 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework for inferring empirical causal graphs from binary data to support multidimensional poverty analysis
May 12, 2022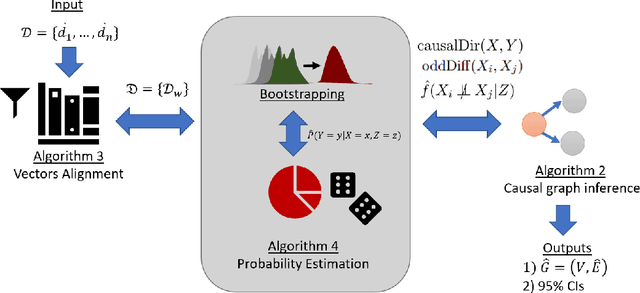

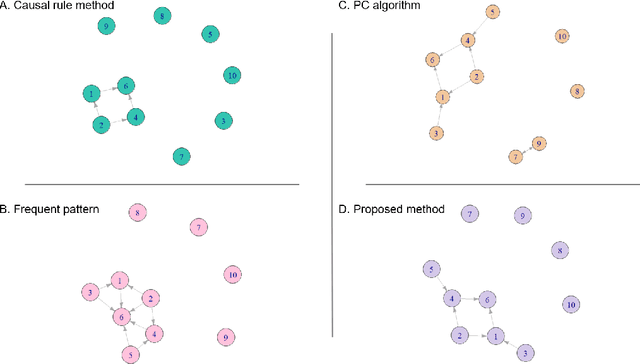

Poverty is one of the fundamental issues that mankind faces. Multidimensional Poverty Index (MPI) is deployed for measuring poverty issues in a population beyond monetary. However, MPI cannot provide information regarding associations and causal relations among poverty factors. Does education cause income inequality in a specific region? Is lacking education a cause of health issues? By not knowing causal relations, policy maker cannot pinpoint root causes of poverty issues of a specific population, which might not be the same across different population. Additionally, MPI requires binary data, which cannot be analyzed by most of causal inference frameworks. In this work, we proposed an exploratory-data-analysis framework for finding possible causal relations with confidence intervals among binary data. The proposed framework provides not only how severe the issue of poverty is, but it also provides the causal relations among poverty factors. Moreover, knowing a confidence interval of degree of causal direction lets us know how strong a causal relation is. We evaluated the proposed framework with several baseline approaches in simulation datasets as well as using two real-world datasets as case studies 1) Twin births of the United States: the relation between birth weight and mortality of twin, and 2) Thailand population surveys from 378k households of Chiang Mai and 353k households of Khon Kaen provinces. Our framework performed better than baselines in most cases. The first case study reveals almost all mortality cases in twins have issues of low birth weights but not all low-birth-weight twins were died. The second case study reveals that smoking associates with drinking alcohol in both provinces and there is a causal relation of smoking causes drinking alcohol in only Chiang Mai province. The framework can be applied beyond the poverty context.
A nonparametric framework for inferring orders of categorical data from category-real ordered pairs
Nov 15, 2019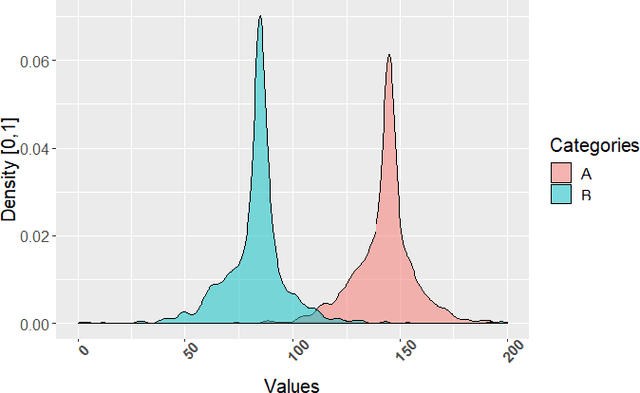
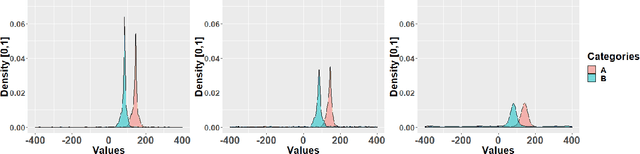
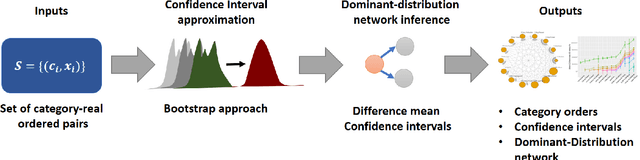
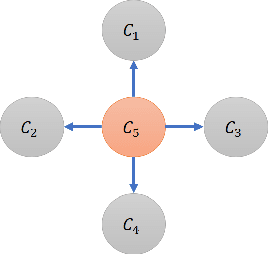
Given a dataset of careers and incomes, how large a difference of income between any pair of careers would be? Given a dataset of travel time records, how long do we need to spend more when choosing a public transportation mode $A$ instead of $B$ to travel? In this paper, we propose a framework that is able to infer orders of categories as well as magnitudes of difference of real numbers between each pair of categories using Estimation statistics framework. Not only reporting whether an order of categories exists, but our framework also reports the magnitude of difference of each consecutive pairs of categories in the order. In large dataset, our framework is scalable well compared with the existing framework. The proposed framework has been applied to two real-world case studies: 1) ordering careers by incomes based on information of 350,000 households living in Khon Kaen province, Thailand, and 2) ordering sectors by closing prices based on 1060 companies' closing prices of NASDAQ stock markets between years 2000 and 2016. The results of careers ordering show income inequality among different careers. The stock market results illustrate dynamics of sector domination that can change over time. Our approach is able to be applied in any research area that has category-real ordered pairs. Our proposed "Dominant-Distribution Network" provides a novel approach to gain new insight of analyzing category orders. The software of this framework is available for researchers or practitioners within R package: EDOIF.
Identifying Linear Models in Multi-Resolution Population Data using Minimum Description Length Principle to Predict Household Income
Jul 10, 2019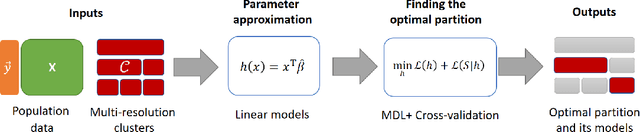
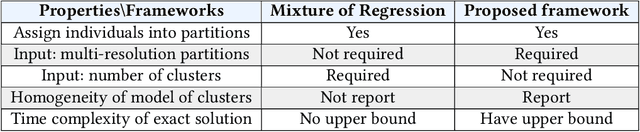
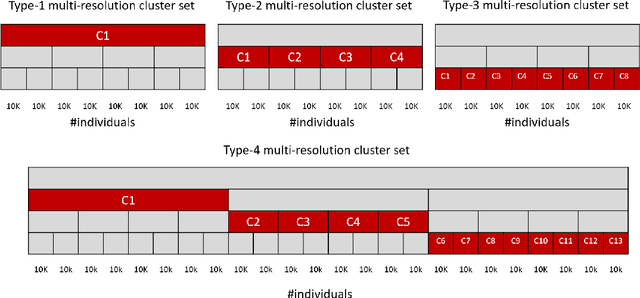

One shirt size cannot fit everybody, while we cannot make a unique shirt that fits perfectly for everyone because of resource limitation. This analogy is true for the policy making. Policy makers cannot establish a single policy to solve all problems for all regions because each region has its own unique issue. In the other extreme, policy makers also cannot create a policy for each small village due to the resource limitation. Would it be better if we can find a set of largest regions such that the population of each region within this set has common issues and we can establish a single policy for them? In this work, we propose a framework using regression analysis and minimum description length (MDL) to find a set of largest areas that have common indicators, which can be used to predict household incomes efficiently. Given a set of household features, and a multi-resolution partition that represents administrative divisions, our framework reports a set C* of largest subdivisions that have a common model for population-income prediction. We formalize a problem of finding C* and propose the algorithm as a solution. We use both simulation datasets as well as a real-world dataset of Thailand's population household information to demonstrate our framework performance and application. The results show that our framework performance is better than the baseline methods. We show the results of our method can be used to find indicators of income prediction for many areas in Thailand. By increasing these indicator values, we expect people in these areas to gain more incomes. Hence, the policy makers can plan to establish the policies by using these indicators in our results as a guideline to solve low-income issues. Our framework can be used to support policy makers to establish policies regarding any other dependent variable beyond incomes in order to combat poverty and other issues.