 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework for inferring empirical causal graphs from binary data to support multidimensional poverty analysis
May 12, 2022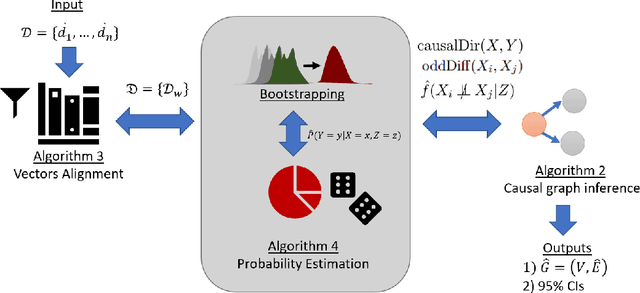

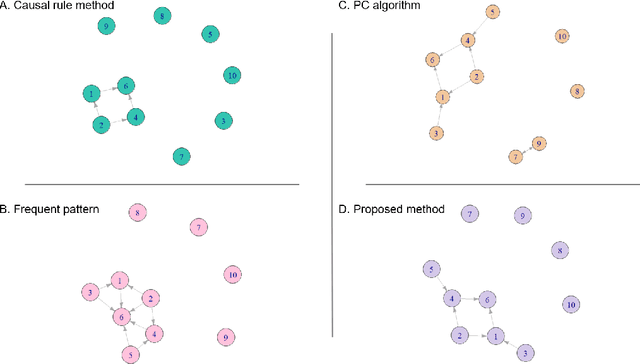

Poverty is one of the fundamental issues that mankind faces. Multidimensional Poverty Index (MPI) is deployed for measuring poverty issues in a population beyond monetary. However, MPI cannot provide information regarding associations and causal relations among poverty factors. Does education cause income inequality in a specific region? Is lacking education a cause of health issues? By not knowing causal relations, policy maker cannot pinpoint root causes of poverty issues of a specific population, which might not be the same across different population. Additionally, MPI requires binary data, which cannot be analyzed by most of causal inference frameworks. In this work, we proposed an exploratory-data-analysis framework for finding possible causal relations with confidence intervals among binary data. The proposed framework provides not only how severe the issue of poverty is, but it also provides the causal relations among poverty factors. Moreover, knowing a confidence interval of degree of causal direction lets us know how strong a causal relation is. We evaluated the proposed framework with several baseline approaches in simulation datasets as well as using two real-world datasets as case studies 1) Twin births of the United States: the relation between birth weight and mortality of twin, and 2) Thailand population surveys from 378k households of Chiang Mai and 353k households of Khon Kaen provinces. Our framework performed better than baselines in most cases. The first case study reveals almost all mortality cases in twins have issues of low birth weights but not all low-birth-weight twins were died. The second case study reveals that smoking associates with drinking alcohol in both provinces and there is a causal relation of smoking causes drinking alcohol in only Chiang Mai province. The framework can be applied beyond the poverty context.
A nonparametric framework for inferring orders of categorical data from category-real ordered pairs
Nov 15, 2019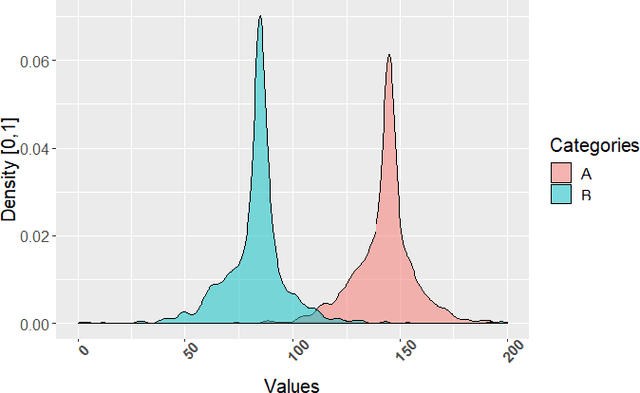
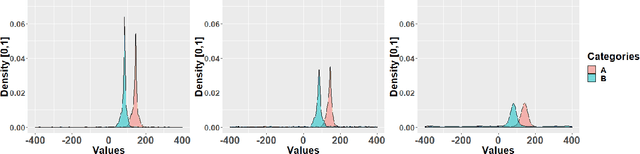
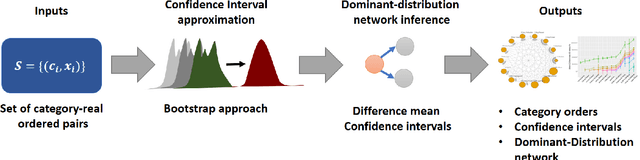
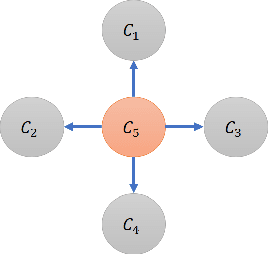
Given a dataset of careers and incomes, how large a difference of income between any pair of careers would be? Given a dataset of travel time records, how long do we need to spend more when choosing a public transportation mode $A$ instead of $B$ to travel? In this paper, we propose a framework that is able to infer orders of categories as well as magnitudes of difference of real numbers between each pair of categories using Estimation statistics framework. Not only reporting whether an order of categories exists, but our framework also reports the magnitude of difference of each consecutive pairs of categories in the order. In large dataset, our framework is scalable well compared with the existing framework. The proposed framework has been applied to two real-world case studies: 1) ordering careers by incomes based on information of 350,000 households living in Khon Kaen province, Thailand, and 2) ordering sectors by closing prices based on 1060 companies' closing prices of NASDAQ stock markets between years 2000 and 2016. The results of careers ordering show income inequality among different careers. The stock market results illustrate dynamics of sector domination that can change over time. Our approach is able to be applied in any research area that has category-real ordered pairs. Our proposed "Dominant-Distribution Network" provides a novel approach to gain new insight of analyzing category orders. The software of this framework is available for researchers or practitioners within R package: EDOIF.
Identifying Linear Models in Multi-Resolution Population Data using Minimum Description Length Principle to Predict Household Income
Jul 10, 2019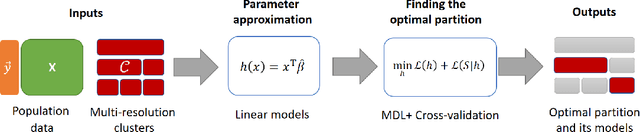
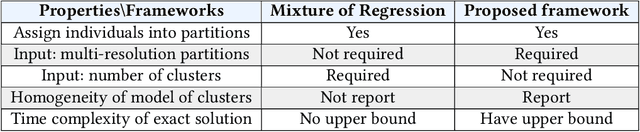
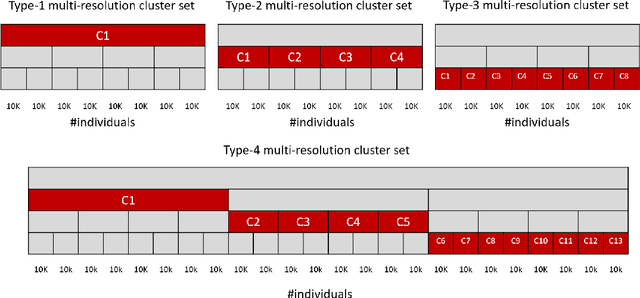

One shirt size cannot fit everybody, while we cannot make a unique shirt that fits perfectly for everyone because of resource limitation. This analogy is true for the policy making. Policy makers cannot establish a single policy to solve all problems for all regions because each region has its own unique issue. In the other extreme, policy makers also cannot create a policy for each small village due to the resource limitation. Would it be better if we can find a set of largest regions such that the population of each region within this set has common issues and we can establish a single policy for them? In this work, we propose a framework using regression analysis and minimum description length (MDL) to find a set of largest areas that have common indicators, which can be used to predict household incomes efficiently. Given a set of household features, and a multi-resolution partition that represents administrative divisions, our framework reports a set C* of largest subdivisions that have a common model for population-income prediction. We formalize a problem of finding C* and propose the algorithm as a solution. We use both simulation datasets as well as a real-world dataset of Thailand's population household information to demonstrate our framework performance and application. The results show that our framework performance is better than the baseline methods. We show the results of our method can be used to find indicators of income prediction for many areas in Thailand. By increasing these indicator values, we expect people in these areas to gain more incomes. Hence, the policy makers can plan to establish the policies by using these indicators in our results as a guideline to solve low-income issues. Our framework can be used to support policy makers to establish policies regarding any other dependent variable beyond incomes in order to combat poverty and other issues.
A Probabilistic Approach for Learning Folksonomies from Structured Data
Nov 16, 2010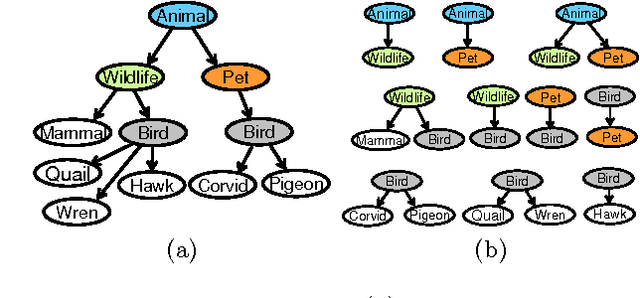
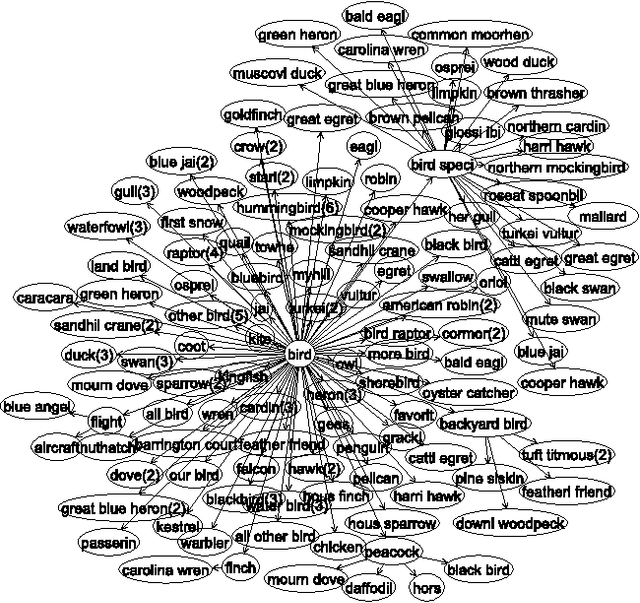
Learning structured representations has emerged as an important problem in many domains, including document and Web data mining, bioinformatics, and image analysis. One approach to learning complex structures is to integrate many smaller, incomplete and noisy structure fragments. In this work, we present an unsupervised probabilistic approach that extends affinity propagation to combine the small ontological fragments into a collection of integrated, consistent, and larger folksonomies. This is a challenging task because the method must aggregate similar structures while avoiding structural inconsistencies and handling noise. We validate the approach on a real-world social media dataset, comprised of shallow personal hierarchies specified by many individual users, collected from the photosharing website Flickr. Our empirical results show that our proposed approach is able to construct deeper and denser structures, compared to an approach using only the standard affinity propagation algorithm. Additionally, the approach yields better overall integration quality than a state-of-the-art approach based on incremental relational clustering.
Growing a Tree in the Forest: Constructing Folksonomies by Integrating Structured Metadata
May 27, 2010

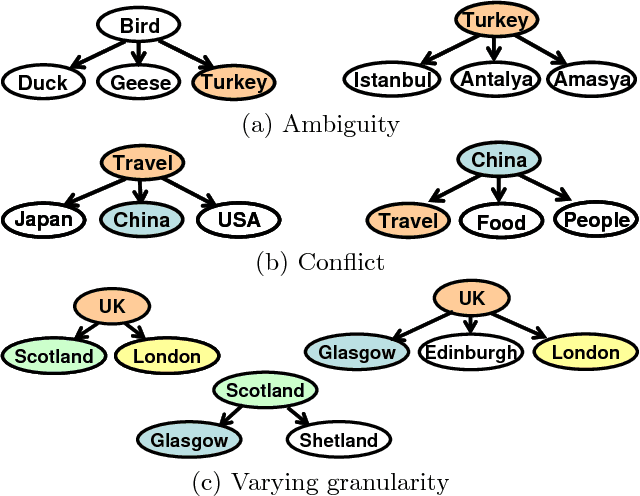
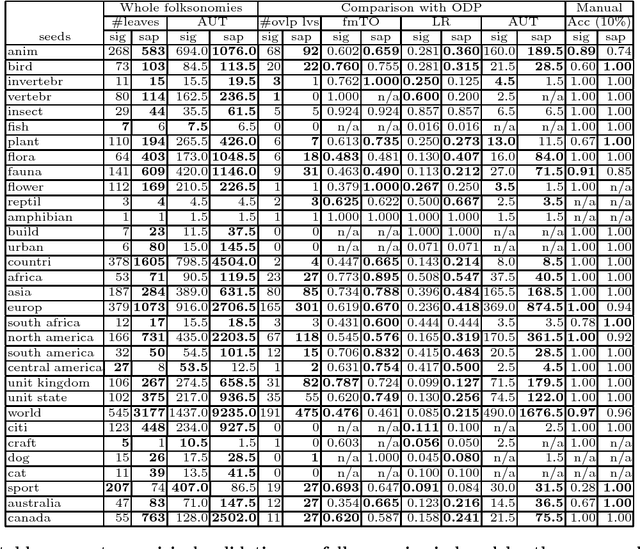
Many social Web sites allow users to annotate the content with descriptive metadata, such as tags, and more recently to organize content hierarchically. These types of structured metadata provide valuable evidence for learning how a community organizes knowledge. For instance, we can aggregate many personal hierarchies into a common taxonomy, also known as a folksonomy, that will aid users in visualizing and browsing social content, and also to help them in organizing their own content. However, learning from social metadata presents several challenges, since it is sparse, shallow, ambiguous, noisy, and inconsistent. We describe an approach to folksonomy learning based on relational clustering, which exploits structured metadata contained in personal hierarchies. Our approach clusters similar hierarchies using their structure and tag statistics, then incrementally weaves them into a deeper, bushier tree. We study folksonomy learning using social metadata extracted from the photo-sharing site Flickr, and demonstrate that the proposed approach addresses the challenges. Moreover, comparing to previous work, the approach produces larger, more accurate folksonomies, and in addition, scales better.
Integrating Structured Metadata with Relational Affinity Propagation
May 26, 2010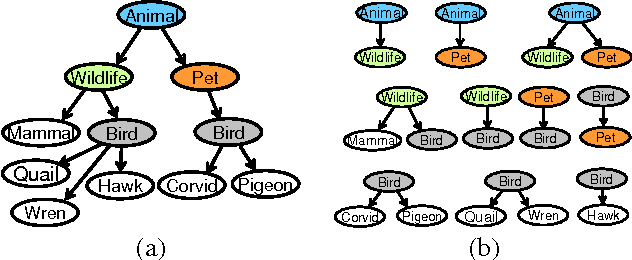
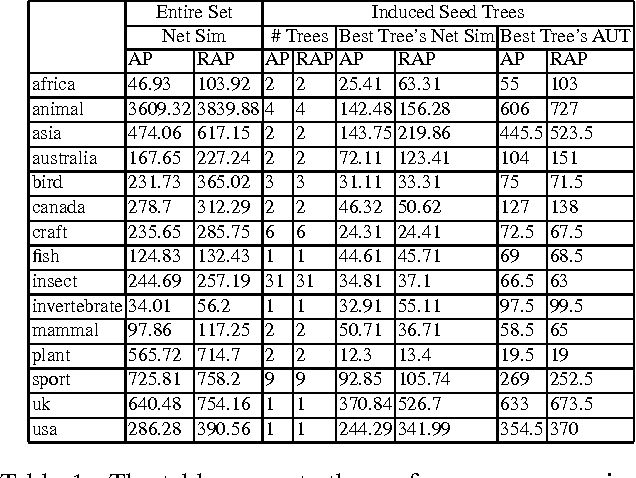
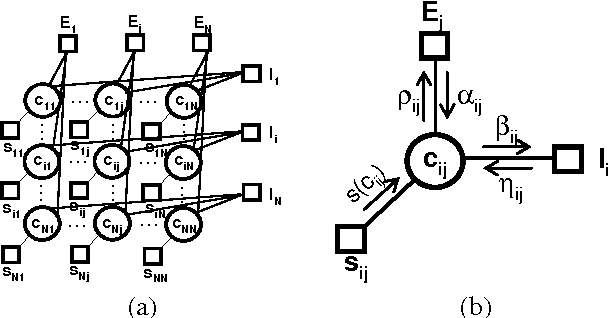
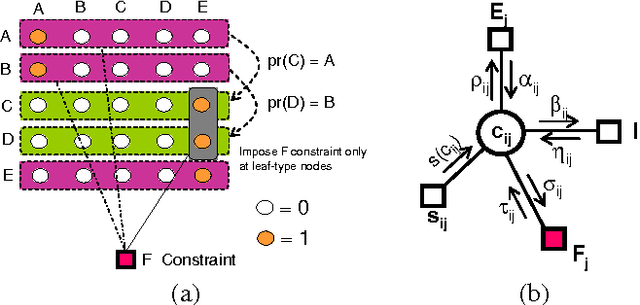
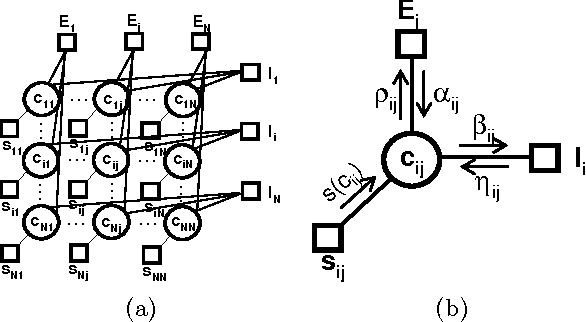
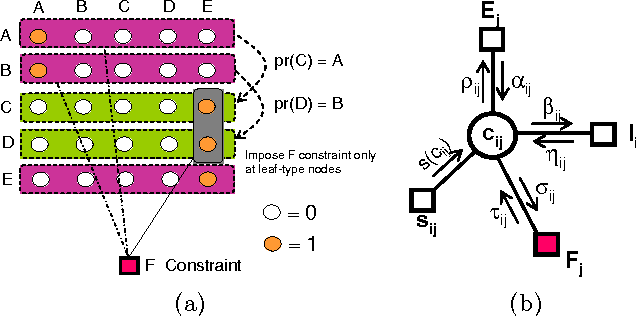
Structured and semi-structured data describing entities, taxonomies and ontologies appears in many domains. There is a huge interest in integrating structured information from multiple sources; however integrating structured data to infer complex common structures is a difficult task because the integration must aggregate similar structures while avoiding structural inconsistencies that may appear when the data is combined. In this work, we study the integration of structured social metadata: shallow personal hierarchies specified by many individual users on the SocialWeb, and focus on inferring a collection of integrated, consistent taxonomies. We frame this task as an optimization problem with structural constraints. We propose a new inference algorithm, which we refer to as Relational Affinity Propagation (RAP) that extends affinity propagation (Frey and Dueck 2007) by introducing structural constraints. We validate the approach on a real-world social media dataset, collected from the photosharing website Flickr. Our empirical results show that our proposed approach is able to construct deeper and denser structures compared to an approach using only the standard affinity propagation algorithm.
Modeling Social Annotation: a Bayesian Approach
May 26, 2010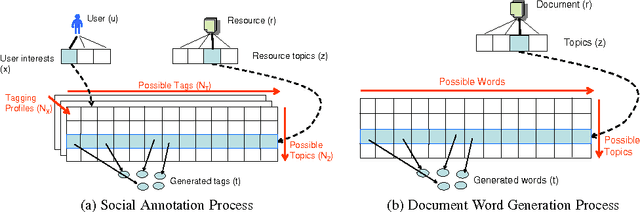
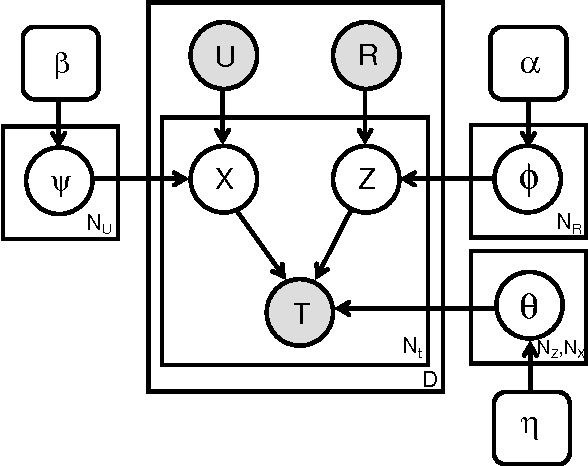
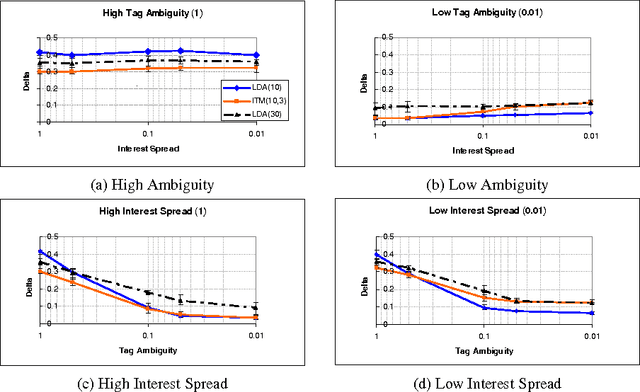
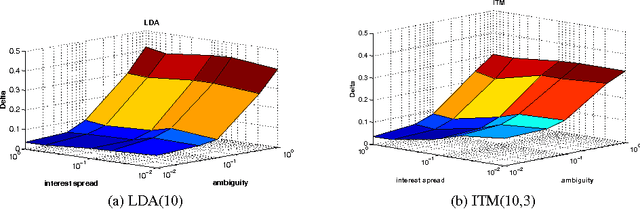
Collaborative tagging systems, such as Delicious, CiteULike, and others, allow users to annotate resources, e.g., Web pages or scientific papers, with descriptive labels called tags. The social annotations contributed by thousands of users, can potentially be used to infer categorical knowledge, classify documents or recommend new relevant information. Traditional text inference methods do not make best use of social annotation, since they do not take into account variations in individual users' perspectives and vocabulary. In a previous work, we introduced a simple probabilistic model that takes interests of individual annotators into account in order to find hidden topics of annotated resources. Unfortunately, that approach had one major shortcoming: the number of topics and interests must be specified a priori. To address this drawback, we extend the model to a fully Bayesian framework, which offers a way to automatically estimate these numbers. In particular, the model allows the number of interests and topics to change as suggested by the structure of the data. We evaluate the proposed model in detail on the synthetic and real-world data by comparing its performance to Latent Dirichlet Allocation on the topic extraction task. For the latter evaluation, we apply the model to infer topics of Web resources from social annotations obtained from Delicious in order to discover new resources similar to a specified one. Our empirical results demonstrate that the proposed model is a promising method for exploiting social knowledge contained in user-generated annotations.
Constructing Folksonomies from User-specified Relations on Flickr
May 24, 2008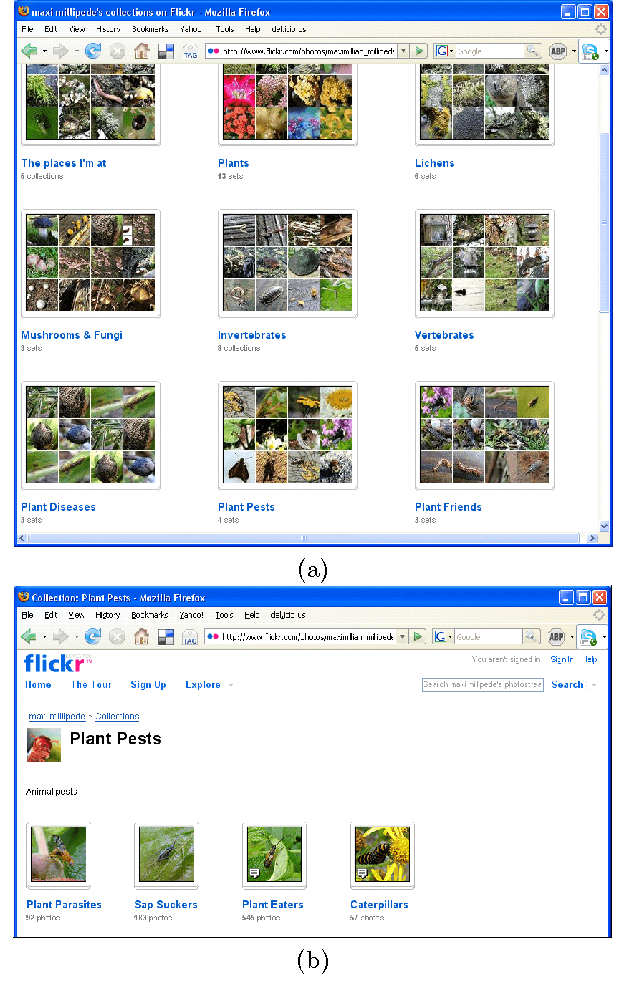
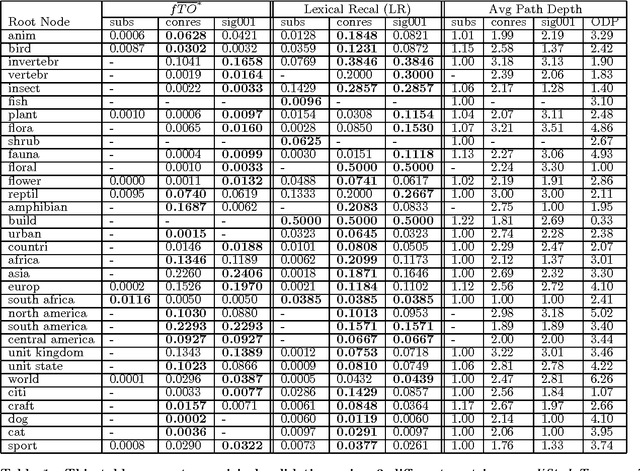
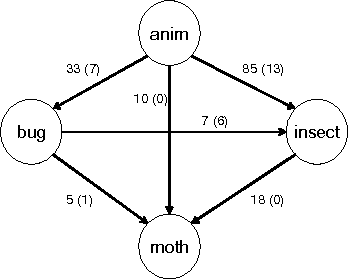
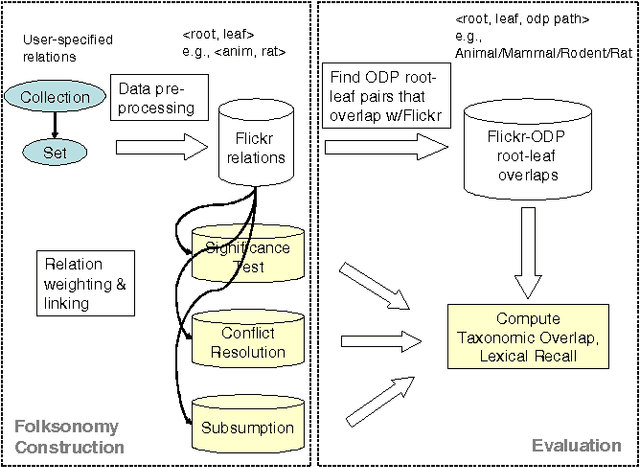
Many social Web sites allow users to publish content and annotate with descriptive metadata. In addition to flat tags, some social Web sites have recently began to allow users to organize their content and metadata hierarchically. The social photosharing site Flickr, for example, allows users to group related photos in sets, and related sets in collections. The social bookmarking site Del.icio.us similarly lets users group related tags into bundles. Although the sites themselves don't impose any constraints on how these hierarchies are used, individuals generally use them to capture relationships between concepts, most commonly the broader/narrower relations. Collective annotation of content with hierarchical relations may lead to an emergent classification system, called a folksonomy. While some researchers have explored using tags as evidence for learning folksonomies, we believe that hierarchical relations described above offer a high-quality source of evidence for this task. We propose a simple approach to aggregate shallow hierarchies created by many distinct Flickr users into a common folksonomy. Our approach uses statistics to determine if a particular relation should be retained or discarded. The relations are then woven together into larger hierarchies. Although we have not carried out a detailed quantitative evaluation of the approach, it looks very promising since it generates very reasonable, non-trivial hierarchies.
Personalizing Image Search Results on Flickr
Apr 12, 2007
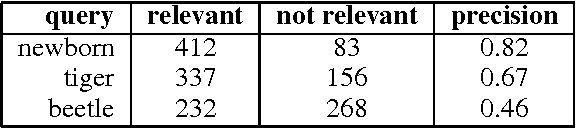
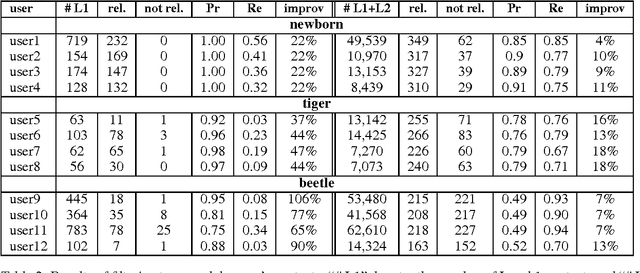
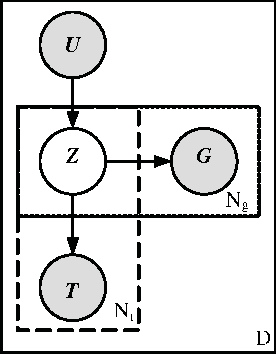
The social media site Flickr allows users to upload their photos, annotate them with tags, submit them to groups, and also to form social networks by adding other users as contacts. Flickr offers multiple ways of browsing or searching it. One option is tag search, which returns all images tagged with a specific keyword. If the keyword is ambiguous, e.g., ``beetle'' could mean an insect or a car, tag search results will include many images that are not relevant to the sense the user had in mind when executing the query. We claim that users express their photography interests through the metadata they add in the form of contacts and image annotations. We show how to exploit this metadata to personalize search results for the user, thereby improving search performance. First, we show that we can significantly improve search precision by filtering tag search results by user's contacts or a larger social network that includes those contact's contacts. Secondly, we describe a probabilistic model that takes advantage of tag information to discover latent topics contained in the search results. The users' interests can similarly be described by the tags they used for annotating their images. The latent topics found by the model are then used to personalize search results by finding images on topics that are of interest to the user.
Exploiting Social Annotation for Automatic Resource Discovery
Apr 12, 2007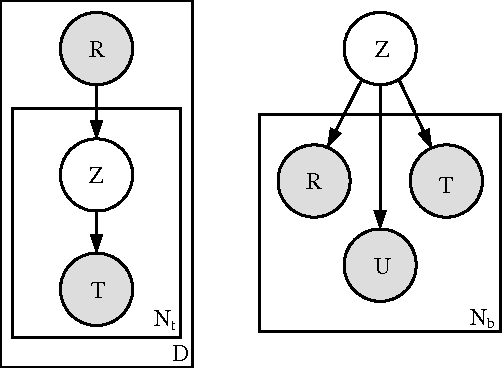

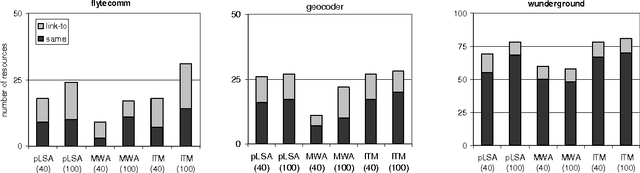
Information integration applications, such as mediators or mashups, that require access to information resources currently rely on users manually discovering and integrating them in the application. Manual resource discovery is a slow process, requiring the user to sift through results obtained via keyword-based search. Although search methods have advanced to include evidence from document contents, its metadata and the contents and link structure of the referring pages, they still do not adequately cover information sources -- often called ``the hidden Web''-- that dynamically generate documents in response to a query. The recently popular social bookmarking sites, which allow users to annotate and share metadata about various information sources, provide rich evidence for resource discovery. In this paper, we describe a probabilistic model of the user annotation process in a social bookmarking system del.icio.us. We then use the model to automatically find resources relevant to a particular information domain. Our experimental results on data obtained from \emph{del.icio.us} show this approach as a promising method for helping automate the resource discovery task.