 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Convolutional Features for Music Audio Modeling
May 31, 2021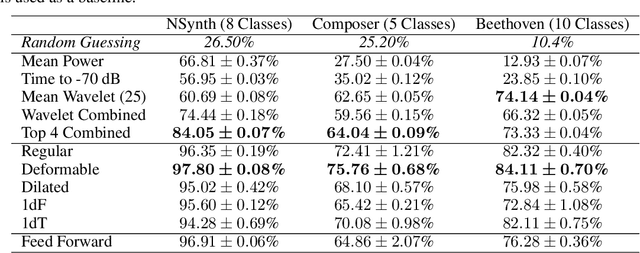
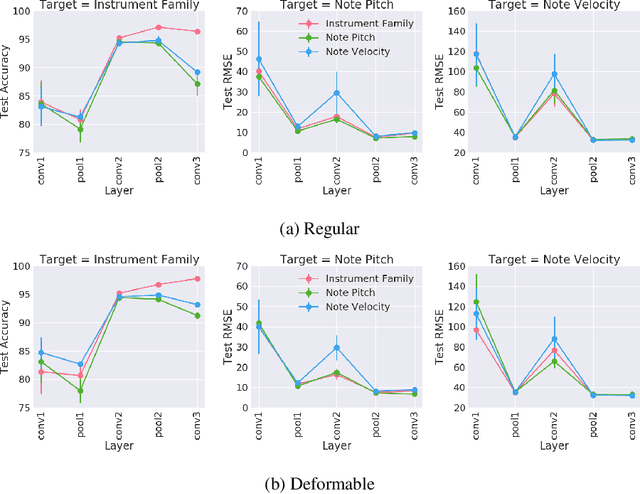

Audio signals are often represented as spectrograms and treated as 2D images. In this light, deep convolutional architectures are widely used for music audio tasks even though these two data types have very different structures. In this work, we attempt to "open the black-box" on deep convolutional models to inform future architectures for music audio tasks, and explain the excellent performance of deep convolutions that model spectrograms as 2D images. To this end, we expand recent explainability discussions in deep learning for natural image data to music audio data through systematic experiments using the deep features learned by various convolutional architectures. We demonstrate that deep convolutional features perform well across various target tasks, whether or not they are extracted from deep architectures originally trained on that task. Additionally, deep features exhibit high similarity to hand-crafted wavelet features, whether the deep features are extracted from a trained or untrained model.
Stanza: A Nonlinear State Space Model for Probabilistic Inference in Non-Stationary Time Series
Jun 11, 2020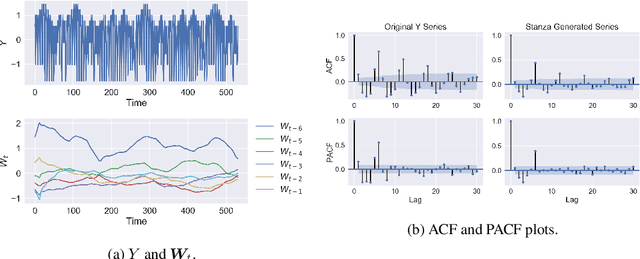
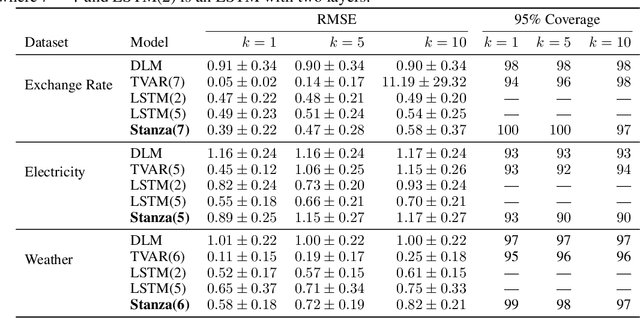
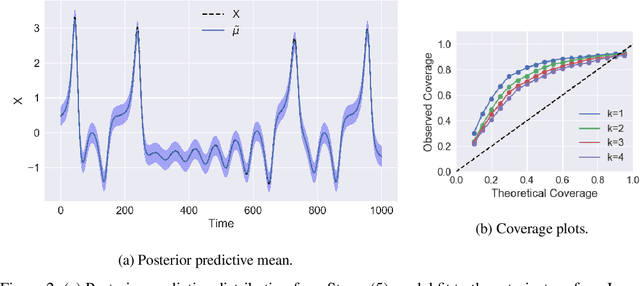
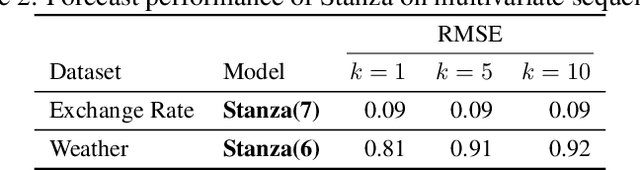
Time series with long-term structure arise in a variety of contexts and capturing this temporal structure is a critical challenge in time series analysis for both inference and forecasting settings. Traditionally, state space models have been successful in providing uncertainty estimates of trajectories in the latent space. More recently, deep learning, attention-based approaches have achieved state of the art performance for sequence modeling, though often require large amounts of data and parameters to do so. We propose Stanza, a nonlinear, non-stationary state space model as an intermediate approach to fill the gap between traditional models and modern deep learning approaches for complex time series. Stanza strikes a balance between competitive forecasting accuracy and probabilistic, interpretable inference for highly structured time series. In particular, Stanza achieves forecasting accuracy competitive with deep LSTMs on real-world datasets, especially for multi-step ahead forecasting.
Predicting Exploitation of Disclosed Software Vulnerabilities Using Open-source Data
Jul 25, 2017
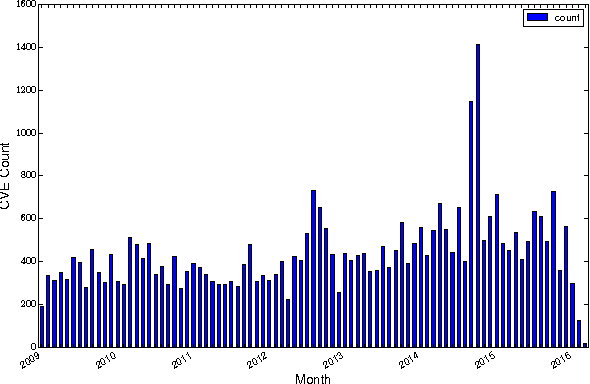
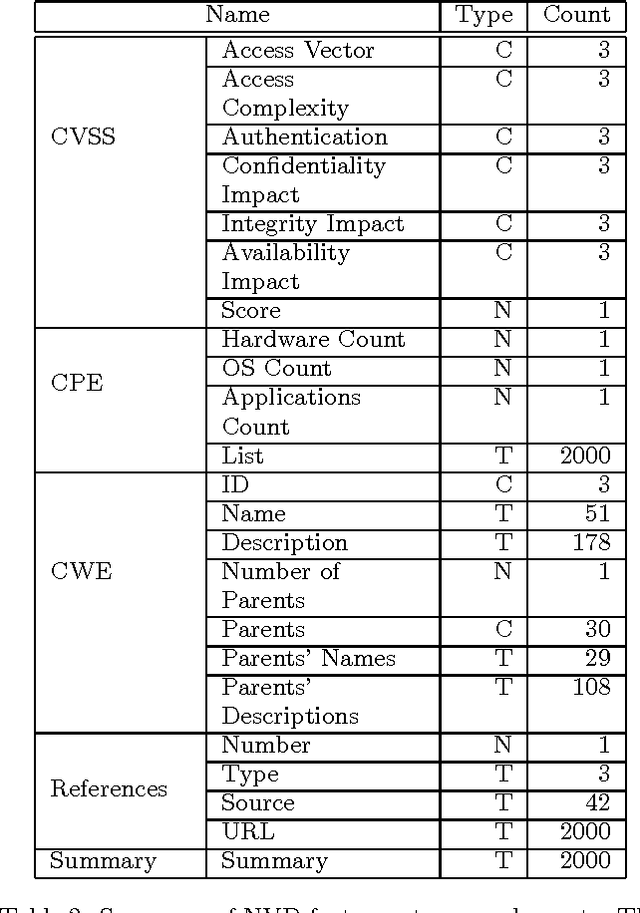
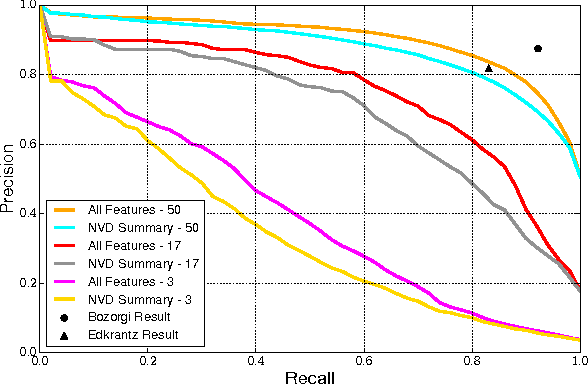
Each year, thousands of software vulnerabilities are discovered and reported to the public. Unpatched known vulnerabilities are a significant security risk. It is imperative that software vendors quickly provide patches once vulnerabilities are known and users quickly install those patches as soon as they are available. However, most vulnerabilities are never actually exploited. Since writing, testing, and installing software patches can involve considerable resources, it would be desirable to prioritize the remediation of vulnerabilities that are likely to be exploited. Several published research studies have reported moderate success in applying machine learning techniques to the task of predicting whether a vulnerability will be exploited. These approaches typically use features derived from vulnerability databases (such as the summary text describing the vulnerability) or social media posts that mention the vulnerability by name. However, these prior studies share multiple methodological shortcomings that inflate predictive power of these approaches. We replicate key portions of the prior work, compare their approaches, and show how selection of training and test data critically affect the estimated performance of predictive models. The results of this study point to important methodological considerations that should be taken into account so that results reflect real-world utility.