 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Predictive Reliability to Foster Trust in Artificial Intelligence. A case study in Multiple Sclerosis
Feb 27, 2024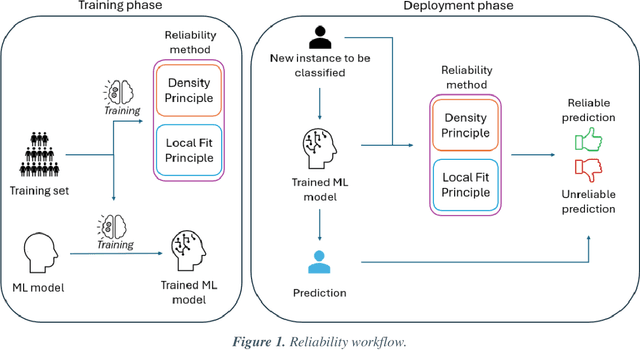

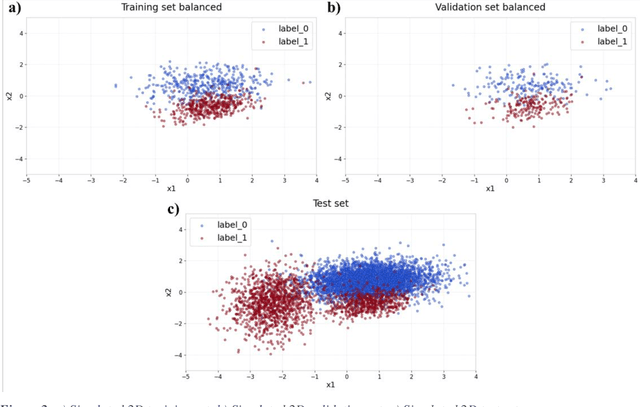
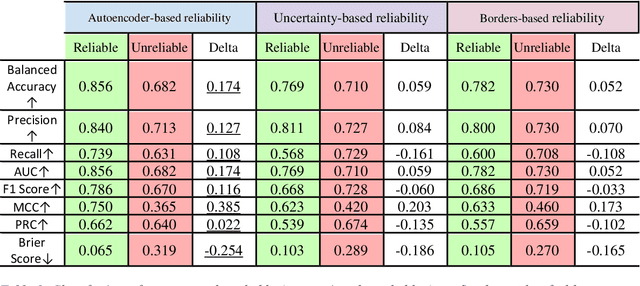
Applying Artificial Intelligence (AI) and Machine Learning (ML) in critical contexts, such as medicine, requires the implementation of safety measures to reduce risks of harm in case of prediction errors. Spotting ML failures is of paramount importance when ML predictions are used to drive clinical decisions. ML predictive reliability measures the degree of trust of a ML prediction on a new instance, thus allowing decision-makers to accept or reject it based on its reliability. To assess reliability, we propose a method that implements two principles. First, our approach evaluates whether an instance to be classified is coming from the same distribution of the training set. To do this, we leverage Autoencoders (AEs) ability to reconstruct the training set with low error. An instance is considered Out-of-Distribution (OOD) if the AE reconstructs it with a high error. Second, it is evaluated whether the ML classifier has good performances on samples similar to the newly classified instance by using a proxy model. We show that this approach is able to assess reliability both in a simulated scenario and on a model trained to predict disease progression of Multiple Sclerosis patients. We also developed a Python package, named relAI, to embed reliability measures into ML pipelines. We propose a simple approach that can be used in the deployment phase of any ML model to suggest whether to trust predictions or not. Our method holds the promise to provide effective support to clinicians by spotting potential ML failures during deployment.