 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast hyperboloid decision tree algorithms
Oct 20, 2023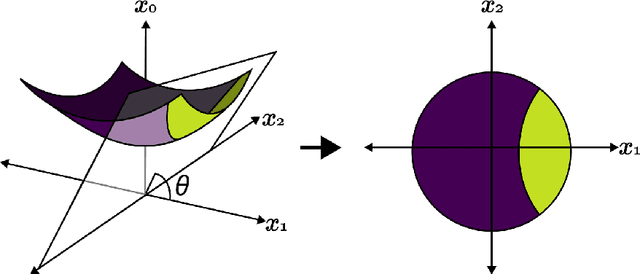
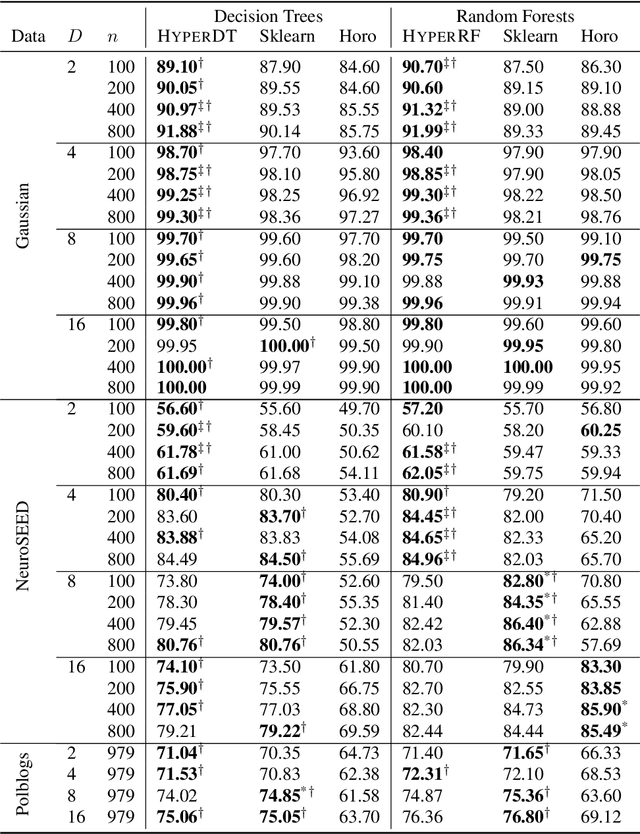
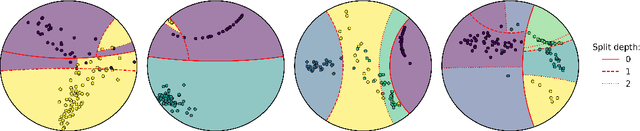
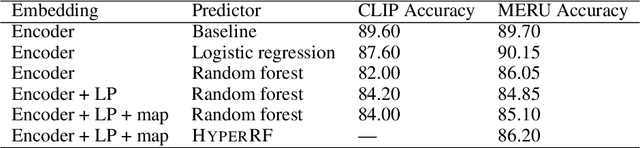
Hyperbolic geometry is gaining traction in machine learning for its effectiveness at capturing hierarchical structures in real-world data. Hyperbolic spaces, where neighborhoods grow exponentially, offer substantial advantages and consistently deliver state-of-the-art results across diverse applications. However, hyperbolic classifiers often grapple with computational challenges. Methods reliant on Riemannian optimization frequently exhibit sluggishness, stemming from the increased computational demands of operations on Riemannian manifolds. In response to these challenges, we present hyperDT, a novel extension of decision tree algorithms into hyperbolic space. Crucially, hyperDT eliminates the need for computationally intensive Riemannian optimization, numerically unstable exponential and logarithmic maps, or pairwise comparisons between points by leveraging inner products to adapt Euclidean decision tree algorithms to hyperbolic space. Our approach is conceptually straightforward and maintains constant-time decision complexity while mitigating the scalability issues inherent in high-dimensional Euclidean spaces. Building upon hyperDT we introduce hyperRF, a hyperbolic random forest model. Extensive benchmarking across diverse datasets underscores the superior performance of these models, providing a swift, precise, accurate, and user-friendly toolkit for hyperbolic data analysis.
Accurate Protein Structure Prediction by Embeddings and Deep Learning Representations
Nov 09, 2019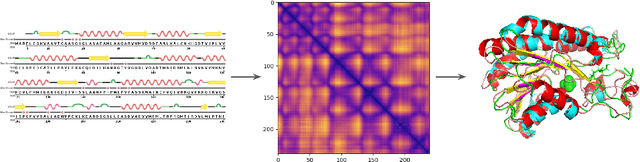


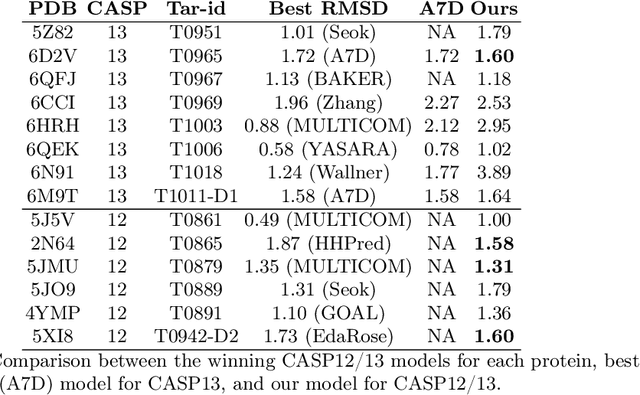
Proteins are the major building blocks of life, and actuators of almost all chemical and biophysical events in living organisms. Their native structures in turn enable their biological functions which have a fundamental role in drug design. This motivates predicting the structure of a protein from its sequence of amino acids, a fundamental problem in computational biology. In this work, we demonstrate state-of-the-art protein structure prediction (PSP) results using embeddings and deep learning models for prediction of backbone atom distance matrices and torsion angles. We recover 3D coordinates of backbone atoms and reconstruct full atom protein by optimization. We create a new gold standard dataset of proteins which is comprehensive and easy to use. Our dataset consists of amino acid sequences, Q8 secondary structures, position specific scoring matrices, multiple sequence alignment co-evolutionary features, backbone atom distance matrices, torsion angles, and 3D coordinates. We evaluate the quality of our structure prediction by RMSD on the latest Critical Assessment of Techniques for Protein Structure Prediction (CASP) test data and demonstrate competitive results with the winning teams and AlphaFold in CASP13 and supersede the results of the winning teams in CASP12. We make our data, models, and code publicly available.