (OOD) if the AE reconstructs it with a high error. Second, it is evaluated whether the ML classifier has good performances on samples similar to the newly classified instance by using a proxy model. We show that this approach is able to assess reliability both in a simulated scenario and on a model trained to predict disease progression of Multiple Sclerosis patients. We also developed a Python package, named relAI, to embed reliability measures into ML pipelines. We propose a simple approach that can be used in the deployment phase of any ML model to suggest whether to trust predictions or not. Our method holds the promise to provide effective support to clinicians by spotting potential ML failures during deployment.
CAD-RADS scoring of coronary CT angiography with Multi-Axis Vision Transformer: a clinically-inspired deep learning pipeline
Apr 14, 2023The standard non-invasive imaging technique used to assess the severity and extent of Coronary Artery Disease (CAD) is Coronary Computed Tomography Angiography (CCTA). However, manual grading of each patient's CCTA according to the CAD-Reporting and Data System (CAD-RADS) scoring is time-consuming and operator-dependent, especially in borderline cases. This work proposes a fully automated, and visually explainable, deep learning pipeline to be used as a decision support system for the CAD screening procedure. The pipeline performs two classification tasks: firstly, identifying patients who require further clinical investigations and secondly, classifying patients into subgroups based on the degree of stenosis, according to commonly used CAD-RADS thresholds. The pipeline pre-processes multiplanar projections of the coronary arteries, extracted from the original CCTAs, and classifies them using a fine-tuned Multi-Axis Vision Transformer architecture. With the aim of emulating the current clinical practice, the model is trained to assign a per-patient score by stacking the bi-dimensional longitudinal cross-sections of the three main coronary arteries along channel dimension. Furthermore, it generates visually interpretable maps to assess the reliability of the predictions. When run on a database of 1873 three-channel images of 253 patients collected at the Monzino Cardiology Center in Milan, the pipeline obtained an AUC of 0.87 and 0.93 for the two classification tasks, respectively. According to our knowledge, this is the first model trained to assign CAD-RADS scores learning solely from patient scores and not requiring finer imaging annotation steps that are not part of the clinical routine.