 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Direct Control Policies with Flow Matching for Autonomous Driving
May 14, 2026We present a flow-matching planner for autonomous driving that directly outputs actionable control trajectories defined by acceleration and curvature profiles. The model is conditioned on a bird's-eye-view (BEV) raster of the surrounding scene and generates control sequences in a small number of Ordinary Differential Equations (ODE) integration steps, enabling low-latency inference suitable for real-time closed-loop re-planning. We train exclusively on urban scenarios (real urban city streets, intersections and roundabouts of the city of Parma, Italy) collected from a 2D traffic simulator with reactive agents, and evaluate in closed-loop on both in-distribution and markedly out-of-distribution environments, including multi-lane highways and unseen urban scenarios. Our results show that the model generalizes reliably to these unseen conditions, maintaining stable closed-loop control and successfully completing scenarios that differ substantially from the training distribution. We attribute this to the BEV representation, which provides a geometry-centric view of the scene that is inherently less sensitive to distributional shifts, and to the flow-matching formulation, which learns a smooth vector field that degrades gracefully under distribution shift. We provide video demonstrations of closed-loop behavior at https://marcelloceresini.github.io/DirectControlFlowMatching.
Informative Rays Selection for Few-Shot Neural Radiance Fields
Dec 29, 2023



Neural Radiance Fields (NeRF) have recently emerged as a powerful method for image-based 3D reconstruction, but the lengthy per-scene optimization limits their practical usage, especially in resource-constrained settings. Existing approaches solve this issue by reducing the number of input views and regularizing the learned volumetric representation with either complex losses or additional inputs from other modalities. In this paper, we present KeyNeRF, a simple yet effective method for training NeRF in few-shot scenarios by focusing on key informative rays. Such rays are first selected at camera level by a view selection algorithm that promotes baseline diversity while guaranteeing scene coverage, then at pixel level by sampling from a probability distribution based on local image entropy. Our approach performs favorably against state-of-the-art methods, while requiring minimal changes to existing NeRF codebases.
Arbitrary Point Cloud Upsampling with Spherical Mixture of Gaussians
Aug 10, 2022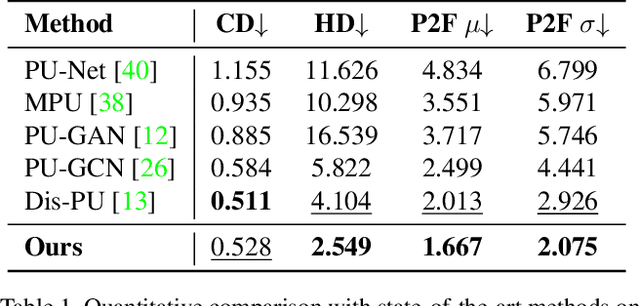

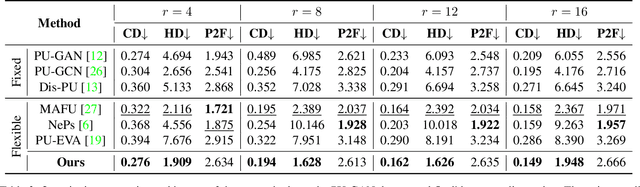

Generating dense point clouds from sparse raw data benefits downstream 3D understanding tasks, but existing models are limited to a fixed upsampling ratio or to a short range of integer values. In this paper, we present APU-SMOG, a Transformer-based model for Arbitrary Point cloud Upsampling (APU). The sparse input is firstly mapped to a Spherical Mixture of Gaussians (SMOG) distribution, from which an arbitrary number of points can be sampled. Then, these samples are fed as queries to the Transformer decoder, which maps them back to the target surface. Extensive qualitative and quantitative evaluations show that APU-SMOG outperforms state-of-the-art fixed-ratio methods, while effectively enabling upsampling with any scaling factor, including non-integer values, with a single trained model. The code will be made available.
Leveraging Local Domains for Image-to-Image Translation
Sep 09, 2021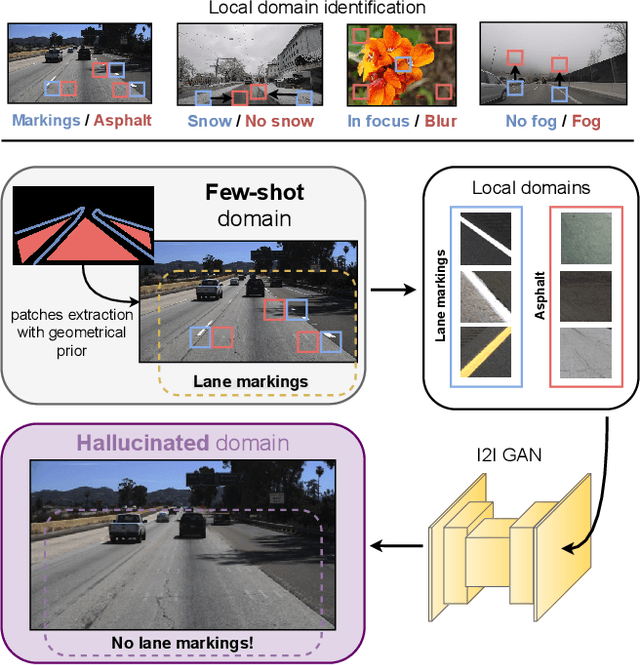

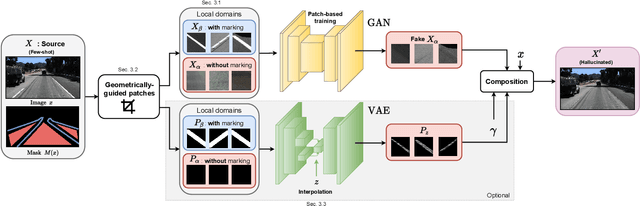
Image-to-image (i2i) networks struggle to capture local changes because they do not affect the global scene structure. For example, translating from highway scenes to offroad, i2i networks easily focus on global color features but ignore obvious traits for humans like the absence of lane markings. In this paper, we leverage human knowledge about spatial domain characteristics which we refer to as 'local domains' and demonstrate its benefit for image-to-image translation. Relying on a simple geometrical guidance, we train a patch-based GAN on few source data and hallucinate a new unseen domain which subsequently eases transfer learning to target. We experiment on three tasks ranging from unstructured environments to adverse weather. Our comprehensive evaluation setting shows we are able to generate realistic translations, with minimal priors, and training only on a few images. Furthermore, when trained on our translations images we show that all tested proxy tasks are significantly improved, without ever seeing target domain at training.
End-to-End Intersection Handling using Multi-Agent Deep Reinforcement Learning
May 01, 2021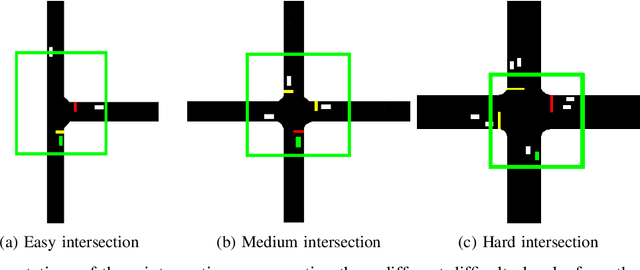
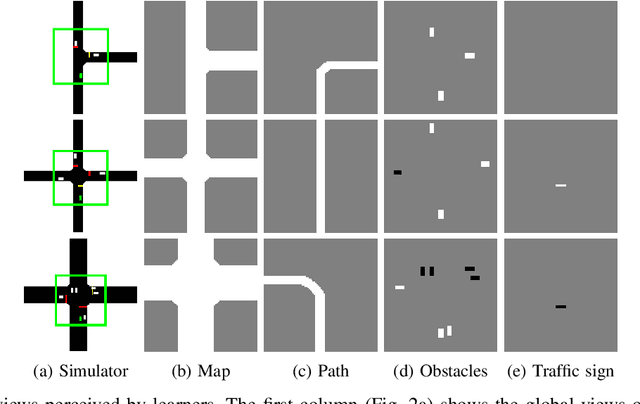

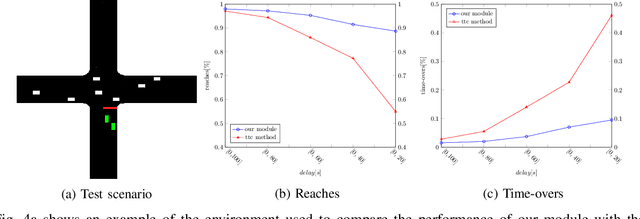
Navigating through intersections is one of the main challenging tasks for an autonomous vehicle. However, for the majority of intersections regulated by traffic lights, the problem could be solved by a simple rule-based method in which the autonomous vehicle behavior is closely related to the traffic light states. In this work, we focus on the implementation of a system able to navigate through intersections where only traffic signs are provided. We propose a multi-agent system using a continuous, model-free Deep Reinforcement Learning algorithm used to train a neural network for predicting both the acceleration and the steering angle at each time step. We demonstrate that agents learn both the basic rules needed to handle intersections by understanding the priorities of other learners inside the environment, and to drive safely along their paths. Moreover, a comparison between our system and a rule-based method proves that our model achieves better results especially with dense traffic conditions. Finally, we test our system on real world scenarios using real recorded traffic data, proving that our module is able to generalize both to unseen environments and to different traffic conditions.