 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Social Annotation: a Bayesian Approach
Paper and Code
May 26, 2010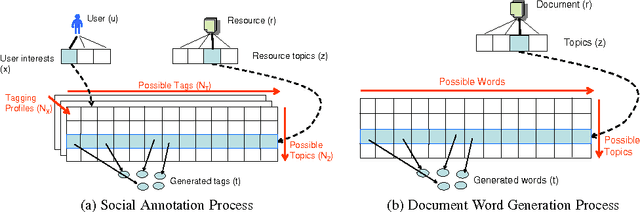
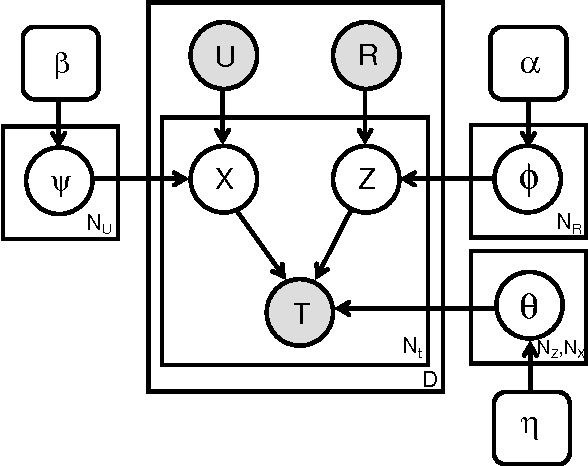
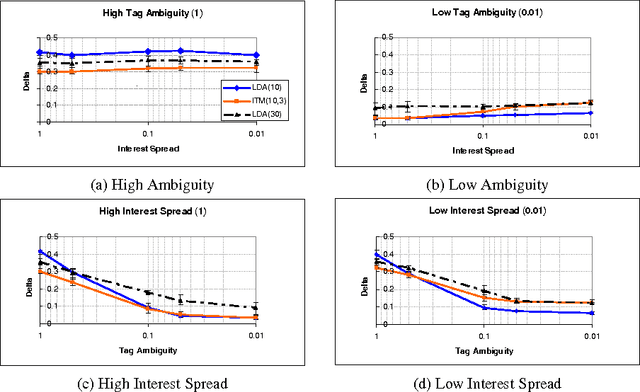
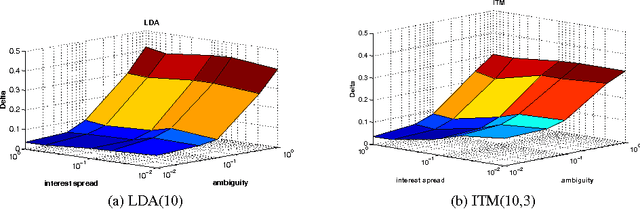
Collaborative tagging systems, such as Delicious, CiteULike, and others, allow users to annotate resources, e.g., Web pages or scientific papers, with descriptive labels called tags. The social annotations contributed by thousands of users, can potentially be used to infer categorical knowledge, classify documents or recommend new relevant information. Traditional text inference methods do not make best use of social annotation, since they do not take into account variations in individual users' perspectives and vocabulary. In a previous work, we introduced a simple probabilistic model that takes interests of individual annotators into account in order to find hidden topics of annotated resources. Unfortunately, that approach had one major shortcoming: the number of topics and interests must be specified a priori. To address this drawback, we extend the model to a fully Bayesian framework, which offers a way to automatically estimate these numbers. In particular, the model allows the number of interests and topics to change as suggested by the structure of the data. We evaluate the proposed model in detail on the synthetic and real-world data by comparing its performance to Latent Dirichlet Allocation on the topic extraction task. For the latter evaluation, we apply the model to infer topics of Web resources from social annotations obtained from Delicious in order to discover new resources similar to a specified one. Our empirical results demonstrate that the proposed model is a promising method for exploiting social knowledge contained in user-generated annotations.