 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Linear Models in Multi-Resolution Population Data using Minimum Description Length Principle to Predict Household Income
Paper and Code
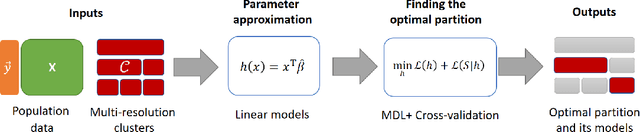
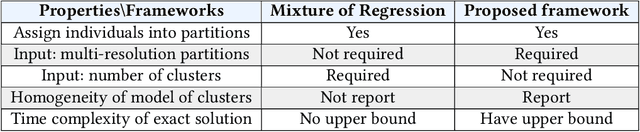
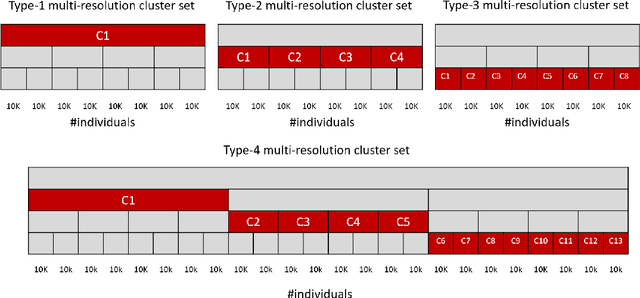

One shirt size cannot fit everybody, while we cannot make a unique shirt that fits perfectly for everyone because of resource limitation. This analogy is true for the policy making. Policy makers cannot establish a single policy to solve all problems for all regions because each region has its own unique issue. In the other extreme, policy makers also cannot create a policy for each small village due to the resource limitation. Would it be better if we can find a set of largest regions such that the population of each region within this set has common issues and we can establish a single policy for them? In this work, we propose a framework using regression analysis and minimum description length (MDL) to find a set of largest areas that have common indicators, which can be used to predict household incomes efficiently. Given a set of household features, and a multi-resolution partition that represents administrative divisions, our framework reports a set C* of largest subdivisions that have a common model for population-income prediction. We formalize a problem of finding C* and propose the algorithm as a solution. We use both simulation datasets as well as a real-world dataset of Thailand's population household information to demonstrate our framework performance and application. The results show that our framework performance is better than the baseline methods. We show the results of our method can be used to find indicators of income prediction for many areas in Thailand. By increasing these indicator values, we expect people in these areas to gain more incomes. Hence, the policy makers can plan to establish the policies by using these indicators in our results as a guideline to solve low-income issues. Our framework can be used to support policy makers to establish policies regarding any other dependent variable beyond incomes in order to combat poverty and other issues.