 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Social Annotation for Automatic Resource Discovery
Paper and Code
Apr 12, 2007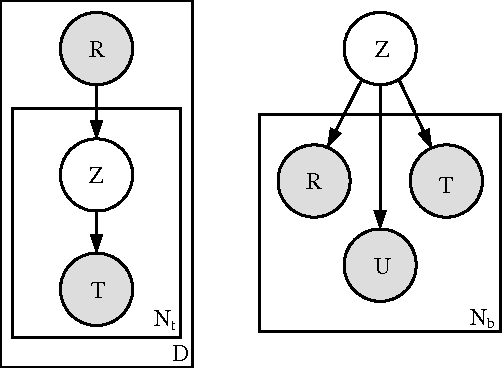

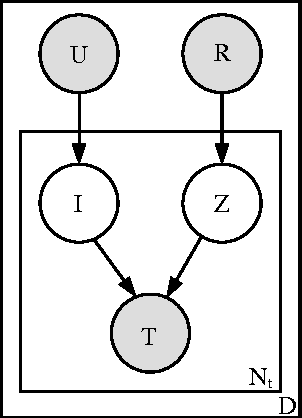
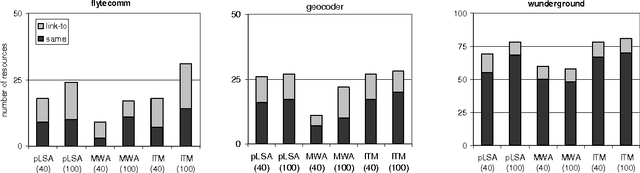
Information integration applications, such as mediators or mashups, that require access to information resources currently rely on users manually discovering and integrating them in the application. Manual resource discovery is a slow process, requiring the user to sift through results obtained via keyword-based search. Although search methods have advanced to include evidence from document contents, its metadata and the contents and link structure of the referring pages, they still do not adequately cover information sources -- often called ``the hidden Web''-- that dynamically generate documents in response to a query. The recently popular social bookmarking sites, which allow users to annotate and share metadata about various information sources, provide rich evidence for resource discovery. In this paper, we describe a probabilistic model of the user annotation process in a social bookmarking system del.icio.us. We then use the model to automatically find resources relevant to a particular information domain. Our experimental results on data obtained from \emph{del.icio.us} show this approach as a promising method for helping automate the resource discovery task.