 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Local Domains for Image-to-Image Translation
Paper and Code
Sep 09, 2021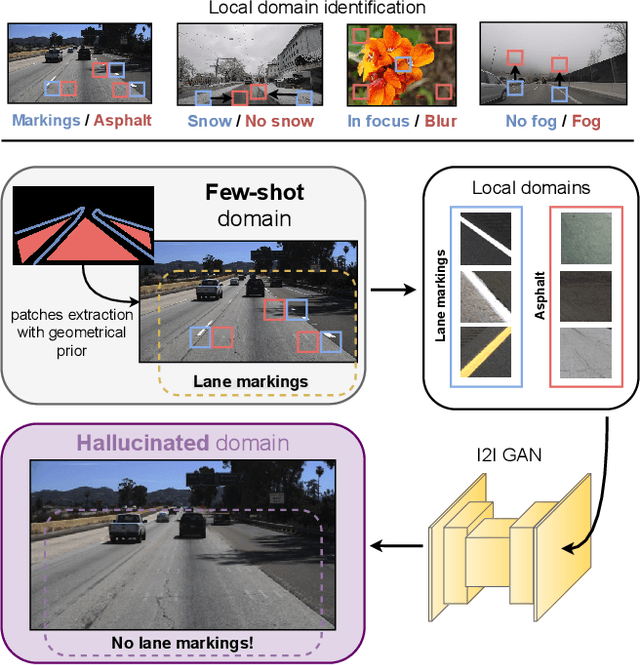

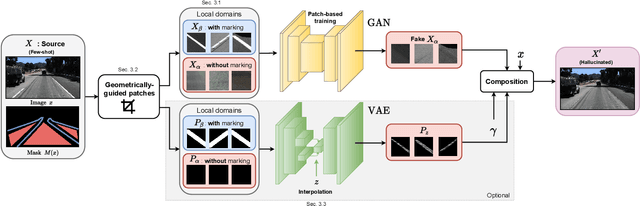
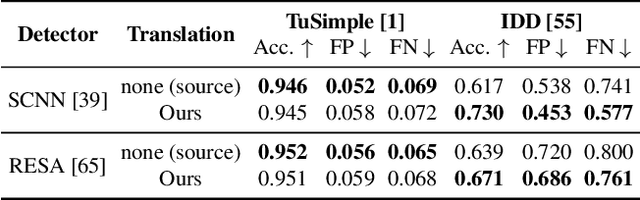
Image-to-image (i2i) networks struggle to capture local changes because they do not affect the global scene structure. For example, translating from highway scenes to offroad, i2i networks easily focus on global color features but ignore obvious traits for humans like the absence of lane markings. In this paper, we leverage human knowledge about spatial domain characteristics which we refer to as 'local domains' and demonstrate its benefit for image-to-image translation. Relying on a simple geometrical guidance, we train a patch-based GAN on few source data and hallucinate a new unseen domain which subsequently eases transfer learning to target. We experiment on three tasks ranging from unstructured environments to adverse weather. Our comprehensive evaluation setting shows we are able to generate realistic translations, with minimal priors, and training only on a few images. Furthermore, when trained on our translations images we show that all tested proxy tasks are significantly improved, without ever seeing target domain at training.